We analyze the integration process, code quality, test coverage, and how this is facilitating the roadmap of Compose. Then, we delve a bit deeper into technical debt and refactoring solutions of newer features and the entire system as a whole. Overall, Compose system has an organized and aligned development process with high test coverage. However, there’s much improvement and refactoring needed on the code quality and entanglement itself.
Coding the architecture
Commits are individual file changes used in version control tools like Github. Counting the number of times that a commit modifies a file indicates code activity (hotspots).
We analyzed file history from 2013 to 2020 to identify code hotspots excluding testing and CI/CD related files. From our analysis (Fig.1), we found that compose/service.py (513), compose/config/config.py (402), compose/cli/main.py (399), and compose/project.py (276), were the most committed files of the Docker Compose project; these files belong to key components, Compose, CLI and config. As a side, note “fig” was the previous name of “compose” when the project was not yet part of Docker.
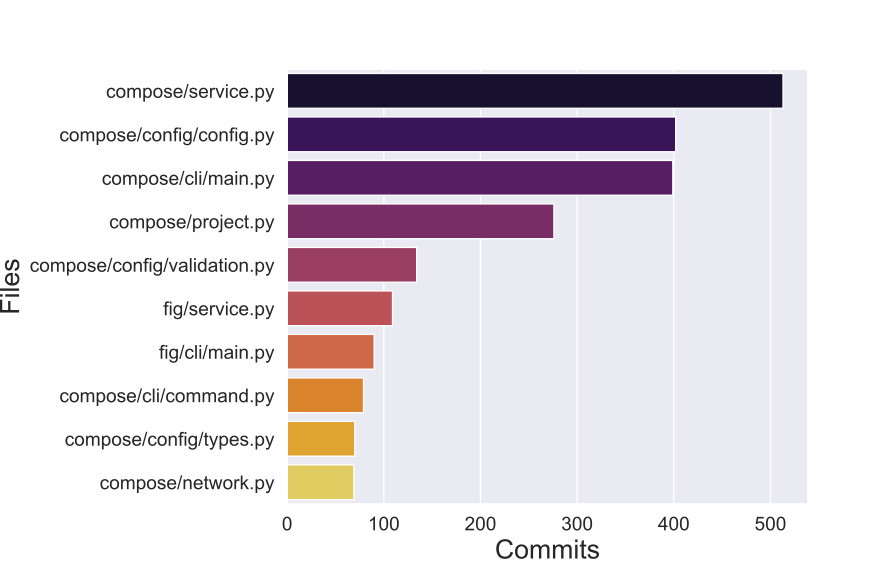
Figure: Top 10 most commited files (2013-2020)
From 2019 to March 2020 (Fig.2), we found that compose/cli/main.py (27), compose/service.py(24), compose/project.py(22), and compose/config/config.py(11) were the most committed files, following the same trend in hotspots that we encountered in previous years; that means that there were not architectural changes during the last months of development.
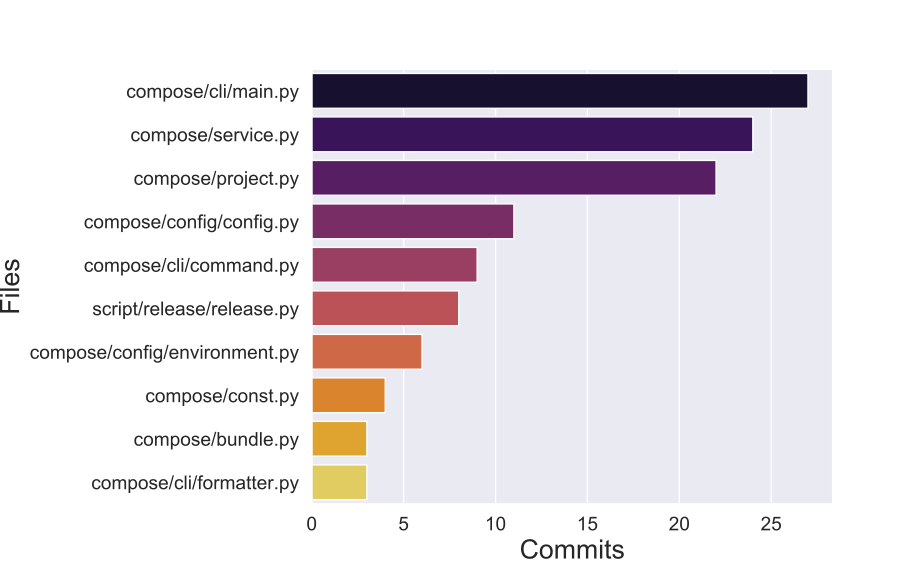
Figure: Top 10 most commited files (2019-2020)
From Roadmap to Code
Starting 2020, Docker Compose 1.25.1 was released; this release added support to Buildkit which enables faster builds. After that, the repository shows small stories that deal with additional functionality and bugfixes. Stories like those will be developed in the hotspots mentioned in the previous section.
Epics are bodies of work used in agile methodologies that could be subdivided into stories. We based our findings of expected features on the analysis of Epics in combination with recent repository activity and the latest strategies from the Docker project.
Looking at active Epics, we expect efforts in:
- Removal Python 2
- Proposals to rely on Docker CLI
- Reconcile docker-compose schema on docker/cli vs docker/compose
For March 2020, the roadmap of Docker Compose is about code cleaning and alignment. The reason behind this is the required removal of Python 2 due to its end of life (January 2020); this issue is now under scope discussion. Another goal found in Epics is to make Docker Compose work in harmony with Docker. To make this possible, architectural level decisions and stakeholder coordination might be needed to avoid duplication of schemas between the two projects.
For the rest of the year, we can predict that as Docker refocuses on developers, Docker Compose will remain as a lightweight orchestrator for developers in constant syncing with the recently announced public Docker roadmap; an interesting approach that leaves space for decision making about the direction to the community. As far as we don’t see any architectural changes, a keep things simple mindset, we predict that changes might remain in the same top 10 most modified files on the Docker Compose project presented in the previous section.
