Until now, we analyzed Docker Compose from various traditional software engineering dependencies stand points (development view, runtime view, operations view). This does not give us a full perspective of the architectural structure of the project.
In this essay, we will tackle the project from a social perspective.
In Module Coupling, we will tackle Docker Compose modularization, as it is a reflection of the organizational structure of Docker Compose, as stated by Conway’s law 1.
As demonstrated by 2 logical dependencies3 capture a more realistic component dependencies. We will also investigate the methods that Docker Compose uses to tackle coordination. As shown by 2, congruency between dependency and coordination is a major factor for the efficiency of delivery time from a change request. Of course, because we are working in a open-source framework, change requests can be seen as issues. This will be discussed in Developers Communication in Docker Compose.
Finally, we analyze whether Docker Compose code structure is a reflection of the social structure in Docker compose in Effects Between Code and People.
Module Coupling
Why does module coupling matter in this case study?
According to Conway’s law, software structure is a reflection of the organizational structure of its developers. Since Compose only has three high-level components (see previous essays), thus we visualize the structure of lower-level modules within these components.
We use Sigrid to obtain dependencies within modules of Docker Compose. Using this information, we visualize significant components and their dependencies to obtain an idea on the structuring. This can be seen in Figure 1. The colors, green, blue, and yellow, indicate the level of coupling (blue = high, green = medium and yellow = low coupling). The coupling level is determined by Sigrid based on the number and strength of incoming dependencies. A link between two modules indicates a dependency between them, whilst the arrow indicates the direction of dependency. The thickness of a link determines the relative strength of the dependency within the graph so the thicker the link is, the stronger the dependency. It is important to note that segregation of levels and strength are relative to one and other, rather than based on a pre-defined value.
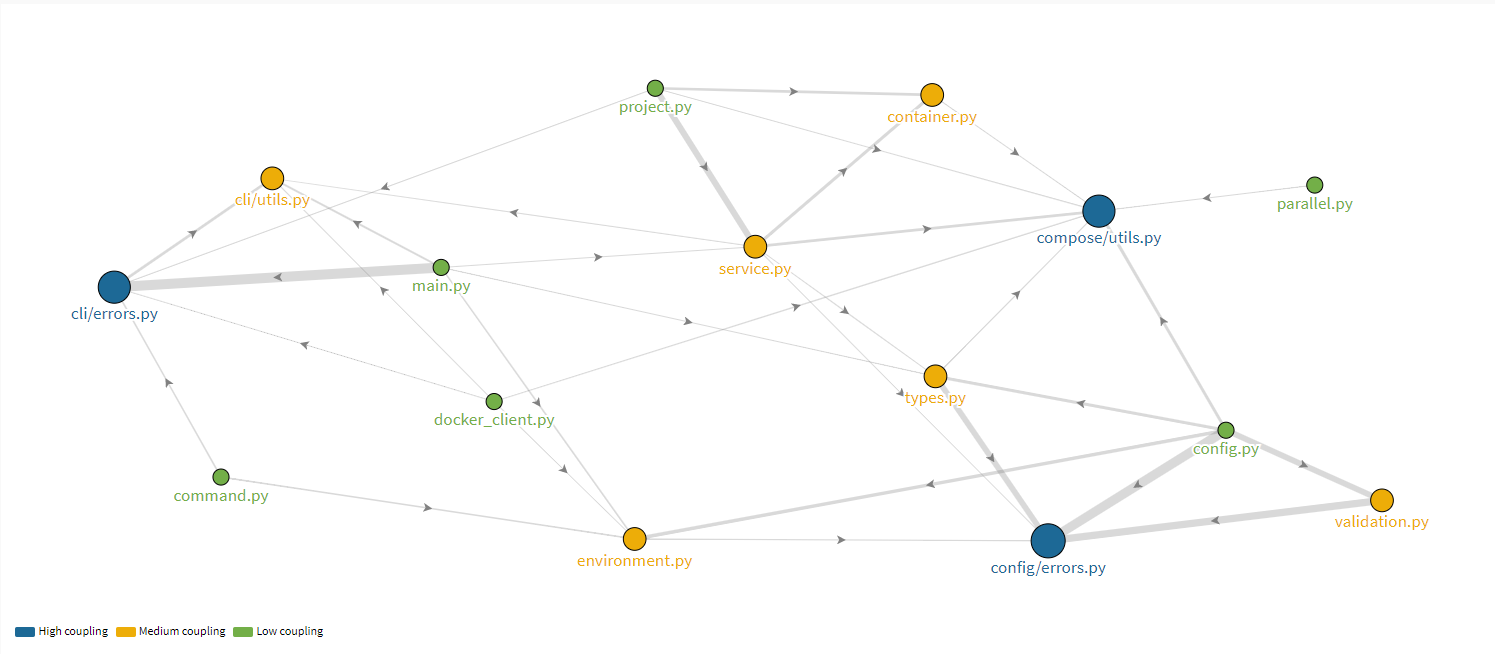
Figure: Overall module coupling structure
Below, we discuss some interesting module couplings we see in Figure 1.
