Delft Students on Software Architecture
A blog on the architecture of open source software systems written by students from Delft University of Technology
Putting Sentry into Context
Imagine you created a nice application for other people to use. Your product is gaining traction, new users start flowing in and you start earning some money. Life is great and you decide to roll out a big update you have been working on. But after a few days of the release, engagement rates and sales seem to drop and you are not sure why: all of your automated tests pass and you have extensively tried your app on your machine. A little panicked, you start investigating. You are still very lost when an email comes in: a kind user took the effort to submit a bug report! The bug report is very vague, but at least you have a sense of what is happening. You finally find the culprit after another day of work: three lines of code in the backend that caused unexpected behavior in the frontend. Almost a week later, you fixed the issue and users are slowly returning to your app.
The great Gatsby and its vision
This post is the first of a four-part series in which we will explore Gatsby from a software architectural perspective. As the core team knows Gatsby best, let’s start with their take on it:
The Architecture Powering Sentry
In the last essay we gave an overview of Sentry and its context. We discussed topics like Sentry’s key capabilities, stakeholders and relationships with its environment. But that essay also serves as a stepping stone to the topic of this essay: the architecture behind Sentry. Architecture of software can be viewed from multiple perspectives, as has for example been described by Rozanski and Woods. Guess what? The last essay already covered two architectural viewpoints, namely the contextual and functional viewpoints! In this essay, we will take a Snuba dive into some more technical architectural viewpoints: development, deployment and runtime.
Micronaut - From Vision to architecture
As described in the previous blogpost, Micronaut is a framework that provides many different functionalities and tools to build a Microservice application. This blogpost describes, therefore, how all these different functionalities are organized and which patterns are implemented to provide the best experience for a user developing an application.
Can Next.js Stay Ahead: A Case of Quality Control
Two weeks ago, we took a stab at exploring and identifying the architectural elements and principles that underlie Next.js, a modern web framework for building React applications. Together these elements and principles realize the set of fundamental concepts and properties that form Next.js in its environment. If you haven’t done so yet, make sure to also read our first post on the vision of Next.js, in which we go more into depth into the foundations of its architecture.
How even a single product can vary
In previous posts, we focused on the business, technical and quality side of openpilot. Today it’s time to zoom in on some different aspect that might not be the first thing that pops into your mind when thinking about the architecture of a software product: Variability! Now you might think, variability is everywhere or variability is unavoidable. In the world of software, both are true! This post will be dedicated to defining, identifying and coping with variability from an architectural point of view. We will do this by identifying the aspects of the software that are susceptible for variability and how individual components relate to each other. Subsequently we will look at the meta-side of variability and which effects it has on those concerned. Finally, we will have a look at openpilot’s strategy for managing variability.
Plotting Bokeh, an Analysis of its Quality
Testing is the key to success. Quality is never an accident. All code is guilty, until proven innocent. Folk knowledge in Software Engineering is full of sayings like these ones. Nevertheless, we still live in a world where code quality is most of the times undervalued. The importance of testing, refactoring and evaluating technical debt should however not be neglected, since they are of major importance to safeguard code quality and architectural integrity.
NumPy: Carefully Crafting Components through Collaboration
In this fourth and final essay of our series on the NumPy project we will combine two very important aspects of developing a (software) product: the technological aspect and the social aspect. As an architecture is designed, developed and built-upon by humans, the social side of the process should not be overlooked. Conway’s Law will play a central role in this techno-social analysis of the NumPy project.
Contributor Workflow - an optimization analysis
We’re back one extra and final time to explain our experience on working with mypy as an open-source project in hind-sight. Lucky you!
Something really interesting happened, while we contributed some functional and documentation-related features to this python typechecking library. We’ve setup our own workflow, we went through the process of understanding not only the library, but also it’s environment and testing system (CI), and now we’ve got something quite interesting to tell you about what we think mypy can improve on!
On OpenRCT2’s Frontlines
In the previous essays we have analyzed OpenRCT2’s architecture, but who can give better insights than OpenRCT2’s developers themselves? We have asked the OpenRCT2’s developers questions relating to OpenRCT2’s architecture, the project itself and their experiences while developing for it.
Solidity and its variability
This is the fourth and the last essay on the Solidity project. It covers an analysis on the variability of the Solidity compiler. Like most compilers, Solidity allows a lot of command line arguments that alter the expected input and output files and the expected command line arguments themselves. Because in the first place we are talking about a compiler, and in the second place security plays a crucial role in the project, it is rather important that the process and the output is trustworthy in all possible variances. This is why we decided that a variability analysis would be an interesting final vision on the Solidity project.
Exploring the Atmosphere: the variability of Meteor
Two posts ago, we discussed Meteor’s architecture and its separation into two parts: the Meteor Tool and Meteor Packages. We explained that Meteor’s core functionality is distributed across different, standalone (and sometimes interdependent) packages. There are a number of different packages created by Meteor itself, such as packages for Meteor’s account system or packages for Meteor’s reactivity and connection to MongoDB. There is also the option of third-party packages designed for Meteor, hosted on a platform called Atmosphere.
Dependencies and Modular Software Design
Research shows that work dependencies – i.e., engineering decisions constraining other engineering decisions – is a fundamental challenge in software development organizations, especially those that are geographically distributed.
