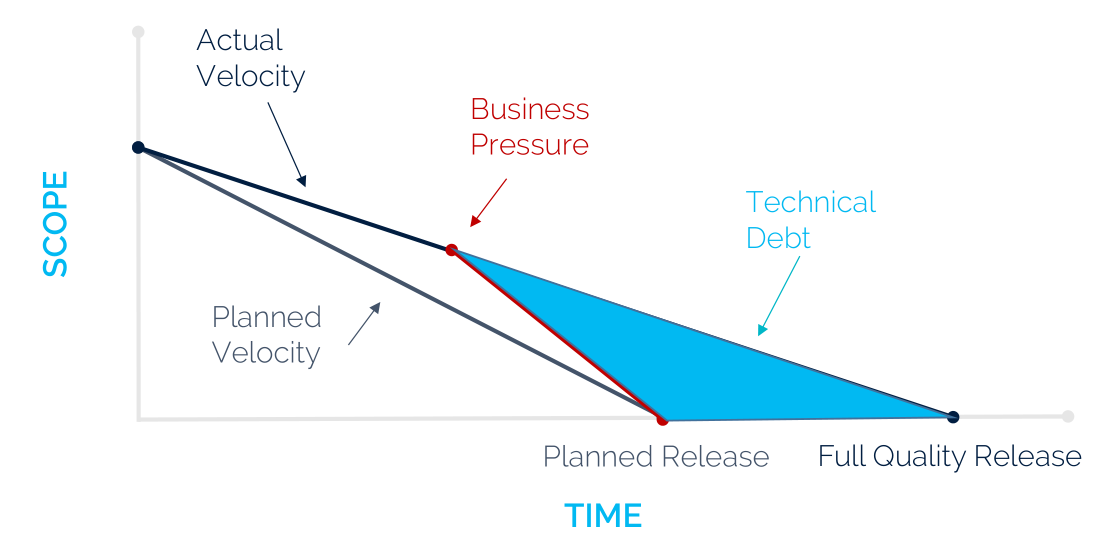
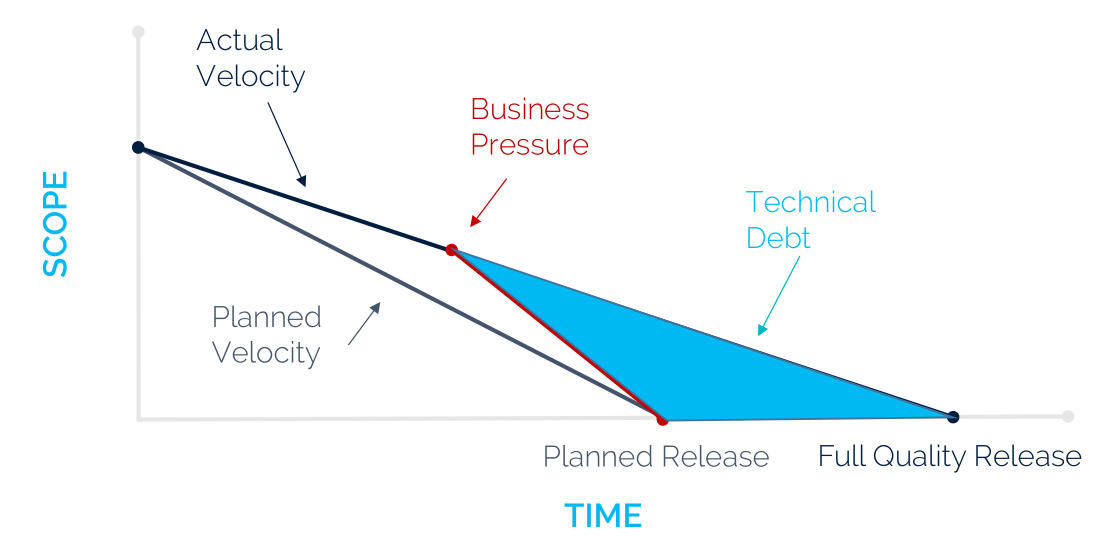
Now that we have discussed Ansible’s architecture, it is time to dive deeper into the implementation details. Like any other software system, Ansible is prone to the build up of deficiencies in internal quality that make it harder than it would ideally be to modify and extend the system1. This deficit in quality is often caused by business pressure on the tech team to meet the milestones. This results in quick and dirty solutions to increase the velocity (see figure below). Interestingly, the Ansible core team has been working on decreasing their technical debt, by migrating all the modules to so-called Collections, which will be laid out in more detail in this essay. Similarly, a major refactoring of the code was done in Ansible 2.0 to pay off the technical debt that had accumulated. To analyze the current technical debt of Ansible, we will first examine the development process. Then we give an analysis of the code quality and finally we will discuss how Ansible is planning to deal with this debt in the future milestones.