Code Quality
How good or bad the code quality is rather subjective and depends on what the organization considers important. From the roadmap explained, Compose main concern is around avoiding complexity and support maintainability and that cli and config will be the most affected components.
We use Sigrid, SonarCube and CodeFactor as static analysis tools to give an overview of Compose code quality. Overall, Compose has an average code quality as reported from each tool:
- Sigrid reports great score in code volume, duplication, and component balance but low in components independence and unit complexity
- SonarCube reports great score in technical debt and code smells measurement
- CodeFactor reports an overall code quality score of C- based on complexity, maintainability, and security
Code Complexity
We use McCabe Cyclomatic Complexity as it is one of the well-known and widely used metrics 1. Cyclomatic complexity simply measures the number of paths run through code2.
CodeFactor identifies Compose code cyclomatic complexity as low-risk problems. There are 8 issues low-risk complexity found in some code files as shown in Fig.3.
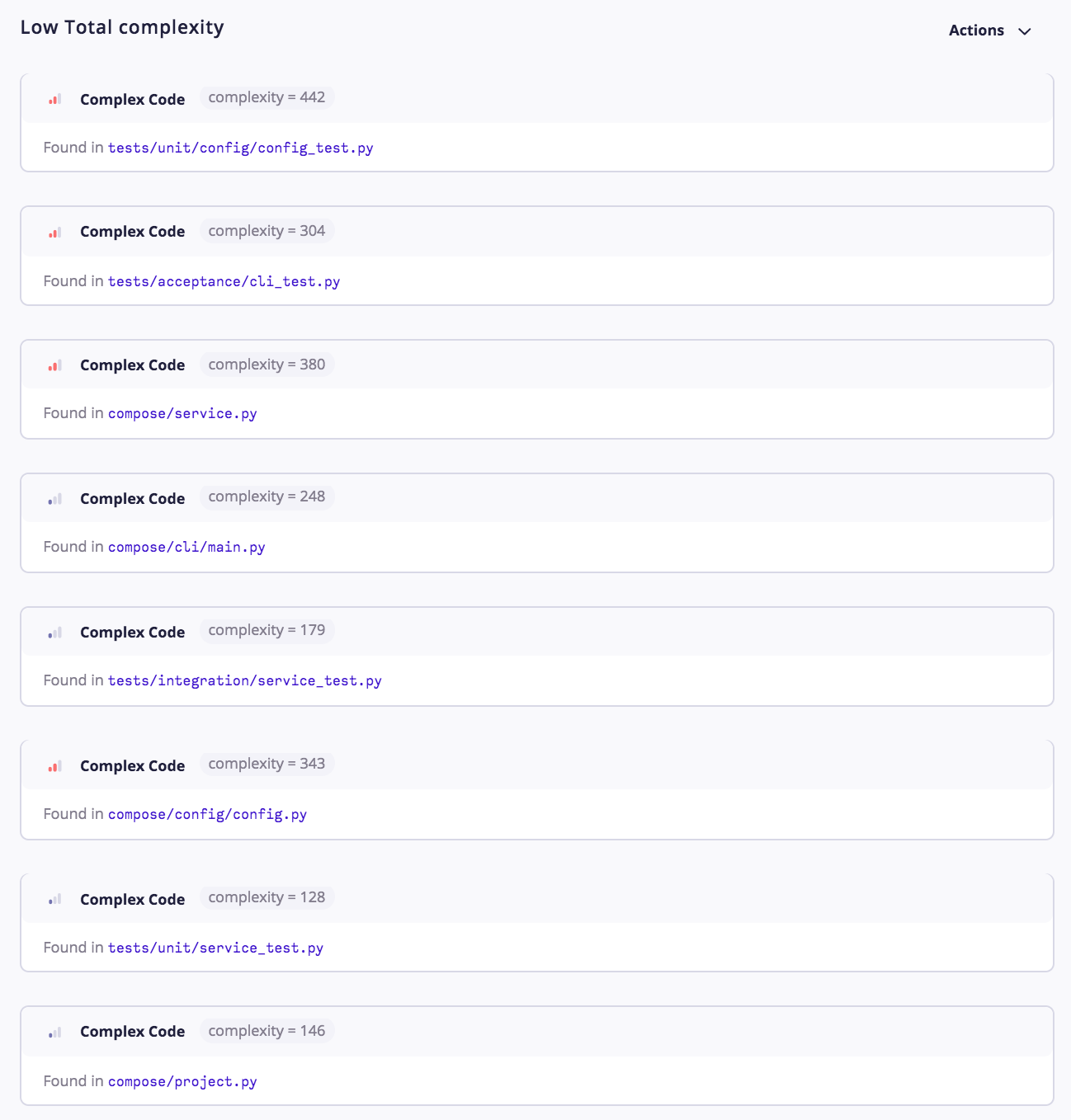
Figure: Compose source code files with complexity issues
Only 8 methods identified having complexity issues (Fig.4), all also low risk. Some methods from cli and compose are identified as having complexity issues. But if we take a look at the low-risk complexity score which ranges around 16-23, it’s still considered manageable.