How does scikit-learn balance usability with variability?
tags: Scikit-learn Python Software Architecture Machine Learning Developers Configurability Variability Usability Features
So far we have covered many aspects of scikit-learn from a software architectural perspective. In our first essay , we described the vision behind scikit-learn. In the second essay , we described how this vision translates to an architecture. Then, in our last essay , we investigated how scikit-learn safeguards its quality as an open-source system.
Here To Stay : How Ripple Achieves Sustainable Development
The following essay details different approaches taken by Ripple to attain progress that not only satisfies the stakeholders but is also sustainable. The article examines Ripple’s strategies that make sure that they achieve environmental, economic, societal, and technical development without compromising the ability of future generations to meet their needs.
Towards a greener DevOps lifecycle
This is the last part of our series about the open-source project GitLab. Previously we have talked about the context, the architecture and the quality assurance processes of GitLab. To finish off, in this article we will make a sustainability analysis of both GitLab as the company and as the project. We will assess the supported and used infrastructure, search for features improving energy efficiency and investigate the impact of being an all-remote company. Additionally, we will see how GitLab employees value sustainability for them and the company.
RIOT: The power of variability
After we covered the quality and technical debt of RIOT’s code in our previous post, we will now take a deeper look into RIOT’s variability.
Since RIOT is an OS that is supposed to work with quite a lot of different hardware, and applications using RIOT with all kinds of different modules, there are a lot of options and different features to choose from.
What it comes down to is that RIOT offers variability, and a lot of it. But how it offers this and how it implements this is this post’s topic.
In this post we will look at RIOT’s main features, its variability management and its implementation.
To Gatsby and Beyond!
This is our fourth and final post on Gatsby. The first post introduced Gatsby by explaining its product vision. In the second one, we discussed several architectural views and the third one explored technical debt. This essay will cover another architectural concept influencing Gatsby’s flexibility and maintainability: variability management. Due to Gatsby’s plugin architecture with over 1800 plugins, it has an “infinite” number of different possible configurations. Still, everything works together surprisingly well!
Micronaut - A perfect Microservice framework?
Whereas the previous blogposts focused on the internal architecture view of Micronaut, we decided to change now the perspective in our last blogpost and look at Micronaut through the eyes of a software architect who wants to build a microservice application. Micronaut claims to be “a modern, JVM-based, full-stack framework for building modular, easily testable microservices and serverless applications”. Therefore, we explore how Micronaut solves common challenges when developing microservices.
Varying Material-UI
This is the final part of our four part series on Material-UI. In this post we look at the variability in the project, how this variability is managed and how it is implemented. This is all done to show the range of possibilities in Material-UI. We will then finish with our assessment on how well the variability has been implemented in this project.
Plotting Bokeh, an Analysis of its Collaboration
Product development involves two, fundamental, elements: a technical one and a social one. One can only dream of a successful project when both these components are harmoniously aligned. In previous essays we analysed both elements. We focused specially on Bokeh’s technical side, studying its properties, processes, development, deployment, architecture, code quality and testing. Nevertheless, we also shed some light on the social component, describing the importance of the different groups of individuals involved in the project.
Smoke Signals or secure crypto?
Since Signal’s unique characteristics revolve around security and privacy, we decided to explore these features more in depth for our fourth and final essay. More specifically, we will examine how these characteristics affect various layers of Signal’s architecture. We look into how Signal manages sessions between users and at how Signal encrypts and decrypts incoming messages from a component perspective.
Supporting Every Language: Sentry’s SDKs
No programming language is the same. Different syntaxes, static/dynamic typing, and varying build processes are just a few examples of differences that make it difficult to write a single piece of code that can report errors back to Sentry for all runtimes. Previously we have introduced Sentry, discussed it’s architecture, and its development process. Now we broaden our scope to the ecosystem of SDKs supported by Sentry. We will show how Sentry is able to support many different runtimes and we will take a look at these SDKs that report back to Sentry to see how they work.
Variability Analysis of Ludwig
Software variability is the ability of a software system to be personalized, customized, or configured to suit a user’s needs while still supporting desired properties required for mass production or widespread usage. In the current age of the Internet and Technology, software systems are all-pervasive. Thus, for any software to be effective in today’s market, portability, flexibility, and extensibility are more important than ever before. Therefore, software variability is a crucial aspect of any software system that must be addressed within its structure.
Standardize, Abstract, Overcome: Exploring Variability in ArduPilot
For our last post on ArduPilot, we will be diving into the variability found in the project. We examine aspects like the architectural decisions such as hardware abstraction. A more in-depth analysis of the architecture of ArduPilot can be found in our second post.
ESLint’s variability management
In this last post, we will assess and analyze one of the features that ESLint takes pride in and differentiates itself with compared to competitors, namely the large variability in the system realized through configurations. We will go into what is variable, what benefits this has and how this complex configuration can be managed by users in a sane manner. Lastly, we will look at how this is implemented and finish off with an assessment done by ourselves.
Does Conway’s Law Apply to Ansible?
In this post the structure of Ansible will be analyzed. First the structure of the codebase will be discussed. This will be done on the component-level. The most important components will be brought to attention and their mutual coupling will be touched upon. This will be followed up by an in-depth look at the communication and social structure of the development community of Ansible.