{kind=link}
Process
At a high level, Ansible always works towards a release. Each release has a roadmap containing desired features which is tracked through a github project. A release has several deadlines. First comes the feature freeze, after which no new features will be added and focus shifts to removing bugs. Then comes the first Release Candidate (RC). This version will be released, but might not be stable. New RC’s are released until no more bugs are found. At that point the release is finalized and a stable release is made available to the general public. This process ensures that releases contain no untested code.
At a lower level, development takes place using pull requests (PRs). Each pull request is examined by a bot which will add various tags indicating the type of pull request, which part of the project is touched by the PR, the maintainer of the files touched, and the targeted release2. This makes it easier for maintainers to keep a good overview of all open PRs.
Continuous integration
Ansible uses Shippable for continuous integration (CI). Each PR is checked against a large number of existing automated tests. Each test is run multiple times in various environments. This includes different Python versions and different operating systems3. Ansible uses several types of tests:
Compile Tests4. These check the code against the syntax of a variety of Python versions.
Sanity Tests5. This includes various scripts and tools that run static analysis on the code, primarily to enforce coding standards and requirements.
Unit tests6. These tests are isolated tests run against an individual library or module.
Integration tests7. These are functional tests defined as Ansible playbooks. They cover a variety of functionality including installing and removing packages and network functionality. Since some of these tests can cause destructive behavior, they are usually run in Docker containers.
Additionally, Ansible uses codecov.io8 to generate code coverage reports. These reports give a decent metric on how well parts of the system have been tested.
Process evaluation
Ansible has a fairly comprehensive development process, with a good number of checks. However, some things could be improved. For example, while a code coverage report is generated, users have to specifically navigate to the coverage website to see it. This means that the effects of a PR on coverage are not easily visible. A summary could be added to PRs.
Further, despite the well documented PR lifecycle, many PRs are merged without any clear review (e.g. PR68429, PR68407, and PR68200). The fact that this is possible likely makes it easier to implement small changes, but it is not clear where the line is between PRs that need to be reviewed and PRs that don’t. It is also not clear why certain PRs are not merged (see for example PR68083, PR67931, and PR67893). It looks like the core team also discusses PRs outside github.
When examining the coverage report a few things come up. First, the powershell code is barely tested at all. Especially when compared to the Python code. This might be because of the fact that powershell code is primarily used for very simple scripts while Python is generally used as a more full featured language. So developers are not used to writing tests for powershell. Second, coverage for individual modules varies greatly. This likely has to do with the fact that the (community) maintainer of each module is somewhat responsible for the testing standards.
Code quality
The development process is usually reflected in the actual code, which is why we will analyze the code quality. Code quality of products created by software engineers and technical debt are very related. According to Philippe Kruchten there are about 5 types of technical debt: architectural, documentation, technological gap, code level and testing9. For this essay we will stick to the latter two. In order to measure the software quality of Ansible we use SonarQube. Not only because it is one of the most popular world known solutions for enterprise software quality measurements, it is also open source and free. It applies software quality heuristics like code volume, amount of bugs, and code smells. Since in the last month Ansible has been migrating their code to multiple repositories to improve the code quality, we will focus on the repository both before and after the migration and make a comparison.
Notes: SonarQube uses letter ratings ranging from A (good) to E (bad). Vulnerabilities and Security Hotspots will not be addressed, since this is somewhat related to technical debt, but it is not the topic we want to dive in here. Test coverage will also not be discussed here, as SonarQube was not able to display this.
SonarQube - before migration
Code volume |
Firstly, to be able to compare the results of SonarQube with the overall codebase, we need to assess the size. Ansible (before migration) has a total of 1.7 million lines written in Python and 13.000 in XML. Next to that, a relatively small amount is written in HTML, JavaScript, CSS, and Go. As we have seen already in our previous essay, with 1.3 million lines of code, lib/ansible is the largest folder in Ansible.
