Software can be viewed from many angles. Ask a developer and a user what they think about some software product and you’ll probably get not only contradictory answers, but even uncomparable answers. This is because they look at the software from such a different point of view.
This is the second part in our four part series on Gatsby. In the first post1, we wrote about what Gatsby is and where it is going. In this post, we will take a moment to explore the multiple architectural views of Gatsby. If you haven’t read the first essay yet and you’re trying to get a grasp on the system, this would be a good time to go and read it.
Before we move into the specifics, it’s a good idea to get a basic understanding of the architectural style of Gatsby.
The Gatsby project actually is a combination of many small packages bundled in
one monorepo using Lerna2. These packages can be
classified as follows: first there are a couple of core packages, including
gatsby and gatsby-link. Then, there is the command line tool: gatsby-cli.
Finally, most of the packages are plugins like gatsby-source-wordpress and
gatsby-plugin-feed.
The gatsby package itself uses the flux-pattern3 with redux4. A widely used
pattern for unidirectional data flow in applications. One cool side note,
it also uses a formal turing
machine5!
Now that we have the basics in place, let’s find some interesting viewpoints. For our viewpoints we are inspired by Rozanski and Woods6, offering valuable insights into the system. Since Gatsby focusses a lot on developer experience (DX), the development view is a good place to start. Followed by the reason that Gatsby sites are fast, is that it does most of the heavy lifting in its build process, before a user ever gets to see the site, we describe this process from a runtime perspective. Next, as Gatsby wants their sites to be deployable anywhere (and fast), we will look at it from a deployment view. Finally, we will zoom out a bit and look at non-functional properties and the tradeoffs that Gatsby has made.
Development view
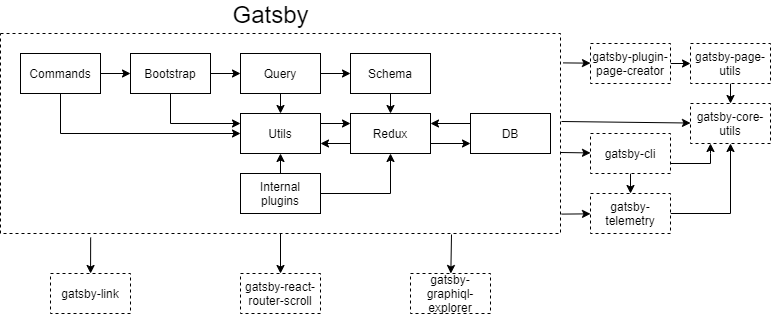
When exploring the Gatsby repository, you will quickly discover that all the code is contained in a directory named packages. This folder currently contains 109 packages. A lot of these are packages are plugins. They will be discussed further in the runtime view section . The most important package, simply called gatsby, contains an architecture of its own. We explored this architecture using a tool from Software Improvement Group7 and found the structure as seen in the diagram above. The gatsby package contains core code for the command line interface and uses Redux4 for state management. The packages outside the box were found by manually inspecting each package package.json file.
The gatsby package also makes use of other packages within the Gatsby repository, such as gatsby-link, which is used by Gatsby sites for internal communication. Some other packages are also worth exploring. Take for example the gatsby-cli package which controls the command-line interface. Or gatsby-telemetry, collecting analytical data regarding user interactions.
Runtime view
In running Gatsby, there are two key scenarios: gatsby develop and gatsby build. These command-line commands share a lot of their functionality. Both processes compile your project into static files. A detailed schematic for the build process can be found here8, but the basic process is as follows:
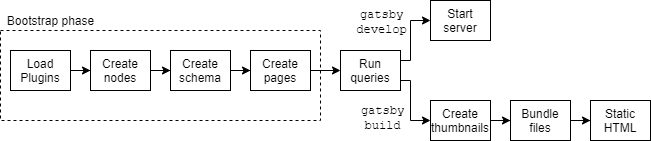
First, the gatsby plugins are loaded. Gatsby plugins can be divided into two types: source plugins and transformer plugins. Source plugins fetch data from some data source, such as the file system, or some REST API. Next transformer plugins are used to transform the raw data into something more useful. In the following step, every plugin creates one or more Nodes, forming the center of Gatsby’s data system. The nodes are sewn into a GraphQL9 schema, and plugins can control which nodes are turned into pages.