Developing fun
A query for “video game architecture” in the library of the Institute of Electrical and Electronics Engineers delivers 446 results, whereas the query “software architecture” delivers a whopping 83,009 results. Clearly, video game architecture is a less researched aspect of software architecture, even though there are over 2.5 billion people who play video games around the world. In this essay we delve into the world of video game architecture and try to lift the veil of mystery of designing these popular software systems.
MuseScore: Architecting for accessibility and usability
Software can be customized to its users from architecture to the final design. In many different ways, developers can optimize their software for specific users. As mentioned in our first post, the context in which MuseScore operates is based on the usability of the application and the accessibility to the users. The latter was also determined to be functionality that is worthy to be prioritized in trade-offs in our second post.
System and People Collaboration in Docker Compose
Until now, we analyzed Docker Compose from various traditional software engineering dependencies stand points (development view, runtime view, operations view). This does not give us a full perspective of the architectural structure of the project.
Extendibility of Google Test
In this post we’ll discuss the extendibility of Google Test (GT), through the 3 most popular extension of the project from the 7 extension recognised by the project’s github page. They are the following: Google Test Adapter and C2TE, providing a GUI for GT and Cornichon, a DSL parser which can make the process of test creation much easier to less experienced end-users. The post discusses in detail the architectures, the contexts and the quality of the these softwares.
Variability Analysis
In the previous essays we focused on analysing the vision of the Open edX project along with some of its architectural patterns and investigated the overall quality of the system. In this essay we will deepen our analysis by looking into the variability modeling, management and implementation mechanisms that are relevant to Open edX. More specifically, we will build a feature model and determine how variability is managed and implemented in the system we analyse.
The configuration of mypy
The last blog post was quite a difficult story, wasn’t it. In this blog post, we will conclude our mypy investigation series after quite a rollercoaster ride. The final topic will be a bit simpler (but don’t underestimate it). This last blogpost will investigate the configurability of mypy and why we would want to configure it.
Solidity: Solid code or not?
This is the third essay on the Solidity project. This essay is about the code quality of Solidity. It will give an answer to the important question: Is the code of Solidity of solid quality or not, and how it this quality maintained?
Scikit-learn’s plan to safeguard its quality
tags: Scikit-learn Python Software Architecture Machine Learning Developers Code Quality Testing Coverage Contributions
In our previous blog posts , we examined the vision and goals behind scikit-learn and discussed how these elements have been combined into the underlying software architecture. We considered several views and perspectives in which the software product operates and the trade-offs that were made to balance functional requirements with non-functional requirements.
RIOT: Quality and Technical Debt
After covering the architectural basics of RIOT in the previous post, we will now see this affects the development quality. This posts covers the way how testing and assessing code quality is currently covered by RIOT and will also address our view on the code quality and technical debt.
Assessing Ripple
In this essay, we will focus on the means to safeguard the quality and architectural integrity of the underlying system. First, We will overview the software quality characteristics. Then we will look into Ripple’s GitHub repository to see if Ripple is applying any tests to achieve better software quality. Finally, we will discuss the analysis of Ripple’s source code using SIG.
Micronaut - Quality and Technical Debt
In our previous blogpost, we discussed about Micronaut’s architectural patterns and its different views. In the third blogpost of this series, we analyze the quality of Micronaut’s codebase and look into the measures taken to ensure its maintainability.
Comets and commits: the software quality of Meteor
After discussing the vision of Meteor and its architecture, it is now time to look at how its quality and architectural integrity is retained during development.
Reducing noise to improve Signal quality
In this post we will discuss how software quality is maintained and guaranteed in Signal. We’ll go over the use of Continuous Integration, analyse test coverage and explore changes that would improve Signal’s code quality. We conclude by estimating, based on the above, the technical debt in Signal Android.
Staying on the Rails: A Quality Assessment
In our last article, we looked at the architectural decisions made during the development of GitLab. The vision behind most decisions was to enable everybody to contribute. This time, we will look at the different methods used to maintain high-quality standards for a software project where everybody is invited to contribute. Furthermore, we will investigate the project in detail to highlight potential points of improvement.
Quality and Technical Debt
In the previous blog, we zoomed into spaCy through the lens of the architectural views as described by Kruchten. After discussing the product vision and the architecture, it is time to take a look at the quality safeguards and the architectural integrity of the underlying system.
Under the Hood of ArduPilot: Software Quality and Improvements
Having gone through the vision and key architectural aspects of ArduPilot in our previous essays, we will focus in this post on the software quality. Initially we look at the continuous integration and test processes. Then we examine recent coding activities and their alignment with the roadmap. Finally, we assess the code quality and maintainability, as well as the technical debt.
Quality and Technical Debt
We analyze the integration process, code quality, test coverage, and how this is facilitating the roadmap of Compose. Then, we delve a bit deeper into technical debt and refactoring solutions of newer features and the entire system as a whole. Overall, Compose system has an organized and aligned development process with high test coverage. However, there’s much improvement and refactoring needed on the code quality and entanglement itself.
Testing the quality of Google Test
In this post we’ll dive deeper in the quality of Google Test. We will be examining the quality checks and tests the developers put in place to make sure that every update is working and is up to par with the rest of the project. We will also take a look at what is holding the project back, the culture and what they could improve.