Highly coupled modules
- config/errors.py: Handles errors such as circular references, dependency errors and so on. It is highly coupled with many modules as it defines errors for multiple modules within config.
- cli/errors.py: Handles errors regarding cli module such as timeout, api and connection errors. Most of its coupling is with modules of cli.
- compose/utils.py]: Handles parsing jobs. It is coupled with components from config. The strength of depedencies is lower than config/errors.py and cli/errors.py.
Medium coupled modules
- environment.py: Handles representation of the environment, and parsing the .env file. There is more variation in the number of incoming and outgoing dependencies compared to highly coupled modules. It is directly/indirectly connected to most highly coupled modules.
- container.py: Handles representation of a container. We see a similar pattern of coupling as in environment.py.
- service.py: Handles representation of a service, and building containers related to the service. We see a similar pattern of coupling as in environment.py.
Low coupled modules
- main.py: Responsible for actually defining and running multi-container applications with Docker. It is loosely coupled, which is expected as main.py is only run when absolutely needed.
- config.py: Aggregates all relevant information from config components and processes them.
What can we infer from the structure of the coupled modules?
If we were to view the module coupling as a network, we could easily point out communities and how they are connected. For example, highly coupled modules can be seen as the core of a community (see Figures 2, 3, 4). Medium coupled modules can be seen as community bridges. Community bridges can be interpreted as nodes that efficiently connect different communities. Low coupled modules can be seen as either weak community bridges, or simply facilitating a role within a community.
Why are we suddenly comparing coupled modules with communities/networks?