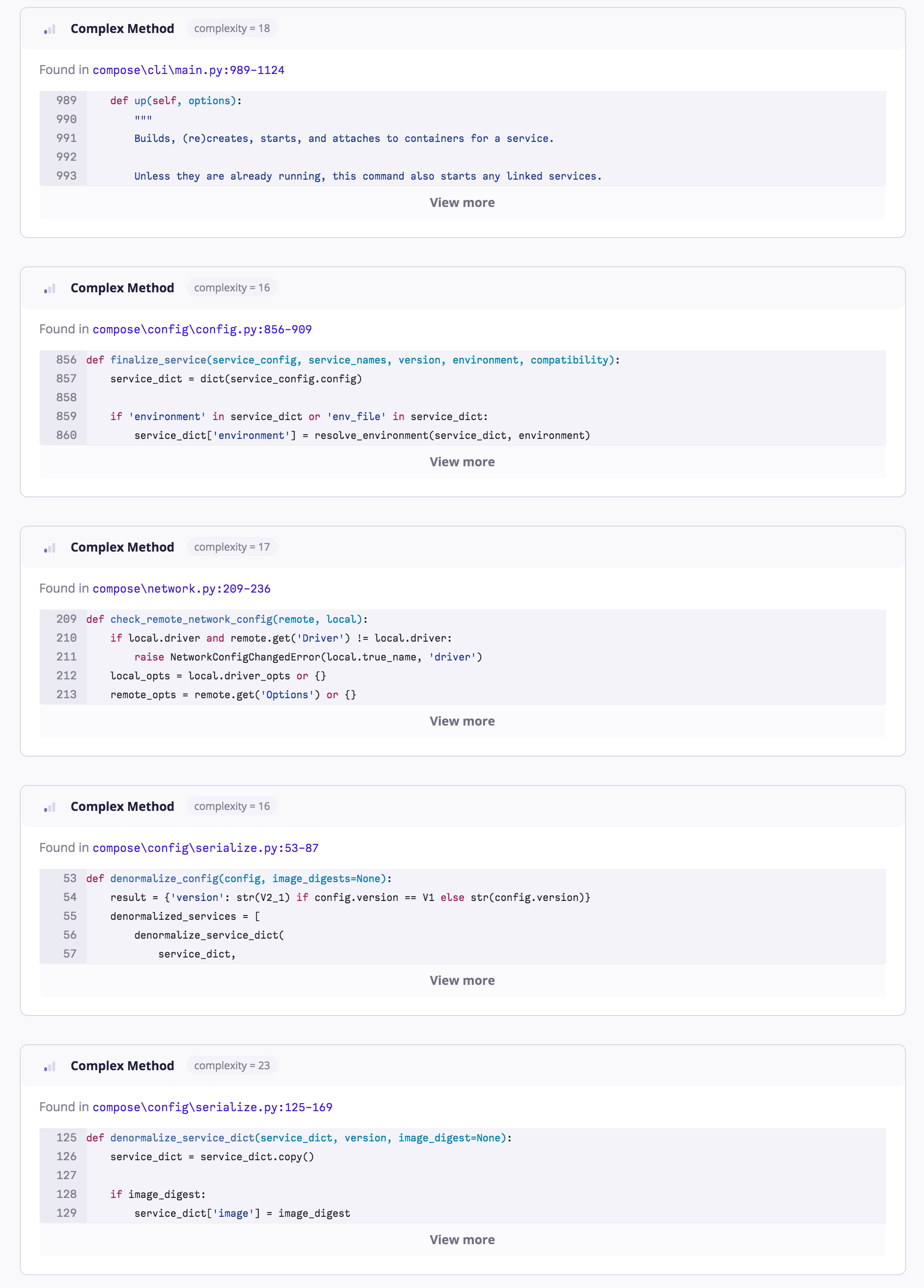
Figure: Compose source code methods with complexity issues
Other metrics are code duplication levels and unit sizes as reported by Sigrid (Fig.5). Compose has low duplication percentage which is good. While in terms of unit size, it can be seen that only 50% of them are in good condition.
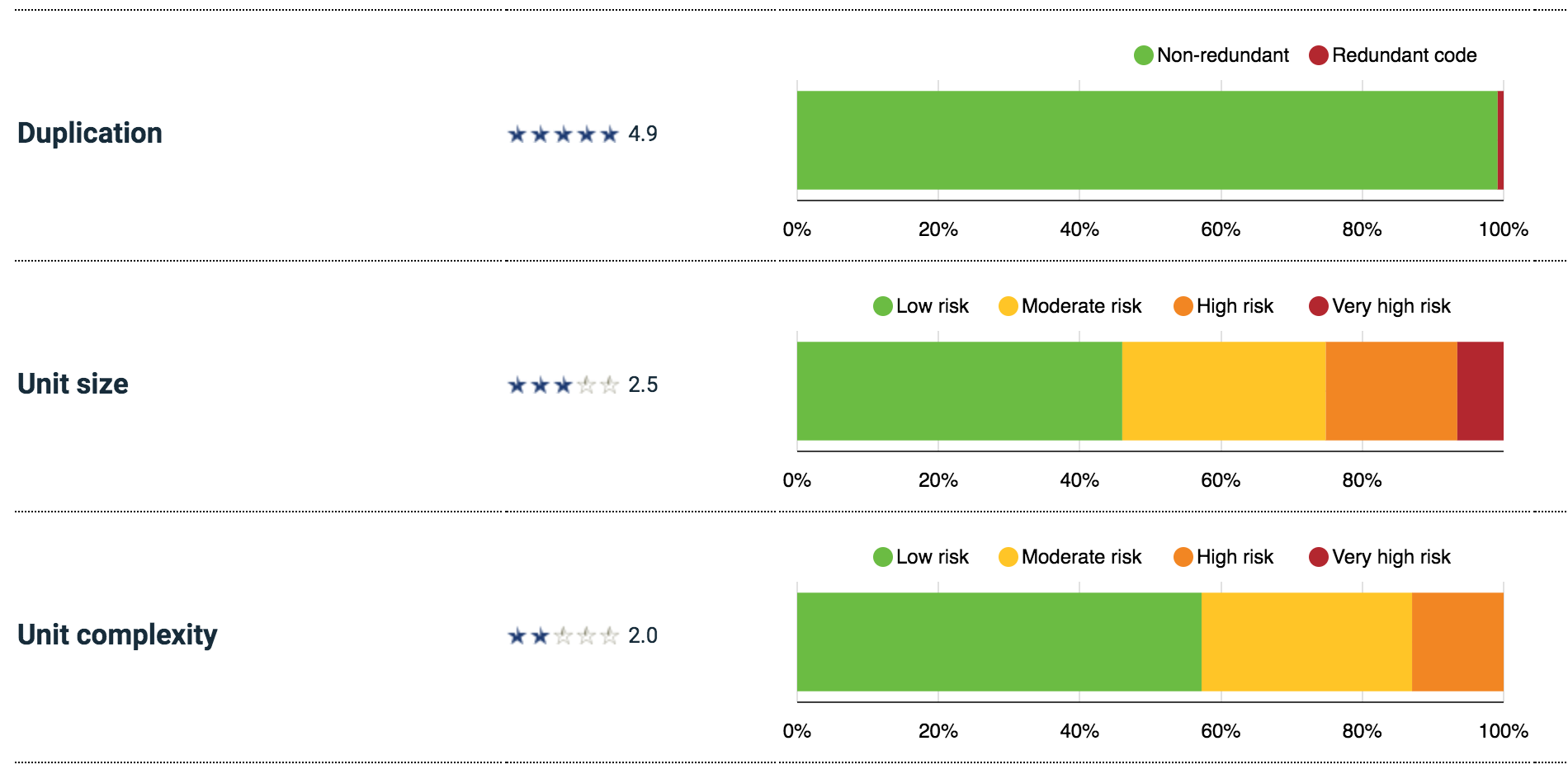
Figure: Compose source code methods with complexity issues
Code Maintainability
Code maintainability can be seen as the effort needed to make specified modifications to a component implementation 3. Fig.6 shows Compose component entanglement graph as reported by Sigrid. It can be seen that there are many dependencies between cli and compose component which ideally shouldn’t exist based on the layer structurization.