Gatsby in Debt
Welcome to the third part of our four-part series on Gatsby. The previous essays can be found here: first, second. For a complete understanding we highly recommend reading those first. In this part we will evaluate technical debt and architectural decisions made. To be able to cover this all we will first take a look at the quality assurance systems Gatsby has in place. We’ll explain what a contributor needs to do to have their pull request successfully merged and what Gatsby does to protect their code quality. When we have in place how pull requests are merged, we will analyze what pull requests have been merged recently, what changes are coming up, and how these changes impact the technical debt and maintainability of Gatsby. This should give a clear understanding of what is going on inside Gatsby. After getting this understanding, we get a bit more formal and dive into absolute quality assessment, analysing results from SIG and BetterCodeHub. In conclusion we will take all evaluated aspects together. If you want to learn more about these topics, this essay is just for you!
Quality and Technical Debt
In the previous essay, we focused on the architecture of the Open edX system. In this essay we will take a look at the quality and technical debt of the Open edX source code. We try to provide examples of coding guidelines and standards that are used by the developers working on the edX project and relate these with the actual code.
Checking the typechecker mypy
Analyzing a system which is usually doing the type-checking analysis for us, feels like we’re suddenly on the other end of the rope. This time, we’ll cover the code quality aspect of the python library mypy and how quality is guaranteed. Read on, if you’d like to know how we think mypy can be improved on an architectural level!
MuseScore: Cost of music
The maintainability of a system can be measured in several different ways. One of these is technical debt, which is a measure used to indicate how much refactoring is necessary within a software project.
Combining quality and collaboration in TensorFlow
As we have seen earlier, TensorFlow is a project of substantial size both in terms of codebase as well as the community surrounding it. With so many people working on such a large application it becomes very hard for anyone to carry a complete view of the entire system in their mind. Developers working on certain semi-isolated parts of the software might introduce modifications that unknowingly impact functionalities elsewhere in the system leading to bugs or even failures. Maintaining a high level of quality becomes an undeniable challenge itself, especially for an open-source project involving countless different contributors. This article will provide you with some insight as to which maintenance methods and tools are being employed by the TensorFlow team to keep their project healthy.
Monitoring Sentry’s Software Quality
Thousands of customers use Sentry for creating better software, but how is the software quality of Sentry itself? In this essay, we will analyze how the quality of Sentry’s underlying code and architecture is safeguarded. The architecture powering Sentry has already been discussed in the last essay (“The Architecture Powering Sentry”), so we recommend you to read that first. Having an understanding of Sentry’s core software architecture, we can take a look at the architecture from yet another perspective by addressing topics like software quality assessment, code quality, and technical debt. This perspective is inspired by the Quality Scenarios and Risks & Technical Debt aspects from the arc42 framework.
Ansible paying off their technical debt
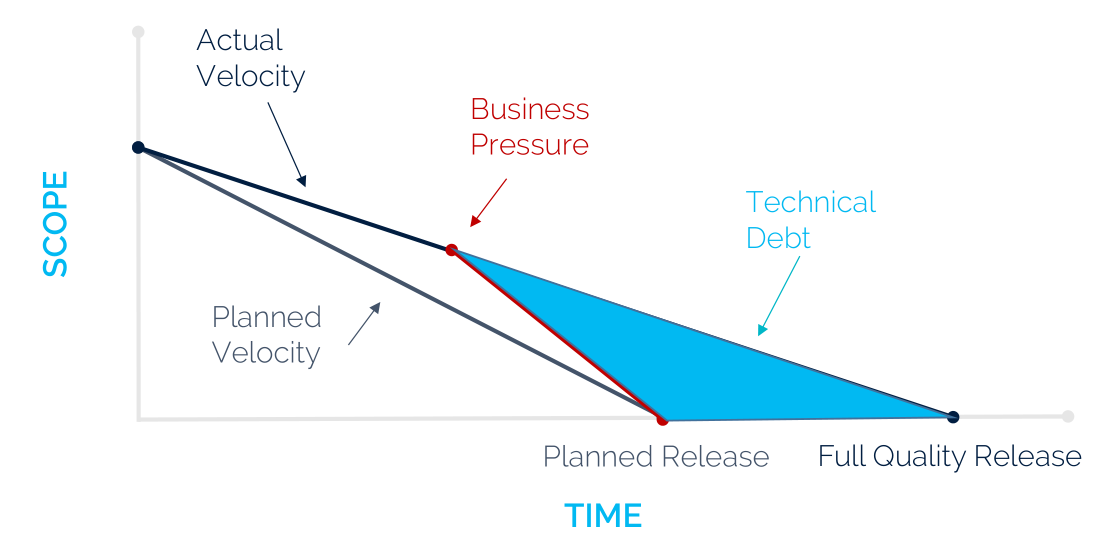
Now that we have discussed Ansible’s architecture, it is time to dive deeper into the implementation details. Like any other software system, Ansible is prone to the build up of deficiencies in internal quality that make it harder than it would ideally be to modify and extend the system. This deficit in quality is often caused by business pressure on the tech team to meet the milestones. This results in quick and dirty solutions to increase the velocity (see figure below). Interestingly, the Ansible core team has been working on decreasing their technical debt, by migrating all the modules to so-called Collections, which will be laid out in more detail in this essay. Similarly, a major refactoring of the code was done in Ansible 2.0 to pay off the technical debt that had accumulated. To analyze the current technical debt of Ansible, we will first examine the development process. Then we give an analysis of the code quality and finally we will discuss how Ansible is planning to deal with this debt in the future milestones.