The organization of collaborators is intuitively characterizable by ideologies such as communities and networks. Therefore, by trying to understand module coupling within Docker Compose through the lens of a network, we aim to guide the reader to the next sections.
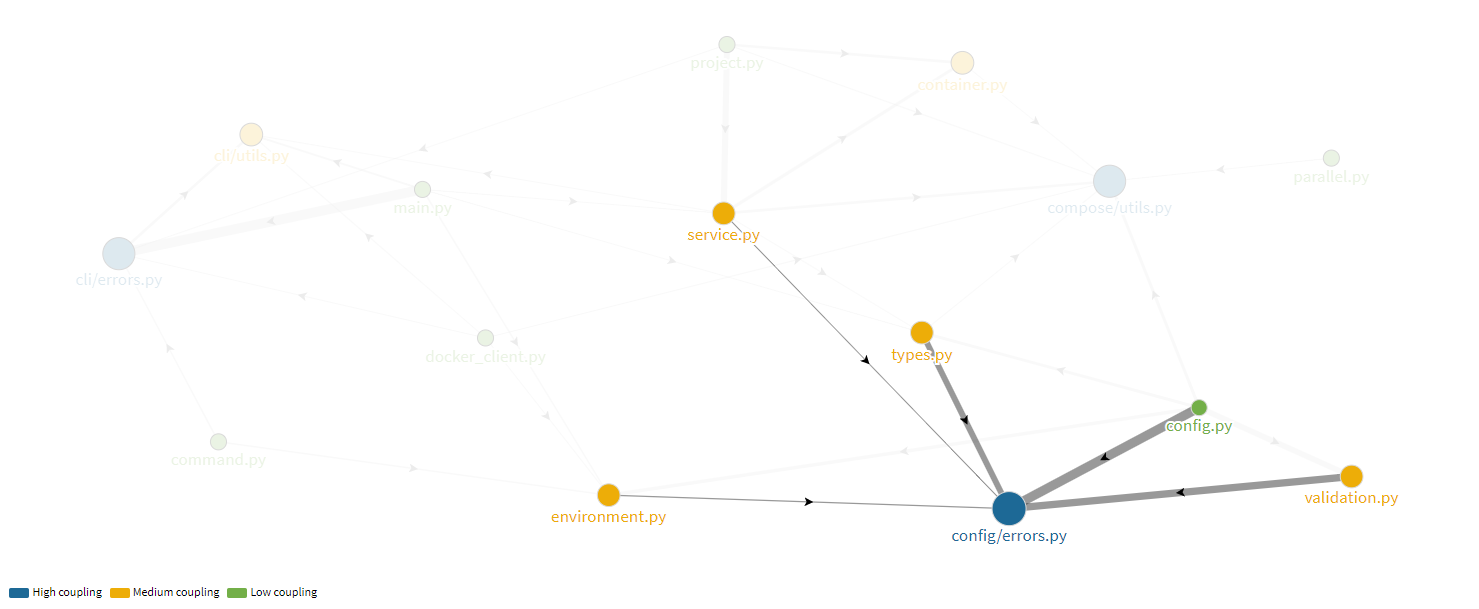
Figure: Module coupling for config/errors.py
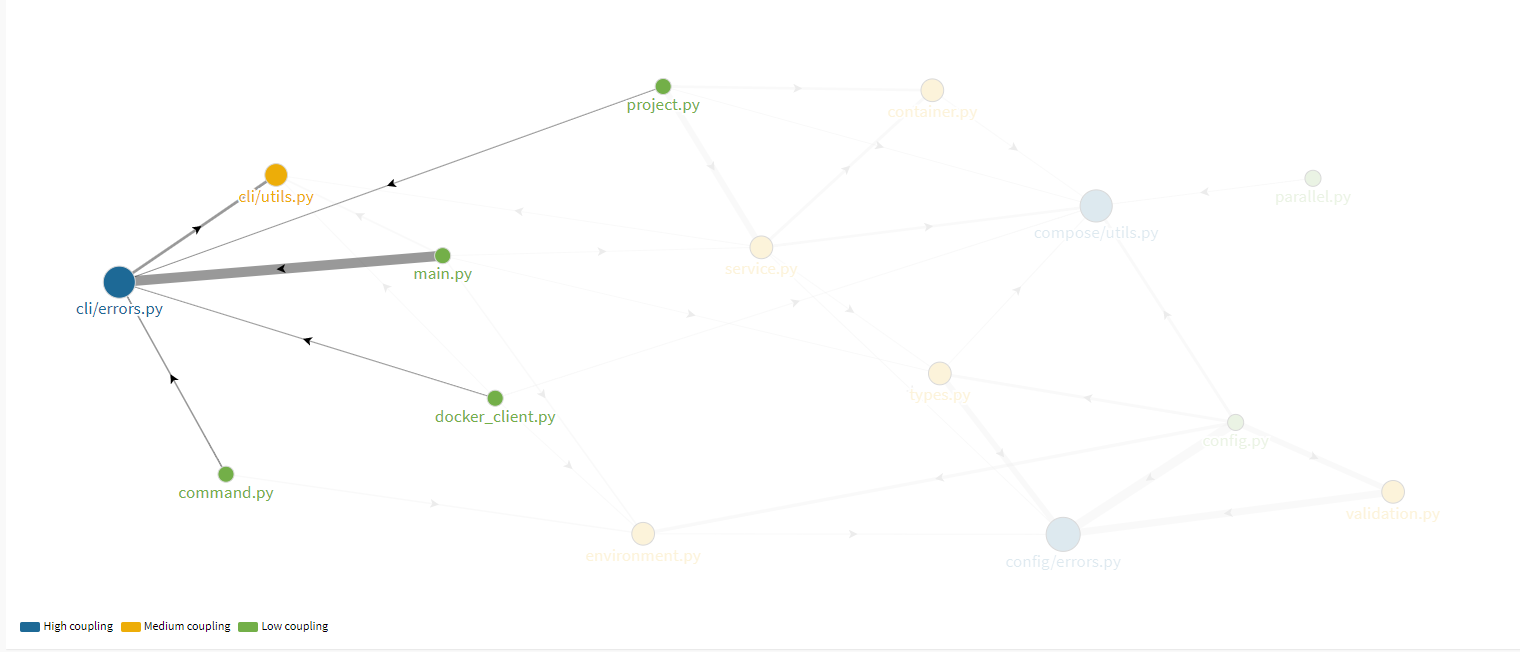
Figure: Module coupling for cli/errors.py
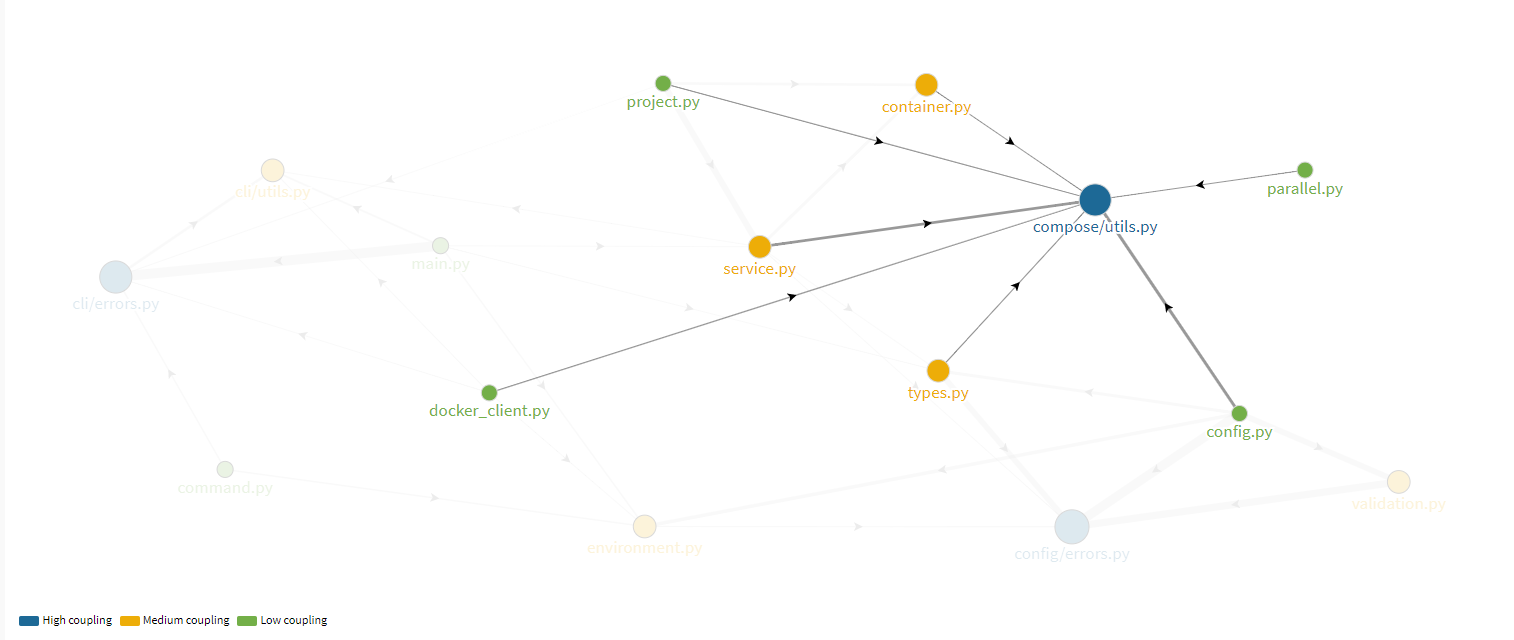
Figure: Module coupling for compose/utils.py
Developers Communication in Docker Compose
How do developers involved in Docker Compose organized? How do they communicate and coordinate with each other?
Docker Compose communication consists of two public channels; Github and Slack. Slack is more about Q&A on the user side of Docker Compose, and Github is where the developer’s communication happens. Inside Docker Inc, developers rotate teams in the Docker Ecosystem (check our interview with Sebastiaan van Stijn for more details), but they follow the communication methodology described in Figure 5.