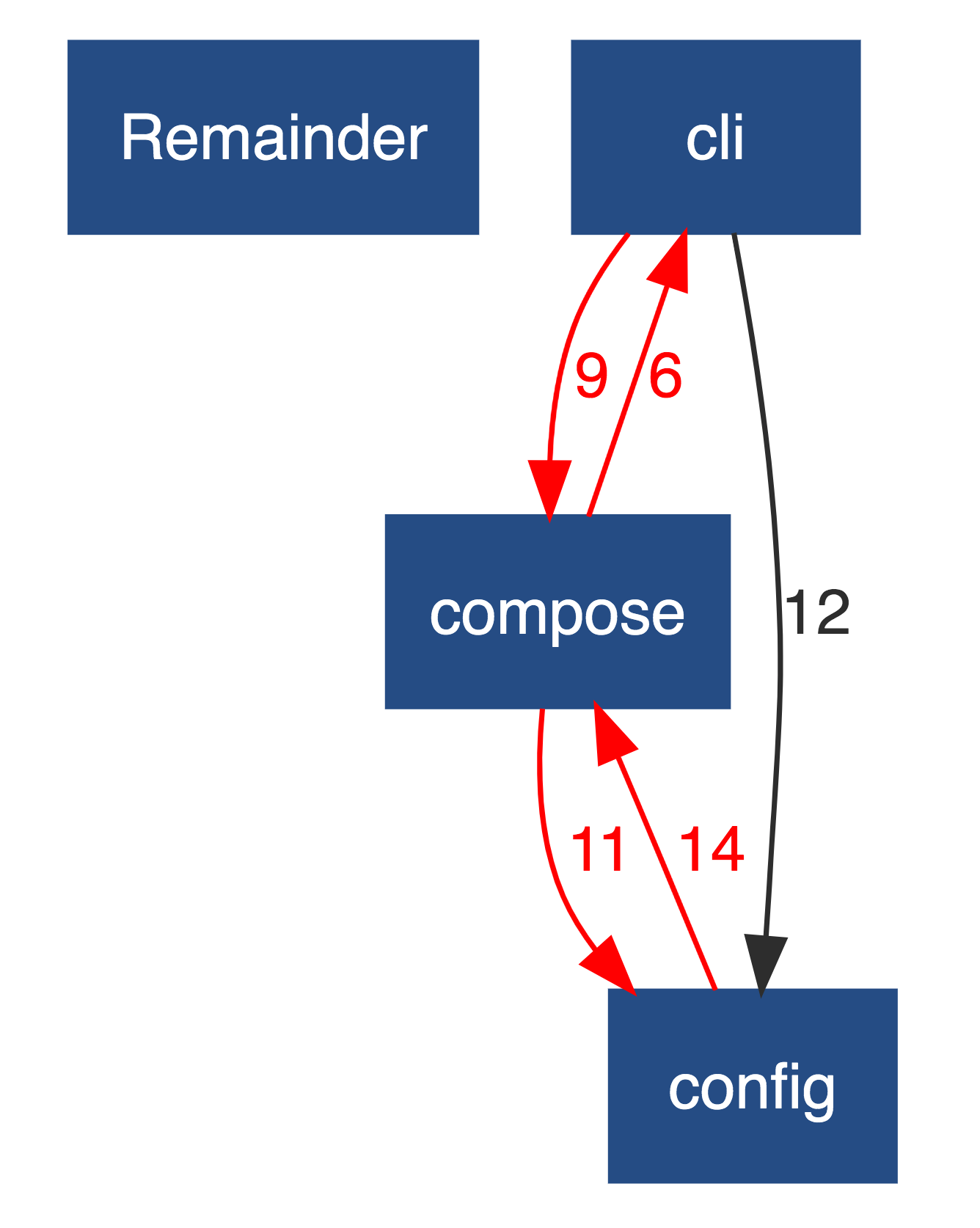
Figure: Compose component entanglement
Unit interfacing score indicates the size of the interfaces of the units of the source code in terms of the number of interface parameter declarations. Approximately 30% of unit in config and cli components have a medium to high-risk score which can be a problem to the code readability (Fig.7). Module coupling score indicates the number of incoming dependencies for the modules of the source code. It might create a problem in making changes to component config as it has quite a huge number of module coupling (Fig.7).
