This essay will outline how and to what extent Blender is variable. This “software variability is the ability of a software system or artifact to be efficiently extended, changed, customised or configured for use in a particular context”1, and this means we will take a look at how many different “instantiations” of Blender are possible, and how these are obtained. We start with identifying these variable components, also referred to as “features”, and modeling those in a feature model.
Variability analysis
Blender is available on Windows, macOS, Linux2, and this choice constitutes the first feature we distinguish. This kind of platform variability is a form of compile-time binding, resulting in a separate binary for each platform. Functionally, these binaries are — as far as we know and have investigated — functionally identical, and choice of operating system entails no functional constraints. (The Windows version does seem to perform better.3) Blender even replaced GLUT with their own windowing system, called GHOST, in order to be multiplatform.4
Besides the stable builds, there are also unstable daily builds, containing newer features5, and builds from experimental branches6, which is a form of functional variability. Especially for developers, there is even more compile-time binding variability, as Blender offers several build targets. After a developer has cloned the Blender repository, he can build the application by simply running make on Linux and macOS or ./make.bat on Windows. Additional flags can be passed on for customizing the builds. The available options can be retrieved by running make help or ./make.bat help. The options that are relevant to the building of Blender are:
debug: Debug binary, which simply disables certain compiler optimizations and includes debug information. We do not consider this build a feature.release: Identical to the official builds on blender.org builds, i.e. a complete build with all options enabled.regular: Similar to a release build, except CUDA and Optix.lite: Contains the minimum amount of features enabled for a smaller binary, faster building time, and less dependencies.headless: Omits the interface (and is meant for renderfarms or server automation).cycles: Build Cycles standalone only, without Blender.bpy: Build as a Python module which can be loaded from python directly.deps: Build library dependencies (intended only for platform maintainers).developer: Enable faster builds, error checking and tests, recommended for developers.config: Run CMake configuration tool to set build options.ninja: Use Ninja build tool for faster builds.
Besides these preset build targets, Blender’s CMake configuration file offers hundreds of options7, and almost any library and non-essential component of Blender can be enabled or disabled, leading to an enormous amount of product variations.
Conditional compilation is used for specifying code that is to be used with or without certain targets. The debug build target does not result in a different codebase, as the options that are changed are mainly compiler options. The headless target, on the other hand, does have preprocessor macros (#IFDEF) that change what will be compiled. A headless build does not not contain any graphical interface, and as such, any GUI code does not have to be compiled.
The build configuration for Blender seems to be somewhat complex considering the size of the codebase and the variability in build targets. When looking at the commit history of the build files however, it is apparent that they are not changed often. At present, it seems to be fully stable, though the build configuration files might prove to be an obstacle when more build targets are added.
Add-ons
An important feature of Blender, which we have thusfar only briefly touched upon, is Blender’s Python scripting API and all the modding possibilities (a “mod” is a modification, hence a feature) that this brings. Blender comes bundles with a number of add-ons already, some are labeled as officially supported (by the Blender developers), some are labeled as community supported (by community developers), and the rest is labeled as testing, and these are not included in release builds. Besides these, anyone can script an add-on, distribute it, and have others import it. All add-ons can be enabled and disabled in Blender’s Preferences window without restarting the program (because they are written in Python), indicating that these add-ons are bound at runtime. An add-on must have the following:
bl_infoDictionary containing metadata bout the add-on.registerFunction that is run when enabling the add-on.unregisterFunction to unload anything that was setup. Called when the add-on is disabled.
Blender’s documentation on writing add-ons8 makes apparent that Blender uses the Observer pattern for their add-ons, as every add-on must have the register() and unregister() functions.
In order for an add-on to be accepted into the officially distributed add-ons catalog, it must meet several requirements 9. These requirements are quite complete and strict:
- Contain add-on meta information in a
bl_infodictionary. - Define
register()andunregister()functions. - Be documented on an associated wiki page in the Blender wiki.
- Be evaluated and approved by another Blender developer.
- Pass the Flake8 / other PEP8 checker tool for style guide enforcement.
- Be compatible with the latest Blender release.
- Inclusion of binary data-files is to be avoided.
Furthermore, for an add-on to remain accepted into the official release, it must also receive continuous maintenance to keep the add-on working. Because of these strict guidelines, the number of default installed add-ons will not become too large to the point where it starts slowing down the application, and thus Blender should remain scalable. Furthermore, the add-ons do not modify Blender’s internals and are mostly extensions to the UI.
Blender’s Preferences options
Besides add-ons, the Blender Preferences window naturally contains many options for modifying the program, but many of these we either consider to be part of the program’s functionality and thus not a (variable) feature, or they are too specific and mentioning them all is cumbersome and not informative. We do want to distinguish the option of rendering device for the Cycles rendering engine. Cycles is Blender’s physically-based (photorealistic) ray tracing engine, and this can be run either on the CPU or on the GPU. Furthermore, when running on the GPU, there is the choice of graphics API: Nvidia’s CUDA or Optix, or OpenCL. The Cycles engine furthermore has the option of enabling its experimental feature set.10 However, as of writing, adaptive subdivision is the only experimental feature. All these Cycles-specific options are bound at runtime.
As for minor options, Blender offers a number of GUI translations. 8 languages are fully supported, 9 languages are works in progress, and the translation of 19 languages is just getting started. For audio device, there can be chosen between OpenAL or SDL.