{kind=link}
Analyzing the Quality of Spyder
Hi folks! We are back again with more insights on your friendly neighborhood Spyder. This time, we are going to focus on how Spyder safeguards the quality and architectural integrity of the underlying system.
Blender’s Variability
This essay will outline how and to what extent Blender is variable. This “software variability is the ability of a software system or artifact to be efficiently extended, changed, customised or configured for use in a particular context”, and this means we will take a look at how many different “instantiations” of Blender are possible, and how these are obtained. We start with identifying these variable components, also referred to as “features”, and modeling those in a feature model.
Blender Behind the Scenes
After having analyzed Blender’s context in the first essay and its codebase architecture in the second, we take a look at the quality of the codebase in this third essay. Because Blender is already over 25 years old, and because of the complicated nature of the functionality it aims to deliver, we initially expect Blender to have a large amount of technical debt — the degree of inaccessibility, or, the number of “deficiencies in internal quality that make it harder than it would ideally be to modify and extend the system further.” In order to ensure a certain code quality, Blender maintains some rules, such as “no code gets in trunk without documentation” (meaning that contributors have to document new functionality in the Blender Documentation), no new warnings are allowed, and code style has to remain consistent within files . Numerous other guidelines can be found at .
Rollercoaster (tycoon) should not crash
I’m sure if you’re reading this, you’ve most likely at one point as a kid thought that being a game tester would be an awesome job. Playing games and getting paid for it, sounds great. However, why do video game developers rely so greatly on players to test their games?
Qualifying Material-UI
The third part of our series will dive into the code to assess the quality of the software. First, we will look at the processes used to guarantee quality in the project and check the quality of the tests used for Material-UI. Then we will connect the roadmap originally described in part 1 of this series to the code.
Ludwig’s Code Quality and Tests
Studying software architecture is a fantastic way to understand the planning behind a system and how it operates. In our previous posts, we illustrated key aspects of Ludwig’s architecture from various perspectives. Now, with this post, we move beyond the building of the system and on to its maintenance and upkeep.
From Vision to Architecture
SpaCy is the brainchild of Matthew Hannibal, who has a background in both Linguistics and Computer Science. After finishing his PhD and further 5 years of research in state-of-the art NLP systems, he decided to leave academia, created SpaCy and started interacting with a wider development community.
RIOT: From Vision to Architecture
In the previous post we discussed what RIOT is, what it tries to be and who it is for. With this in mind we will focus in a more theoretical manner on some Software Architectural aspects of RIOT.
The architecture behind Meteor’s impact
In ‘the vision which makes Meteor shine’, we researched the vision behind Meteor. Now the question is, how was this vision realized? For this, the six architectural views have been described by Rozanski and Woods, namely: concurrency, deployment, development, functional, information and operational. In this blog post, we will be taking a closer look at which ones of these are relevant to Meteor and go more into detail on those which are.
Dissecting Material-UI
In this second part of our series we will consider the overall architecture of Material-UI in-depth. First, we will consider what viewpoints can be used for an in-depth look. Secondly we will consider the main style of the architecture and then we will use that information to consider some viewpoints. Finally we consider the non-functional properties of Material-UI.
Relevant Architectural Views
Docker Compose is a lightweight orchestration tool for deploying multi-container applications on a single host machine; it easy to use for Docker users, and does not require extensive configuration.
Rome wasn’t built in a Signal day
In this post we explore how the concepts discussed in our previous post are realized through Signal’s architectural elements, deployment, and other design principles. We will also see how key features, such as sending a message, work at run-time.
Plotting Bokeh, an Analysis of its Architectural Variables
In order to architect, one must envision. In the last essay we discussed the vision underlying our project. Now we go into further detail in our architectural analysis of Bokeh. We shed some light on the different architectural views that describe Bokeh; we address design choices and patterns applied to this project; and finally we look into its non-functional properties.
What Makes ArduPilot Soar - An Architectural Overview
Having introduced ArduPilot as a whole in our first post, in this second one we look into its components. For ArduPilot, having a sound architecture is important because the software needs to manage various sensors and actuators while operating all kinds of drones like helicopters, planes, rovers, or even submarines. As exemplified by the popular “4+1 View” model of software architecture as well as various academic sources , there are many ways to view the architecture, each with a different focus. In this post we analyze ArduPilot using some of these views. We focus on the different architectural elements of ArduPilot and the connections between them, and the design principles used by the software that allow it to soar.
Test the Architecture with Google Test
Google Test is a relatively small library which is used by many developers, as of March 2020 the project has 805 watching, 14.6k starred and 5.8k forked. The library has many related open source projects as visualized below.
From Words to Actions: How Ripple Gets it done
The following post examines the underlying architecture of Ripple. It is carried out by studying how Ripple realizes the different properties mentioned in the previous essay and the principles of its design and evolution. We will look into the architectural views relevant to Ripple, such as development, run time, and deployment views. Furthermore, we will also discuss the non-functional properties of the system.