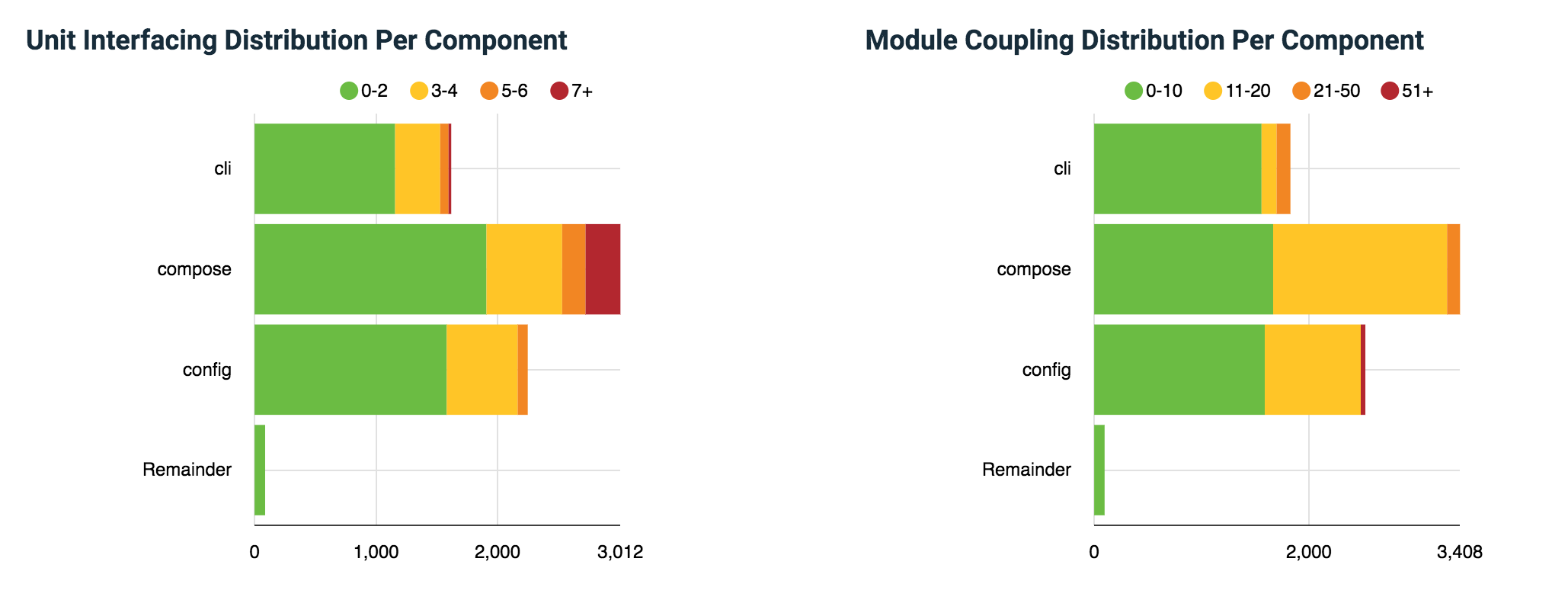
Figure: Compose module and unit interfacing
We look into more detail of the code using SonarCube where we identify some of the code smells within Compose main components. Overall, Compose code smells dominate in the test component while there are only a few detected in the config, cli or compose component. config component itself only contains 14 code smells. Fig.8 shows an example of it where a method Cognitive Complexity score higher than allowed. Cognitive Complexity is a measure of how hard the control flow of a function is to understand. Functions with high Cognitive Complexity will be difficult to maintain 4.
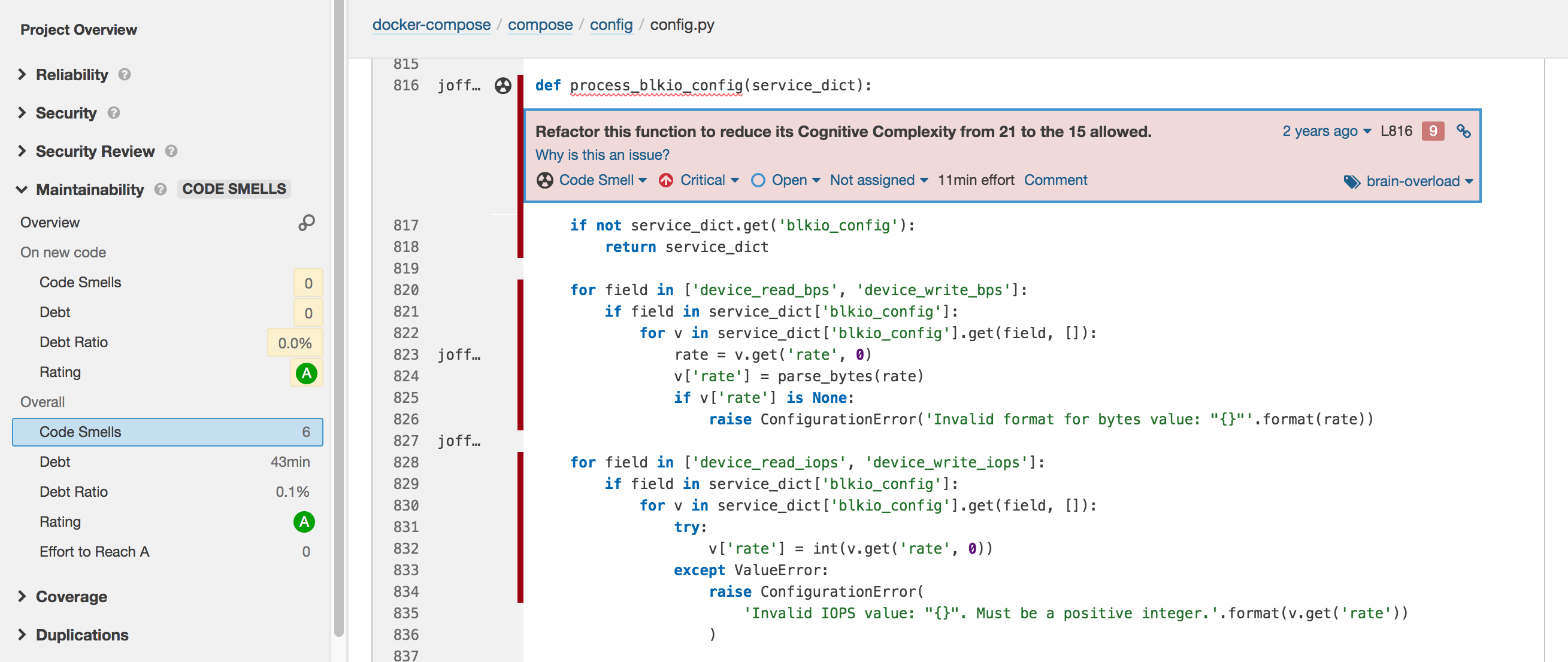
Figure: Compose code smell example
Testing Assessment
The testing environment used by the Docker Compose project is pytest5. The tests are:
These tests are performed by the continuous integration system of the Docker Compose project. All the tests are done using Python 2.7 and Python 3.7, for Alpine and Debian Docker containers.