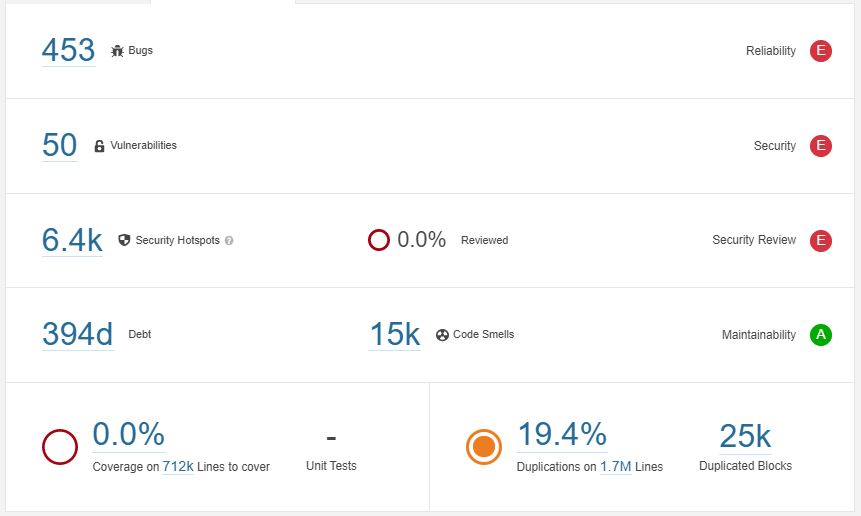
Bugs | SonarQube found 453 bugs, of which 39 are minor, 131 major and the remaining 283 bugs are so-called blockers. At first sight, 453 bugs on 1.7 million lines of code seems pretty good. Why then does SonarQube give the lowest possible reliability score? The answer lies in the blocker-bugs. These bugs have a “high probability to impact the behavior of the application in production”10. After examining the bugs, it becomes clear that almost all are caused by symlinks.
For example, in lib/ansible/modules/source_control/gitlab/ a symlink to the file gitlab_hook.pyis made, but SonarQube sees it as a python file and thinks a variable is used before it is defined. Another found blocker-bug is that of a mismatch between the number of arguments passed to a function and its parameters. However, the functionality here is implemented for backwards compatibility, as is documented in the code. By identifying and removing these false positives from the analysis, the blocker-bugs were reduced to three.
Some of the bugs in the major category are also questionable. Such as a redirecting web page missing a <!DOCTYPE> and <title> tag. It’s sole purpose is to redirect to another page, making the missing tags acceptable. However, quite a few copying errors were found in the major bugs list, such as an or operator on two identical expressions.
Removing all the false positives resulted in 170 bugs in total.
Code smells & Maintainability | Ansible scores an A for maintainability, while there are 15.000 code smells found. SonarQube estimates 394 days in technical debt, to fix these issues. Why does Ansible deserve the best maintainability score? Rating A means that the remediation cost is less than 5% of the time that has already gone into the application11. Time here is translated to the “cost to develop 1 line of code * Number of lines of code”, where one line of code costs 0.06 days. Considering the size of Ansible, the reason for Ansible’s high maintainability score becomes clear; 15.000 code smells on 1.7 million lines of code is not that much and code smells in general for a project with almost 5000 contributors is perhaps unavoidable.
Duplication | According to SonarQube, there was 19.4% duplication of code, which is a fairly high amount. However, this duplication may be the result of certain tools that create lines automatically, as can be seen in our pull request. Using such tools may thus increase the amount of duplicate code, but in the case of Ansible, the repository is well maintained and files like these are never touched. Still, many code blocks are found by SonarQube that are present in multiple files, which is a point of improvement. Some of these code blocks could be moved to the modules_utils folder, where a lot of utility functions of different modules already reside.
SonarQube - after migration
Code volume | The impact of the migration can be seen directly from the size of the new Ansible repository; with a little more than 1.5 million lines of code that were removed, Ansible core now has “only” 200.000 lines left. These lines are spread out over the corresponding Ansible Collections12, resulting in a cleaner Ansible core repository. The decrease of lines of code has significantly lowered the amount of bugs. Of course, the bugs are only migrated, but so are the responsibilities. We can now focus on analyzing Ansible’s core code.