GitHub is the main channel, where communication spins around issues supported by a short description, with a blog-style discussion system provided by Github that allows sequential order of comments, and a well-defined tagging system customized by the Docker team. To keep this channel active, response times, and tracking of activity done by the contributor manager and response times by Docker developers play a significant role.
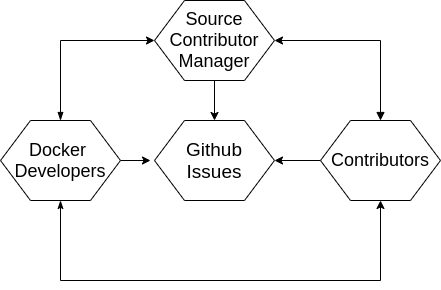
Figure: Communication spins around issues
Issues could be of different kind:
Docker Compose developers also open up their discussions to the public where we can read about their ideas and challenges regarding an issue and follow an agile process. For example, take a look at this epic and this issue regarding a feature.
The rules become more strict and follow a well-defined process described in the contributing guideline. One of the most significant moments is the merge request, which contains a code review. Merge requests might open a conversation where contributors and developers together discuss the solution.
Click me to see how a merge Request looks like!
To summarize, the most interesting aspect of the communication in Docker Compose is that with clear guidelines, test coverage, and constant community management is possible to have over the life of a system different team members and external contributors working together. The positive effect of this methodology is that it allows collective code ownership or shared code and an increase in Busfactor.
Finally, we think that the engineering of this system, mainly the continuous integration pipeline, and test coverage are the elements that allow a clear communication process with the rotation of developers as they ease coordination, particularly with external contributors.
Effects Between Code and People
Is there a relationship between Compose code system design and the organization of the people itself?
Inevitably, a system organization is highly affected or affecting the organization of the people involved. Conway’s Law 1 explained that the choices made by people from the organization before and when designing any system often fundamentally shapes the final output of the design. Conway view a system of both code and people can be illustrated by this linear graph shown in Figure 6. As stated from Conway’s paper 1, this linear graphs provides an abstraction which has the same form for the two entities we are considering: the design organization and the system it designs. A system is a commitee in the people organization, while subsystem represent subcommitte and interface is a coordinator of the subcommittee.
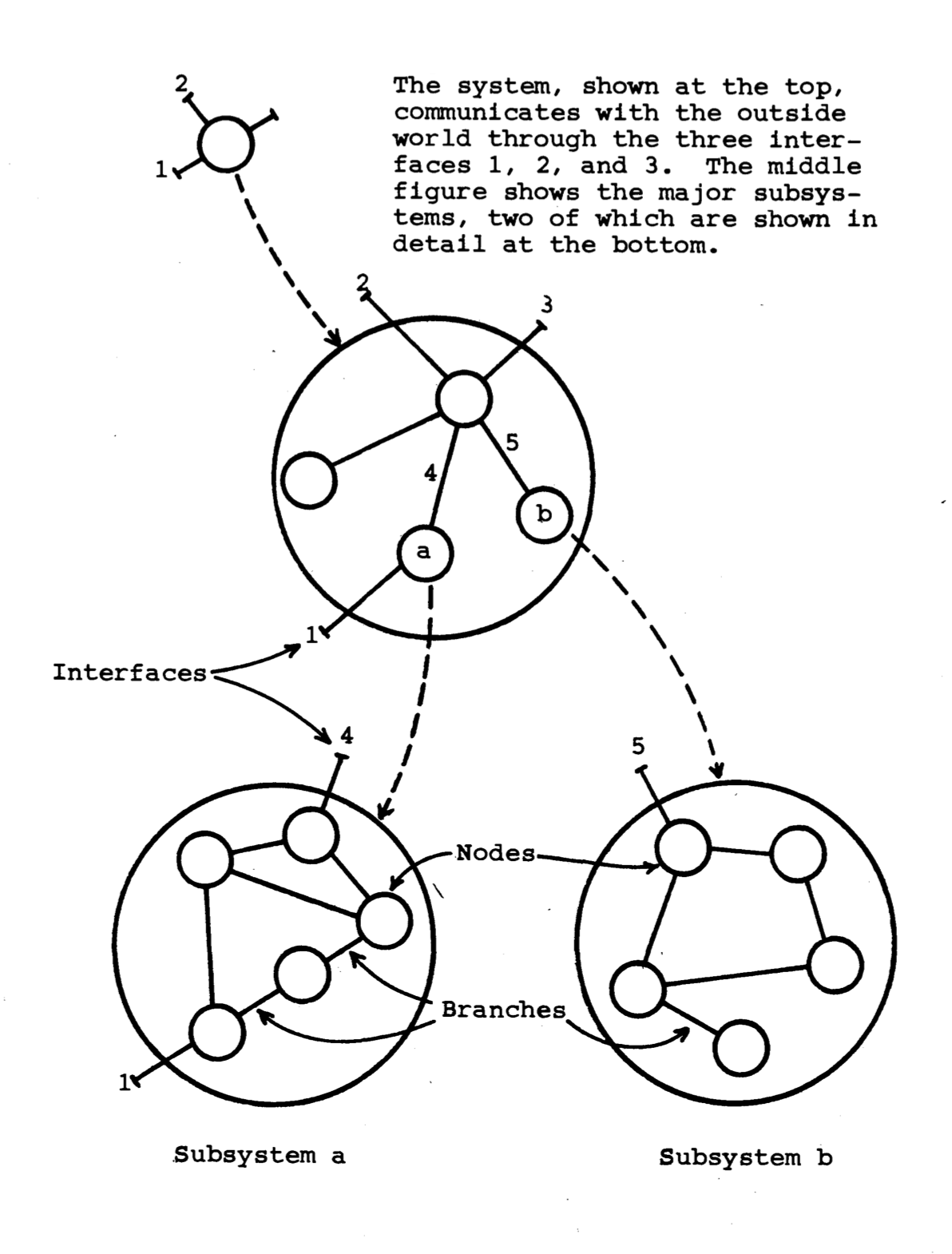
Figure: Conway's Linear Graphs