Each End to End tests a docker-compose.yaml configuration file. The configuration files can be found in the folder /tests/fixtures.
Integration tests don’t test specific docker-compose.yaml config file, but rather test higher-level components like volume, network and service.
Unit tests test smaller components. In this project, there are three subcategories of tests:
- cli: tests regarding parsing of the cli command call
- config: tests regarding parsing of the
docker-compose.yamlor.envconfiguration file - generic: tests that don’t fall in either of those categories.
Test Assessment
SIG system reported the test to code ratio around 200%. This is one of the projects with the highest test to code ratio analyzed in the SIG system for DESOSA 2020.
The lines of code are distributed between test types as represented in the following table. As you can see, the percentages of lines of code are somewhat compliant with the testing pyramid5
| Test type | lines of code | percentage lines of code |
|---|---|---|
| End-To-End | 2951 | 15% |
| Integration | 4765 | 25% |
| Unit | 11207 | 60% |
If we take a look at the coverage percentage (Fig.9), we can see in the following figure that every file in the project receives on average a roughly 90% coverage. The coverage table and the coverage percentage was computed Coverage.py.
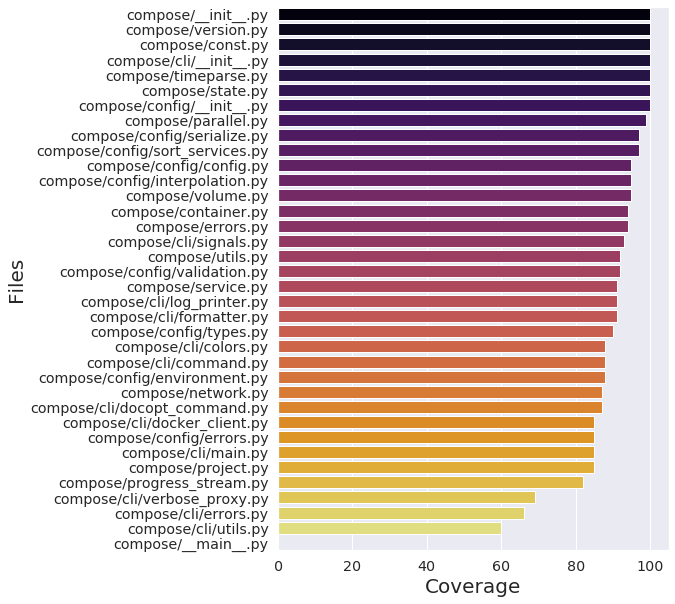
Figure: coverage
Community Awareness
On the discussion in Docker Compose GitHub page, we analyze each of the labels of both open and closed issues and pull requests to indicate the concern of the discussion itself (Fig.10). As seen on figure, label kind/feature and kind/bug sit on top of most discussion indicating most efforts done on improving features and resolving bugs as technical debt, respectively. There also has been some works done on testing improvement (label area/tests) although not as much while none indicate high interest or concern on code quality.