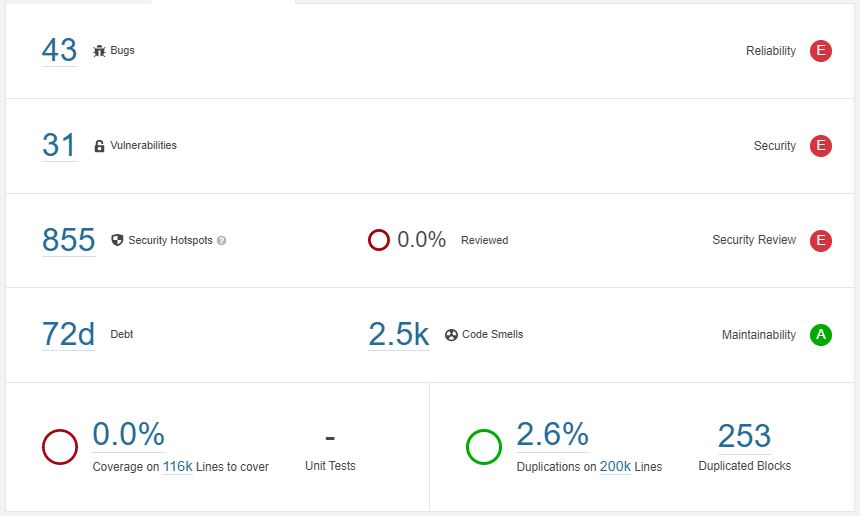
Bugs | Some of the symlink false positives are still present in the new analysis. Removing these results in a total of 33 bugs; a big improvement coming from 170!
Code smells & Maintainability |
As we can see from the maintainability rating, the amount of code smells has decreased proportionally with the amount of code moved. Ansible still has an A-rating, but now only needs around 72 days to fix their code smells. Some of these code smells include commented out code, unused variables, and FIXME comments.
Duplication | Code duplication has decreased greatly, as was expected. Many modules used the same functionalities and thus had duplicate code. By moving each of these modules to their own Collection repository, the analysis tool finds less duplications in the core code. In some way, this decrease in reusable code can be seen as a loss. Ansible could however still provide some utility Collections, but using these is up to the Collection creators and maintainers.
SonarQube - improvements
To summarize, we give an overview of the improvements found by SonarQube for Ansible before and after the migration:
| Before migration | After migration | |
|---|---|---|
| Bugs | 170 | 33 |
| Code smells | 15.000 | 2.500 |
| Technical debt | 394 days | 72 days |
| Code duplication | 19.4% | 2.6% |
Logically, since a lot of code has moved, many bugs have moved as well. Still, the Ansible core repository is greatly improved. Some points of improvement remain:
- remove identical expressions (e.g. in
oroperators) - add missing attributes on webpage (e.g. add
titleto<iframe>) - implement functionality where
AnsibleError("Option not implemented yet")is raised or aFIXMEcomment is placed - review the duplicate code and remove where possible
Technical debt
As stated in the introduction of this essay, the technical debt hinders the ability to modify and extend a system. For Ansible it was the right time to pay off their technical debt as it became too large to maintain properly (see conversation on freenode below).

Our assessment of the code quality (before and after the migration) makes it is clear that the changes made in the migration are in line with paying off technical debt. The software quality is improved, and with that the debt is partly paid off. However, the technical debt cannot only be measured by programming aspects of software delivery. It is important to look at the full development lifecycle. This includes evaluating PRs. As we have stated in our process section, this is a point of improvement. That being said, it is not very clear what Ansible’s internal approach is to handle technical debt. We suggest they use the 7-steps approach by Jean-Louis Letouzey. We like this approach as it includes almost all our points of improvement.
-
https://martinfowler.com/bliki/TechnicalDebt.html ↩
-
https://docs.ansible.com/ansible/latest/community/development_process.html ↩
-
https://github.com/ansible/ansible/blob/devel/shippable.yml ↩
-
https://docs.ansible.com/ansible/latest/dev_guide/testing_compile.html#testing-compile ↩
-
https://docs.ansible.com/ansible/latest/dev_guide/testing/sanity/index.html#all-sanity-tests ↩
-
https://docs.ansible.com/ansible/latest/dev_guide/testing_units.html#testing-units ↩
-
https://docs.ansible.com/ansible/latest/dev_guide/testing_integration.html#testing-integration ↩
-
https://codecov.io/gh/ansible/ansible/ ↩
-
Kruchten, P., Nord, R. L., & Ozkaya, I. (2012). Technical debt: From metaphor to theory and practice. Ieee software, 29(6), 18-21. ↩
-
https://docs.sonarqube.org/latest/user-guide/issues/ ↩
-
https://docs.sonarqube.org/latest/user-guide/metric-definitions/ ↩
-
https://github.com/ansible-collections ↩