When an autonomous car is in the garage
Addressing quality from a software point of view deserves some caution in openpilot’s case. Image yourself as an openpilot software engineer and picture a variety of cars driving around seamlessly and without active human efforts because the code you wrote is good. It sure is an awesome feeling. Now imagine a less cheerfull scene with a car collision, beware that this is not your average lightweight javascript view library, peoples lives depend on it. As the company rightly pointed out, quality is represented by the stability of the cars that are driven by their software (and partially hardware). Therefore assessing quality deserves an unusual integral approach in this non-deterministic context that the code runs in. Think about all the slightly different traffic lights at every corner of the street, think about quaint driving lanes with potholes, think about ludacris other drivers, no situation is the same. An autonomous car is not an ordinary car and a comma two is not an oridnary android device.
Architecture of mypy
Welcome back all! Today we will dive deeper into the architecture of mypy. As this is our second blogpost, we assume that you have some basic knowledge about what mypy is and what you can do with it. If you have no clue what we are talking about, please check our previous blogpost.
From Vision to Architecture
In the previous essay, we focused on the vision of the Open edX system. In this essay, we will focus on the realization of that vision, visible in the architecture of the Open edX system.
Solidity: From vision to architecture
Previously, we introduced Archie’s vision for Solidity. This time, let’s dive deeper into Solidity’s architecture with our ever-curious software architect apprentice!
Gatsby Through the Eyes of…
Software can be viewed from many angles. Ask a developer and a user what they think about some software product and you’ll probably get not only contradictory answers, but even uncomparable answers. This is because they look at the software from such a different point of view.
The architecture of architecting Rollercoasters
This essay delves deeper into the software architecture of the OpenRCT2 project. The architecture is first examined from different views, based on the book Software systems architecture by Rozanski and Woods. Then, the software is decomposed and each component’s function is explained. Next, the main architectural pattern of the project is explained and finally the trade-offs between the non-functional properties of OpenRCT2 are discussed.
Behind the ESLint Architecture
Following our last post, we will discuss the architecture of ESLint. Architectural views, styles and design patterns will be discussed. Also, deployment and non-functional properties will be covered. This post gives an overview of the architecture of ESLint.
Architecting for everyone’s contribution
In this second article in a series of four, we, four Computer Science master students from Delft University of Technology, continue our pursuit to analyse the open-source project GitLab. In our previous article, we discussed the fundamental concepts and product vision of GitLab. In this article, we will dive deeper into the key architectural elements of the system to gain a better understanding how these concepts and visions were realised.
From Vision to Architecture
tags: Scikit-learn Python Software Architecture Machine Learning Developers Roadmap Stakeholders
Scikit-learn’s main goal is to make machine learning as simple to use for non-experts while remaining as efficient as possible. To do this scikit-learn has to hide all the complexities and variations between the different machine learning algorithms. In this blog post, we will explore how these requirements have resulted in the current architectural style and which trade-offs have been made to achieve it.
Architecting Next.js
In our previous essay, we introduced you to Next.js, a modern web framework for building React applications. We examined the vision of Next.js, analyzing the set of fundamental concepts and properties of the project and considering the project in its greater context. With this knowledge in mind, we can now try to understand this vision is realized through its architectural elements and relationships, and the principles of its design and evolution.
Ludwig - Connecting the Vision to Architecture
Architecture is a representation of a system that most if not all of the system’s stakeholders can use as a basis for mutual understanding, consensus, and communication. When we talk about the architecture of a software, we refer to a plan that describes aspects of its functionality and the decisions that directly affect these aspects. In this sense, a software’s architecture can be viewed as a set of interconnected business and technical decisions.
MuseScore: Views on development
The MuseScore system is based on an architecture that supports all the requirements, both functional and non-functional. Furthermore, each architectural decision made should support the software development process. This essay addresses issues that occur during the design of the architecture and the decisions that were made based on these issues. An outline of the different views of the system will be given, and some will be explored more in-depth.
Embedding Vision into Architecture
During the previous chapter we discussed what TensorFlow aims to achieve as a product both in its present and future context. As we have seen, this ambitious project tries to suit different use cases with a high degree of flexibility and efficiency making for a not so trivial objective. To realize such a vision, TensorFlow just like any other major project requires a solid foundation supporting all of the smaller building blocks. In this chapter we will focus on how these goals are made possible through means of proper architectural components and the interconnections between them. First, let’s see what kind of different perspectives there are on architecture and how they relate to TensorFlow.
How Spyder Knits its Architecture from Vision
Hi folks! we are back again with some more insights on your friendly neighborhood Spyder. In our first blog, we talked about the product vision of Spyder which focused on the core elements of the system along with the end-user mental model and analysis of the stakeholders. This essay explores how these elements are realized through its architecture and relationships, and the principles of its design and evolution.
NumPy: Software Quality by the Numbers
Software quality plays an important role in an open-source library that is being used in software projects worldwide. It helps in keeping the code maintainable and the releases stable. In this third part of our essay series about the NumPy project we will have a look at the software quality of the NumPy source code and how this quality is assured by the developers of the project.