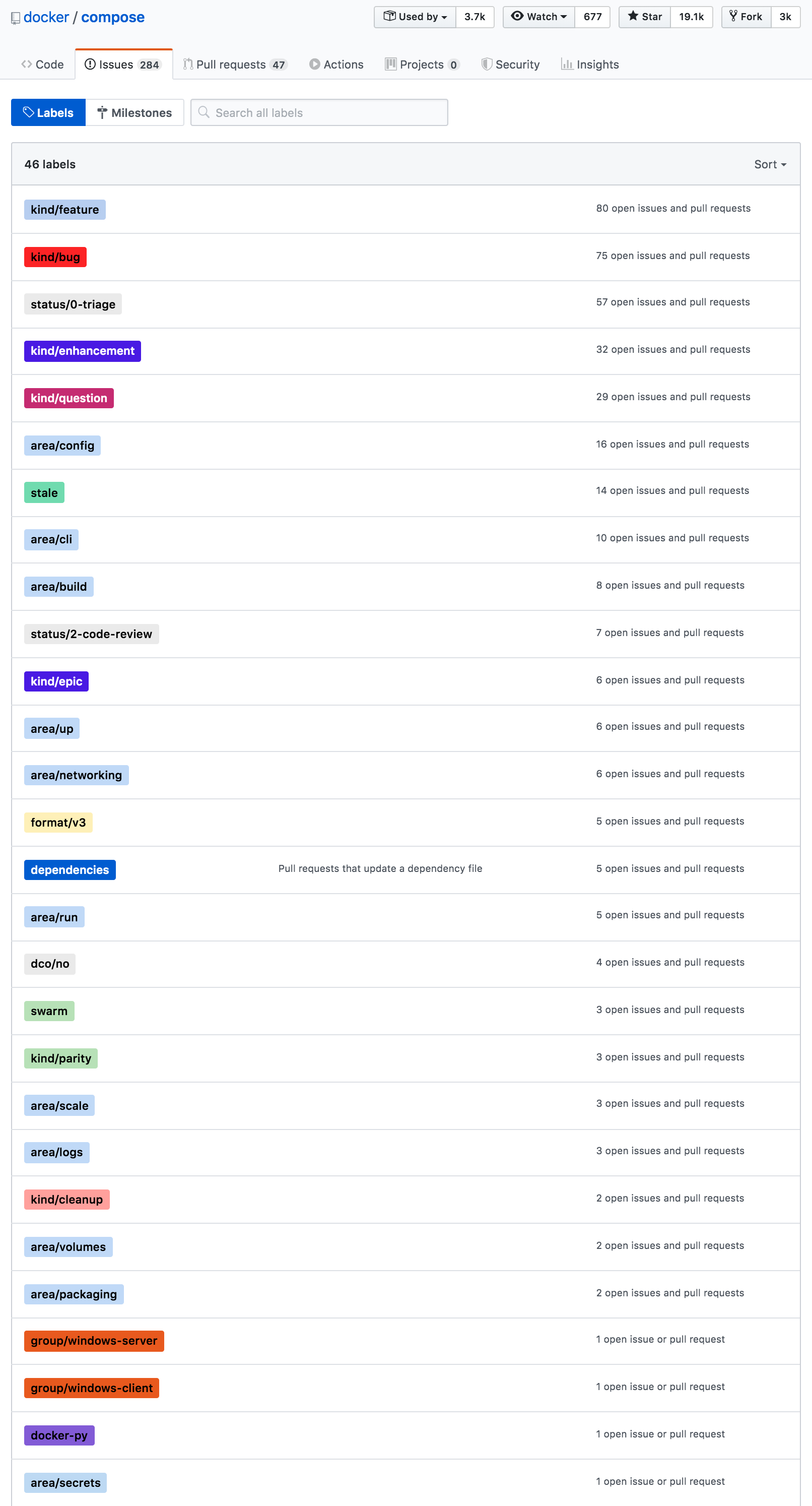
Figure: Compose issues and PRs
Refactoring Suggestions
We use Sigrid to analyze refactoring suggestions.
| System Properties - Units (function/methods), Components | Description | Performance |
|---|---|---|
| Code Duplication | Harder to maintain when fixing bugs and adding changes | 4.9/ 5.0 |
| Unit Size | Desirable to build single responsibility handling units | 2.5/5.0 |
| Unit Complexity | Low complexity means fewer test cases required, easier to understand and fewer execution paths needed | 2.0/5.0 |
| Unit Interfacing | Units with more parameters have larger interfaces thus are harder to modify and error-prone. | 1.6/5.0 |
| Module coupling | Loosely coupled modules are easier to understand, test and change. | 1.8/5.0 |
| Component Independence | Loosely coupling components inhibits changes in one component affecting the other. | 0.5/ 5.0 |
| Component entanglement | Limiting communication lines between components makes it easier to change components in isolation to further extend the architecture | 1.0/5.0 |
Unit size
Since Docker Compose only has a few units, it is expected that the size of these units will be large (Fig.11).
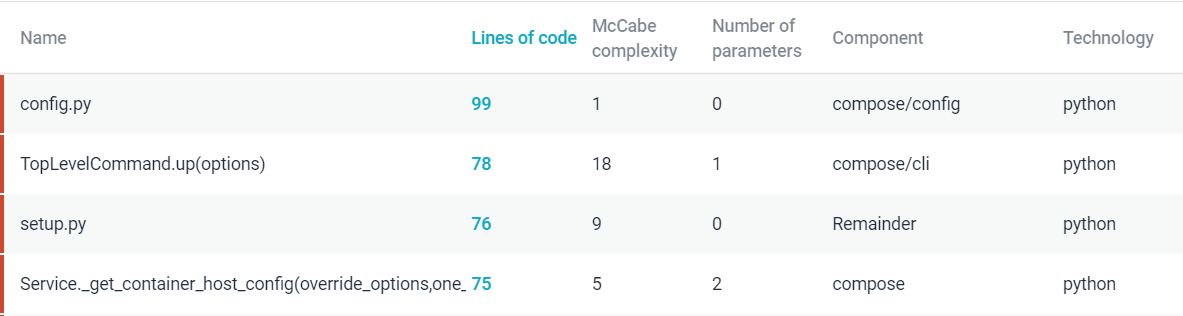
Figure: Unit Size
Unit Complexity
The complexity occurring in cli.py is due to the docker compose up command being able to build, (re)create, start, and attach to containers for a service (Fig.12). These responsibilities can be enabled through multiple command lines instead of one. The next complexity is caused in service.py. A common theme within this service.py file is the lack of abstraction.
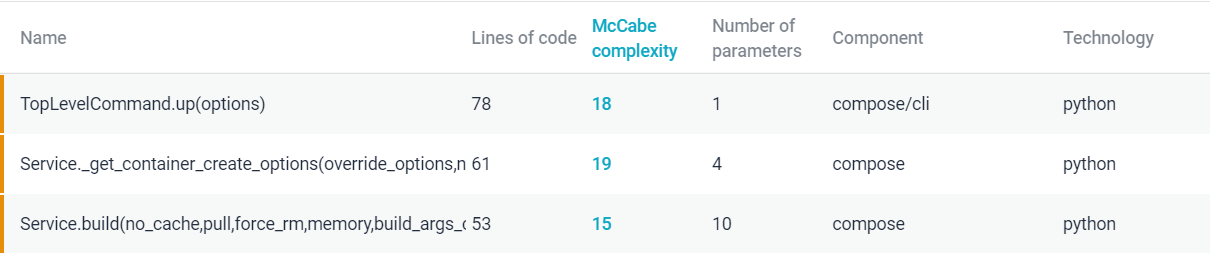
Figure: Unit Complexity
Unit Interfacing
The extensive parameters show up in build functions and functions/methods related to docker compose up (Fig.13).
