Relevant Architectural Views
Software Architecture deals with abstraction, (de)composition, style and aesthetics1. In order to describe the architecture of Ansible, we use a model composed of multiple views. Views can be seen as perspectives of an architecture. To be able to properly display the architecture of a system, Kruchten came up with 5 different views. We use this so-called “4+1”-view model to give more insight into Ansible. In the next subsections we will cover each view in more detail.
The Logical View
This view is closely related to the structure of classes and how they interact with one another. The logical view is not meant to be a detailed visualization of the structure and interaction of all classes and objects, but is rather meant to give an overview of the key abstractions that are made in order for the system to fulfill its primary functional requirements. Ansible is written in Python and after inspection it is clear that developers consistently make use of Python classes and inheritance to apply abstraction. This makes the logical view a very prominent view.
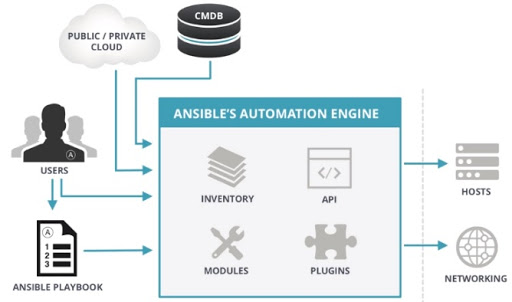
The figure above2 shows what the logical view of Ansible is. As explained in our previous post, Ansible is agentless. This means that there is just one node, the control/user node, and no other software is needed to be installed on remote machines to make them manageable3. Moreover, it has a push-based architecture which means that the control node only has to write down configurations (also knows as Playbooks) written in YAML and push them to the host machines through SSH.
Process View
The process view visualizes the general program flow. The process view illustrates the chronological order of tasks that a system can run. This gives the reader an idea of the dependencies between different processes and also whether certain processes are synchronous or asynchronous. There are many different kinds of processes the consumer may want to use that are (not) reliant on each other. In general, there is a large variety of processes that can be run. The dependencies depend on the tasks. Moreover, Ansible can decide on the fly whether some processes can be run asynchronous or not. Ansible is also intelligent in the sense that if a certain task has already been implemented, then Ansible simply ignores and removes them to limit overkill. This all makes the designing of such a process view difficult, because it really depends on what the user aims to achieve.
Once Ansible is installed on the control node, the user will typically need two types of configuration files: Host Inventory and Playbook. The Host Inventory contains the IP-addresses of the host machines that a user wants to manage. Inventories can be static or dynamic, or even a combination of them, and Ansible is not limited to a single inventory4. Playbooks contain plays and plays contain tasks. Tasks make use of different (combinatory) modules that need to be executed on the host machines. Tasks are made up of a name, a module reference, module arguments, and task control keywords4. In order to execute the task, SSH connections with the remote host are created. The first connection creates a temporary directory and is then closed. The second connection is opened to write out the task object from memory into a file within the temporary directory that was just created. After this is closed, Ansible opens a third connection to execute the module and afterwards delete the temporary directory and all its contents. Once the task is executed, the results are captured in JSON format, which Ansible will parse and handle appropriately. This is useful, because its users can trace back what happened in case of problems. If a task has an asynchronous control, Ansible will close the third connection before the module is complete, and SSH back in to the host to check the status of the task after a prescribed period until the module is complete or a prescribed timeout has been reached.
Development View
The development view visualizes how the system is divided into packages or modules. Connectors show how the modules depend on each other. This facilitates the allocation of work teams and in agreement with Conway’s law, also the organizational structure. The importance of this view becomes apparent when one realizes that this project has thousands of contributors. The modularity of the system limits the overhead for contributors and maintainers since changes in one module of the software have a very limited effect on the rest of the system.
Most of the work Ansible does is contained in Modules. These are independent reusable scripts that can be pushed to managed nodes to accomplish some task. Any code that would be used in multiple modules can be found in a Module Utility5. Together with plugins, inventory, and playbooks they form the core of Ansible, which can be seen in the source code as well. A simple overview of the core components of Ansible can be seen in the following diagram.