If we compare the two network graphs of the code modules organization coupling and developers communcation from previous section above, we do not see any similarity in these two graphs. As the main code components of Compose are cli, config and compose, these importance should somehow reflected in the communication system of Compose’s developers that includes the contributors. From the code system perspective, the importances are also not represented because on each main component the high coupling centered around part of code that functioning on error configuration. Analyzing this using Conway’s principle, this fact about code coupling are delivering a message that errors are the main concerns of the organization while that is not true.
However, we don’t see the way that the developers are organized is following Conway’s principle as it is not a representation of the Compose’s system design. This might also be the reason of why there’s a faulty in the coupling of the modules because the developers communication network is not aligned with the Compose system design itself. The subcommittees, namely Source Contributor Manager, Contributors, and Docker Developers, doesn’t follow the organization in the Compose system code. We don’t see any coordinator specifically assigned for each subcommittess as well. The main coordination is held by the role of Source Contributor Manager (that now consist of 3 people) through GitHub issues discussion and pull request reviews.
Although, we see a small representation of Compose components and modules in the way the Github Issues are organized through labels as shown in Figure 7. Still, these labeling systems does not entirely sync up with the Compose modules. There’s a label area/packaging that covers a different type of concept around the system that is not code modulation because there are no particular code module designed to handle packaging.

Figure: Compose Github Issues Labels
The code contributing guideline only communicates the general coding guidelines and not particularly about how code should be organized between modules and components. So we see that lack of communication around how source code should be correctly organized leads to things such as false module coupling.
-
Conway, M. E. (1968). How do committees invent. Datamation, 14(4), 28-31. ↩ ↩2 ↩3
-
Cataldo, M., Herbsleb, J. D., & Carley, K. M. (2008, October). Socio-technical congruence: a framework for assessing the impact of technical and work dependencies on software development productivity. In Proceedings of the Second ACM-IEEE international symposium on Empirical software engineering and measurement (pp. 2-11). ↩ ↩2
-
Gall, H., Hajek, K., & Jazayeri, M. (1998, November). Detection of logical coupling based on product release history. In Proceedings. International Conference on Software Maintenance (Cat. No. 98CB36272) (pp. 190-198). IEEE. ↩