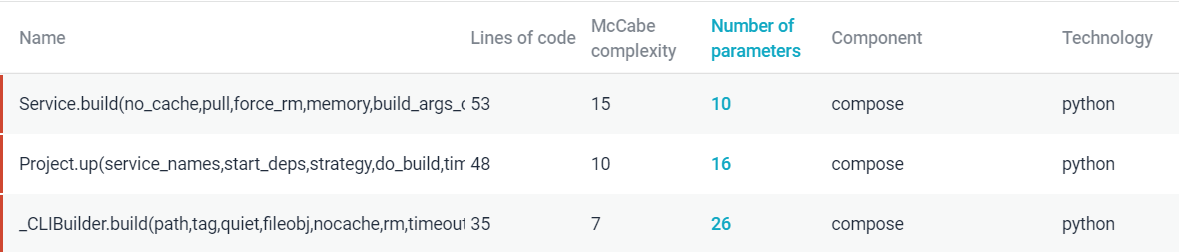
Figure: Component Interfacing
Module Coupling
Errors.py and utils.py have most coupling. This is expected as errors.py and utils.py have most dependencies on other modules. This seems inevitable (Fig.14).
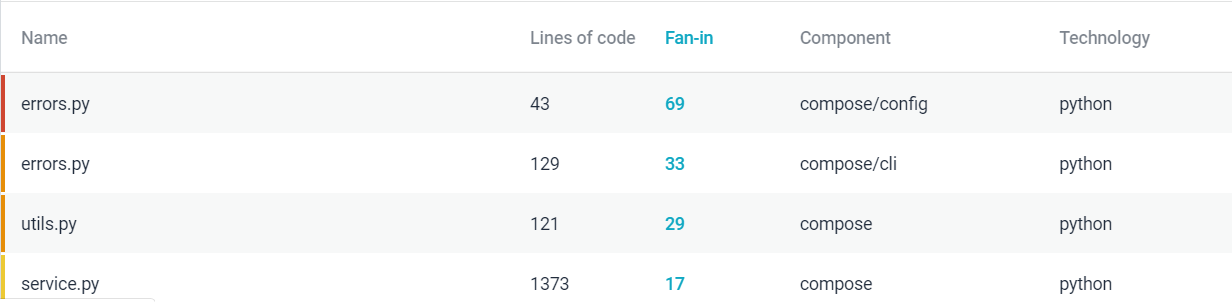
Figure: Module Coupling
Component Independence
Many functions are dependent on the services (Fig.15). A manifestation of this for the end-user is that services are built once, and any change to the service requires rebuilding again. To facilitate component independence, an architectural refactoring seems the best way to go.
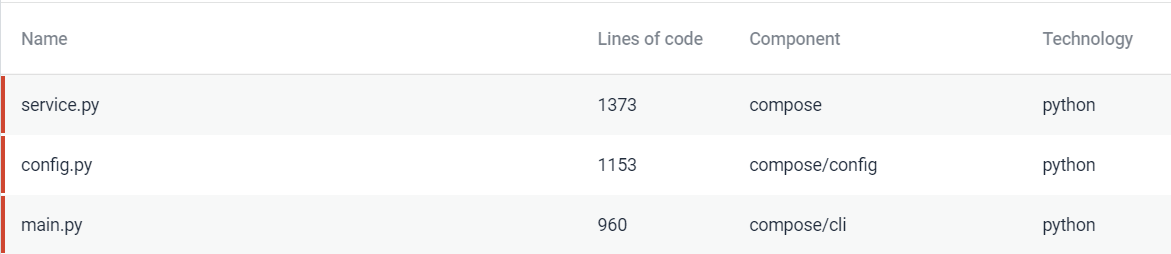
Figure: Component Independence
Component Entanglement
Compose, compose/cli, and compose/config are cyclically dependent on each other. This entanglement is expected due to the monolithic nature of Compose (Fig.16). (See Architectural Refactoring)

Figure: Component Entanglement
Architectural Refactoring
As discussed in the previous essay, Compose is based on a monolithic architecture pattern. To refresh, a monolithic architecture allows simplicity in development and testing at the cost of size and complexity. At some point, the system becomes too large and complex to understand/change.
We suspect that refactoring in this system is not limiting to code refactoring, however, it requires a complete architectural refactoring.
Technical debt present in the system
We refer to an academic definition of technical debt defined as :
“Technical debt describes the consequences of software development actions that intentionally or unintentionally prioritize client value and/or project constraints”
We divide the list of identified technical debts 6 into three categories:
Planned
- Cyclic dependencies between components (i.e. compose, compose/cli and compose/config)
- docker compose up and build functions having large interfaces
Unintentional
- Lack of coding guidelines relating to feature developments
- Lack of testing standards and guidelines
- No testing coverage functionality
- Single Responsibility Principle violated (e.g. in Services.py)
- Lack of abstraction (e.g. increased complexity in units)
Inevitable
- High coupling (i.e. between projects.py, services.py, and config.py)
- Certain components having high complexity
- Components having overall higher dependencies
-
A. F. Nogueira, “Predicting software complexity by means of evolutionary testing,” 2012 Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering, Essen, 2012, pp. 402-405. ↩
-
Bhatti, H. R. (2011). Automatic Measurement of Source Code Complexity (Dissertation). Retrieved from http://urn.kb.se/resolve?urn=urn:nbn:se:ltu:diva-46648 ↩
-
SEI Open System Glosssary. https://www.sebokwiki.org/wiki/Open_System_(glossary) ↩
-
Cognitive Complexity: A new way of measuring understandability. https://www.sonarsource.com/docs/CognitiveComplexity.pdf ↩
-
Just Say No to More End-to-End Tests. https://testing.googleblog.com/2015/04/just-say-no-to-more-end-to-end-tests.html? ↩ ↩2
-
arc42 Documentation. https://docs.arc42.org/section-11/ ↩