Views on Ansible’s Architecture
Relevant Architectural Views
Software Architecture deals with abstraction, (de)composition, style and aesthetics. In order to describe the architecture of Ansible, we use a model composed of multiple views. Views can be seen as perspectives of an architecture. To be able to properly display the architecture of a system, Kruchten came up with 5 different views. We use this so-called “4+1”-view model to give more insight into Ansible. In the next subsections we will cover each view in more detail.
From Vision To Architecture: How to use openpilot and live
Autonomous driving is a very simple task in theory, but still remains unsolved at large. How does openpilot tackle the problems that arise on the road?
spaCy: For All Things NLP
In this blog post, we take a sneak-peek into a leading-edge Natural Language Processing (NLP) library for Python, its stakeholders and its journey up until now. Hence we decided to get some words together (pun intented) to describe the insipiration behind ExplosionAI’s NLP project: spaCy
RIOT: The future of IoT
The number of IoT devices powering our daily lives becomes larger every day. On top of that the applications running on these devices become more and more complicated. To keep up with these developments, the developers of such systems need proper tools. An Operating System is an essential part, and provides a lot of basic building blocks. RIOT is such an OS, it’s feature-rich, open-source, adopted by academics and under active development.
Plotting Bokeh, an Analysis to its Present and Future
There is more than meets the eye. Data is everywhere. There are patterns in every aspect of life but sometimes we cannot see them, we cannot understand them and even worse, we cannot retrieve any value from them! Bokeh is one of the many tools that aims to solve this problem: it connects the dots and lessens the distance between what we see and what we understand. In this essay we will look into Bokeh and what motivated its creation, development and vision!
The vision which makes Meteor shine
Meteor provides a simple environment in which reactive web and mobile applications can be easily written and built. Meteor is open source, but it is still officially being developed by Meteor Software. It’s a JavaScript framework built using Node.js. One of its core features is its reactiveness, which means that a change in the application is reflected at once on all the other clients. Meteor is isomorphic, meaning that both client and server side can be written in the same language. Furthermore, Meteor allows for different front-end technologies to be used. This all makes Meteor a great framework to create web and/or mobile applications.
A clear vision or mixed signals?
In this post, we try to discern what the goals of Signal are, how they intend to accomplish these goals and who benefits or suffers from them. We have a look at the unique features Signal offers to its users, and take a leap forward to see what the future may hold.
Product Vision
In this essay, a deep dive was done into the Open edX project, to ascertain its product vision. This vision describes what the system aims to do, and for who. While also keeping the future in mind. For a short introduction into Open edX and what it aims to do, see our intro page.
Testing the vision of Google Test
Just writing code is often not enough, testing is an important aspect which should not be overlooked. Common methods to test software include assertions and unit tests. Some programming languages provide direct support for certain testing tools, many however lack all or most support. One such language that lacks most test support is C++, the language only provides a standard library for basic assertions.
The vision behind ESLint’s success
Understanding the product vision of ESLint is a good starting point for our architectural analysis. The vision of a product has an impact on design decisions. We cover the vision in six sections. First, the intended achievements of ESLint (section 1) and a description of the end-user mental model (section 2). Other key points of ESLint’s vision are the key capabilities and properties of the system (section 3), the stakeholders (section 4) and the current and future context (section 5). We end the product vision with a detailed roadmap, containing the future focus of ESLint, in section 6.
Materialising Material-UI
In this first post, we will establish a basis for understanding the different aspects of Material-UI to facilitate for more in-depth analyses in future posts. We will do this by taking a look at the purpose of the project, the expectation of the end-users, the stakeholders, the competitors, the key capabilities, the product context, and finally the roadmap.
Surfing through Ripple: A Grand Tour
The following post examines the Vision and Mission behind the Ripple Team. The essay is carried out by studying the Ripple environment, the stakeholders, and the team’s accomplishments and possible future plans.
Micronaut - The Product Vision
Micronaut is a full stack framework for JVM developers helping them to build modular, easily testable microservices and cloud-native applications. It provides a familiar development workflow similar to Spring or Grails but with a minimal startup time and memory usage. Therefore, Micronaut covers the gap where traditional MVC frameworks are not suitable, such as Android applications, serverless functions and IoT Deployments.
Product Vision: Make Driving Chill
Problem Definition
Bob’s Traveling Problem
The advertising slogan of openpilot is ‘make driving chill’, indicating that apparently driving is currently not so chill. Imagine Bob who’s living in the US, he visits his family on a regular basis and therefore travels between his residence in Austin TX and his family in Houston TX. Public transport is rarely available along this 266 km route, and while taking a flight is the fastest way of traveling, Bob prefers saving both his wallet and the environment by utilizing his car.
Scikit-learn, what does it want to be?
tags: Scikit-learn Python Software Architecture Machine Learning Developers Roadmap Stakeholders
In this first blog post, we will examine the following aspects of scikit-learn. First, we will describe what scikit-learn is and what it is capable of doing. Then we will describe what stakeholders are involved in the project and finally, we will lay out a roadmap of future development of scikit-learn. This essay thus gives the necessary context for anyone how wants to study the architecture behind scikit-learn.