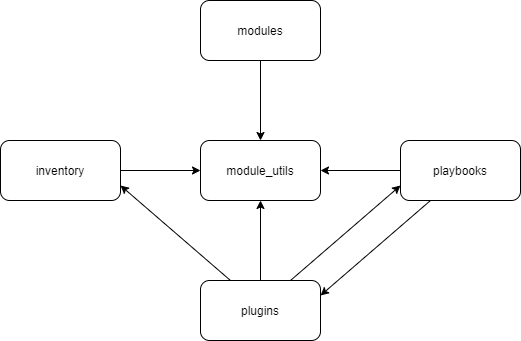
The largest part of Ansible actually resides in the modules folder. Since there are a lot of modules, they are not included in the diagram. Most of the development for Ansible happens here.
Contributing to Ansible
Through the docs of Ansible a lot of coding standards are communicated to the developers, such as where to place certain modules in the system structure, as well as naming conventions which can be found here.
Testing
Developers are expected to test their code and show this in their PR, which will make it more likely that their code will be reviewed and merged. Tests are written in pytest.
Physical View
This view focuses on the mapping between software and hardware. For Ansible to be flexible it needs to be able to map its tasks to a wide variety of host systems. Some of these systems are their own abstraction on top of hardware, like the cloud systems on AWS. The overlap between all these cases do not make for an interesting view; Ansible simply moves to the target device(s), performs it’s tasks and then cleans up after itself.
Deployment view
Ansible at its core involves two or more machines. One control node and a set of one or more managed nodes 6.
The control node can be any machine that runs Python 2 or 3, except for Windows machines. 7 A windows machine can still be used if Windows Subsystem for Linux is available 8. Ansible must be installed on this machine, which can be done using most package managers. Alternatively it can be installed through pip.
The managed nodes can be any machine that runs Windows, Linux or BSD, has a Python environment and provides SSH access9 10. Other connection methods are available via plugins. This includes both remote access methods such as unix sockets, kubernetes pods and http(s) as well as various local methods such as chroot environments, lxc containers and BSD jails11.
Scenarios
The scenarios are a combination of the previous four views, making it redundant, but still very useful. The scenarios can be used during prototyping and evaluation. Scenarios can be easily deduced from use cases and can also be used as a way to validate the system. Since Ansible has a set of very distinct use cases, the scenarios are a relevant part of the views. However, for Ansible, there are too many possible scenarios and they can not be ordered in level of importance. It really depends on whether a user wants to deploy, configure or orchestrate. More concretely, Ansible has over 750 modules that can be imported in Playbooks12. Ansible is therefore too flexible and large to capture most important scenarios.
Non-functional properties, and how potential trade-offs between them have been resolved.
Ansible has a number of different use cases, and therefore different requirements per use case. There is however overlap. The most important non-functional-requirement is the declarative nature of Ansible.
Declarative programming means that the developer only writes down how it wants the final state of the system to be. This is in contrast to the way developers and system administrators have to perform tasks without Ansible. For every different kind of system a developer would need to write different code to get a similar application running, i.e. the developer has to specify all steps that a certain system needs to take to make an application running and these steps differ per system.
In summary, the trade-offs made between declarative and imperative programming is that the declarative offers ease-of-use and consistency through automation, while imperative programming offers more control to the developer. Ansible is strictly declarative.
-
https://www.cs.ubc.ca/~gregor/teaching/papers/4+1view-architecture.pdf ↩
-
http://www.findoutthat.com/ansible-architecture/ ↩
-
https://www.ansible.com/hubfs/pdfs/Benefits-of-Agentless-WhitePaper.pdf ↩
-
https://www.ansible.com/hubfs/-2016-ebooks/Packt_-_Mastering_Ansible_-_Excerpt.pdf ↩ ↩2
-
https://docs.ansible.com/ansible/latest/dev_guide/overview_architecture.html ↩
-
https://docs.ansible.com/ansible/latest/network/getting_started/basic_concepts.html ↩
-
https://docs.ansible.com/ansible/latest/installation_guide/intro_installation.html#control-node-requirements ↩
-
https://www.jeffgeerling.com/blog/2017/using-ansible-through-windows-10s-subsystem-linux ↩
-
https://docs.ansible.com/ansible/latest/installation_guide/intro_installation.html#managed-node-requirements ↩
-
https://docs.ansible.com/ansible/latest/user_guide/connection_details.html# ↩
-
https://docs.ansible.com/ansible/latest/plugins/connection.html#plugin-list ↩
-
https://docs.ansible.com/ansible/latest/modules/list_of_all_modules.html ↩