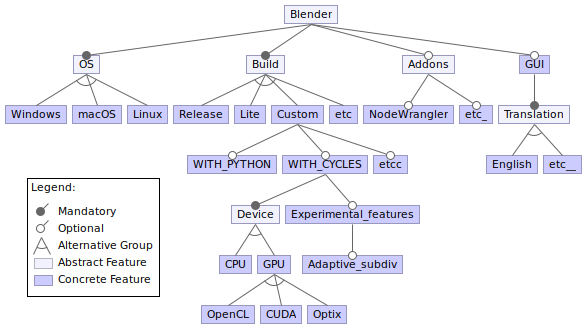
Figure: Feature model
We created a feature model with FeatureIDE11 for the features we identified. All (additional) constraints arise between the CMake build options. For example, when WITH_PYTHON is disabled, we cannot use the Cycles rendering engine (WITH_CYCLES) and neither can we use the Draco mesh compression Python module (WITH_DRACO). As another example, when we build Blender as a Python module, the CMake configarion disabled the GUI. The CMake configuration (CMakeLists.txt) defines many, many such contraints, and some are rather complex, consisting if many nested if-else statements.
Aside from the build options, however, we have not been able to identify any constraints that cannot be expressed in the feature model, and we think this is a testament to Blender’s versatilty.
Variability management
For stakeholders, the way all the variability is managed is quite straightforward. Most of the end-users interact with the three available operating system choices2, and the translations that are available in the Blender settings. If there are new features they want to take advantage of, at the bottom of the download page they can also download the experimental builds. More invested end-users might also want to install the mentioned add-ons. The rest of the builds available from the CMake file in the source code is intended for the stakeholder category of developers, as there is no reason for end-users to have the source code.
As for the information that is available to the end-users and developers about variability management, most of it can be found on many of Blender’s sites. For example, end-users can find information on add-ons in the Blender manual 12. For developers, there is tons of information on different variability options on the Blender wiki. All the information starts in the Building Blender “hub” page 13. From there, developers access information on resolving building issues14, can get redirected to the building options15 mentioned in the previous section, find links to what the best setup is for developing Blender16, library dependencies that Blender needs17, and lastly, information on other building options, such as Blender as a Python module18 or building with CUDA and Optix19.
The library dependencies that are needed are stored precompiled in an SVN repository and automatically downloaded when running make update. The precompiled libraries are built through the use of a CMake based system. On Linux, it is also possbile to use the System Package Manager to install many of the libraries, though losing the portability option this way. Besides the common build errors listed in the link above, it is also possible to report build problems on the Building Blender forum 20 or on the Blender IRC 21, so there are enough places for developers to help each other with building Blender. Inside the building options page mentioned in the previous paragraph, it is explained how to speed up the building, such as enabling address sanitizer in CMake, using the Ninja build system, or using ccache in Unix-based operating systems, which seems to be especially useful when switching between Git rivisions and branches. On the page intended for developers with links to different tools 22, it is also possible to find information on how to use distcc with Blender 23, which is a tool to distribute building C/C++ software across multiple Unix-like systems, and is useful for when developers need to rebuild the entire source tree many times.
Conclusion
Blender is highly variable, but most of this variability is aimed at developers or users building from source. For regular users, the most relevant form of variability manifests itself in the stable/nightly/experimental builds and the platform variability. Across platforms, Blender is ultimately very consistent, at least in terms of functionality and from the perspective of the end-user. This makes Blender very predictible and compatible, and allows users on different platforms to collaborate.
-
Svahnberg, M., et al. (2005) ‘A taxonomy of variability realization techniques’, Software - Practice and Experience, 35(8), pp. 705–754. ↩
-
Blender, Download Blender. https://www.blender.org/download/. ↩ ↩2
-
Blender Benchmark. https://opendata.blender.org/benchmarks/query/?group_by=os. Last accessed: 2020-04-06. ↩
-
Letwory Interactive. Blender: GHOST. http://www.letworyinteractive.com/blendercode/d5/d2e/GHOSTPage.html. ↩
-
Blender, Download Blender Daily Builds. https://builder.blender.org/download/. ↩
-
Blender, Download Blender Experimental Branches. https://builder.blender.org/download/branches/. ↩
-
Blender, Diffusion. CMakeLists.txt. https://developer.blender.org/diffusion/B/browse/master/CMakeLists.txt. ↩
-
Blender, Add-on Tutorial. https://docs.blender.org/manual/en/latest/advanced/scripting/add-on_tutorial.html. ↩
-
Blender, Add-on guidelines. https://wiki.blender.org/wiki/Process/Addons/Guidelines. ↩
-
Blender Developer Wiki, Cycles, Experimental Features. https://docs.blender.org/manual/en/latest/render/cycles/features.html. ↩
-
FeatureIDE. https://featureide.github.io/. ↩
-
Blender, manual, Add-ons. https://docs.blender.org/manual/en/latest/editors/preferences/add-ons.html. ↩
-
Blender, Building Blender. https://wiki.blender.org/wiki/Building_Blender. ↩
-
Blender, Resolving Build Issues. https://wiki.blender.org/wiki/Building_Blender/Troubleshooting. ↩
-
Blender Developer Wiki, Build Options. https://wiki.blender.org/wiki/Building_Blender/Options. ↩
-
Blender, Building Environments. https://wiki.blender.org/wiki/Developer_Intro/Environment. ↩
-
Blender, Library Dependencies. https://wiki.blender.org/wiki/Building_Blender/Dependencies. ↩
-
Blender, Blender As Python Module. https://wiki.blender.org/wiki/Building_Blender/Other/BlenderAsPyModule. ↩
-
Blender, Building Blender with CUDA and Optix. https://wiki.blender.org/wiki/Building_Blender/CUDA. ↩
-
Blender, Building Blender forum. https://devtalk.blender.org/c/blender/building-blender. ↩
-
Blender, chat. https://blender.chat/channel/blender-coders. ↩
-
Blender, Development Tools. https://wiki.blender.org/wiki/Tools/distcc. ↩
-
Blender, distcc. https://wiki.blender.org/wiki/Tools/distcc. ↩