Uplink to ArduPilot
As understood from its motto “Versatile, Trusted, Open”, ArduPilot aims to be an ideal autopilot software platform. It presents the quality of being versatile, by supporting all kinds of vehicles and numerous sensors, components, and communication systems. It provides several features such as variable levels of automation, and simulations. ArduPilot is further described as “trusted” based on being reliable thanks to extensive use and testing (over 1 million installs), as well as being transparent, secure, and privacy-compliant. This is enabled by its third major point: open source.
TensorFlow: making machine learning manageable
Over the last decade, machine learning has become an increasingly popular solution to solve complex modern-day challenges. Its applications include a diverse range of topics such as image recognition, diagnosing medical conditions or fraud detection. As more distinct fields and industries gain interest in incorporating machine learning techniques into their products, the need for a comprehensive and adaptable machine learning platform arises. This is where TensorFlow comes in, an end-to-end open-source platform for machine learning to easily build and train models, supported by a large ecosystem of tools, libraries and community resources. TensorFlow enables researchers to experiment and push the boundaries of this AI technique while developers can easily build and deploy their machine learning powered applications. With its many options for development and deployment reflected by the number of supported programming languages and hardware platforms, TensorFlow is a very versatile solution applicable to various different domains.
Current and future vision of Ansible
Ansible is in the top 10 of the largest and most popular open-source projects on Github. To understand the vision that makes Ansible so successful, we take a look into the end-user mental model as well as the people and companies involved through a stakeholders analysis. Next to that, we unravel Ansible’s following plans with the future roadmap.
The vision behind mypy
In our first blogpost, the main focus will lie on identifying what mypy’s properties are and for whom it is created. As a real system architect one could identify this as the vision of the project.
MuseScore: Road to reducing paper use in music industry
MuseScore is an application that allows musicians to create, share and modify digital scores in many ways; even recording them by playing a digital keyboard. Furthermore, it allows musicians to store all their scores digitally and bring them to performances without hassle.
GitLab: A single application for the entire DevOps lifecycle
This article is the first in a series of four, where we, four Computer Science master students from Delft University of Technology, will be analysing the open-source project GitLab. In this series we will be conducting an analysis for several aspects about managing an open-source project, both technical and non-technical. Before we dive into these aspects in later articles, we will first provide some context on what Gitlab is and where it is going.
Architecting Blender
This essay will cover the software architecture of Blender, i.e. the structure and architectural patterns of Blender’s codebase.
Next.js: Back to the Future
Traditionally, when browsers were much less capable than today, websites were mostly static with the logic being performed on the server. Back then, most websites served some HTML that was rendered using a templating language such as PHP, which would then be taken over on the client by a different codebase (powered by jQuery or similar).
NumPy: Awesome Architecting for Amazing Arrays
This is the second installment of our 4-essay-long series about the NumPy project. For the first essay about the stakeholders and project in general, please visit this page. In this second essay, we will take look at NumPy from different architectural perspectives which are based on literature. These different views aim to give the reader insight into how NumPy implements it’s key properties.
What is Docker Compose, and why does it matter?
Docker Compose is an orchestration tool that manages multiple docker containers in a single application, allowing the running of application components in isolated environments without unnecessary complexities. Compose automates the building, deploying and running of the docker containers allowing engineers to develop and deploy without building, dependencies, and compatibility issues. Compose achieves such isolation using container-based technology which allows a lower CPU and memory overhead compared to hypervisors and virtual machines.
OpenRCT2, Porting RollerCoaster Tycoon into 2020
In 1999, Chris Sawyer released the revolutionary and succesful game; RollerCoaster Tycoon (RCT). Many sequels later, the series remains popular to this day, and has inspired fans to develop an open-source re-implementation: OpenRCT2.
Your friendly neighborhood SPYDER
Some spiders change colors to blend into their environment. It’s a defense mechanism. But the “spider” we are going to talk about changes environment to blend in the user. Spyder is an open-source IDE (integrated development environment) for Python programming language. It offers easy to use editor, debugging tool with unique data exploration features which makes Spyder a great tool for data analytics use and it is included in the Anaconda toolkit by default. Spyder is short for Scientific Python Development Environment.
The Vision of Ludwig
Technology should be accessible to everyone - be it an expert in a domain or a novice. Ludwig is such a toolbox that bridges this gap with it’s singular motive to make machine learning as simple and as accessible as possible.
NumPy: its Goals, Stakeholders, Use and Future
NumPy, short for Numerical Python, is a Python library that provides functionality for scientific computing. The first versions of the library were initially part of SciPy under the name Numeric. As the library became more popular and required more flexibility and speed, numarray was created as a replacement by the Space Science Telescope Institute. Numeric and numarray were eventually split up, but in 2005, Travis Oliphant reunited them, separated everything from SciPy and named the new library NumPy. In 2006, the library was included in Python’s standard library.
Blender in Perspective
Blender aims to “build a free and open source complete 3D creation pipeline for artists and small teams, by publicly managed projects on blender.org”. That is, Blender wants to offer functionalies of the entire 3D creation pipeline. This “3D creation pipeline” refers to all the stages towards 3D pre-rendered or real-time imagery: modeling and/or sculpting, rigging, animation, simulation, rendering, compositing, motion tracking, and even video editing.
Solidity: The Product Vision
This is the first in a series of 4 essays that analyse the architecture of Solidity. We start off with a description of the vision underlying Solidity and a peek into the future of Solidity.