Next, all the queries (data requests to the GraphQL schema) defined by all the pages are run. At this point, all the data is at the place it needs to be. With gatsby develop, a local web server is started that allows hot reloads whenever the source files change. With gatsby build, a production build is created. This includes creating image assets of different sizes, bundling Javascript and CSS files using webpack, and finally producing the static HTML files to be deployed to a static hosting service.
Deployment view
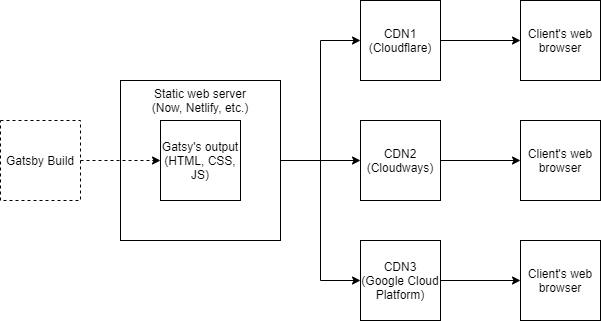
As described in the first essay1, Gatsby does not host websites made with Gatsby.
To deploy Gatsby an external web server is needed. With the gatsby build
command, as discussed in the runtime view, output is created. The output contains
HTML, CSS and JavaScript that is directly usable by the browser. To get these
files to the browser, an server system is required. You could get away with an
ordinary http server. However there are some more modern ways that are
recommended by Gatsby. Gatsby promotes the use of static web servers like
Netlify10, Now11 and others12. These platforms automatically perform
builds and distribute the static content over CDNs like Cloudflare13].
Via the CDN of choice, the Gatsby project reaches its final destination,
being a blazing fast website on a client’s web browser.
Non-functional properties
In the previous sections we have seen how Gatsby compiles dynamic React apps into static websites, with all external data baked into them.
This approach has some large positive consequences: For one, to access a Gatsby website, no database is contacted. This makes Gatsby websites secure by default. Also, and this is a core benefit of any website built using the JAMStack, Gatsby websites can be served over any CDN. This allows for near unlimited scalability in the amount of users.
The approach Gatsby took also has one big disadvantage. The Gatsby compiler currently compiles complete websites. Even when an editor made a single change in a CMS that should only impact one single page. This becomes a problem for large sites, with frequently changing content. Gatsby is however working towards a build time, even for huge websites, of less than 10 seconds14. Their largest current effort in this is incremental builds15, which is currently in private beta.
Conclusion
This exploration of the Gatsby project from different angles gave us a huge insight into the project, and we hope it did the same for you. In the next post, we will dig deep into the system decomposition of Gatsby to assess the project’s quality and to uncover the technical debt there… Stay tuned!
-
https://desosa2020.netlify.com/projects/gatsby/2020/03/09/the-great-gatsby.html ↩ ↩2
-
https://lerna.js.org/ ↩
-
https://facebook.github.io/flux/ ↩
-
https://github.com/gatsbyjs/gatsby/blob/master/packages/gatsby/src/redux/machines/page-component.js ↩
-
https://books.google.nl/books?id=ka4QO9kXQFUC&printsec=frontcover&hl=nl&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false ↩
-
https://www.softwareimprovementgroup.com/ ↩
-
https://www.gatsbyjs.org/docs/gatsby-internals/ ↩
-
https://graphql.org/ ↩
-
https://www.gatsbyjs.org/docs/deploying-to-netlify/ ↩
-
https://www.gatsbyjs.org/docs/deploying-to-zeit-now/ ↩
-
https://www.gatsbyjs.org/docs/deploying-and-hosting/ ↩
-
https://www.cloudflare.com ↩
-
https://www.gatsbyjs.org/blog/2020-01-27-announcing-gatsby-builds-and-reports/ ↩
-
https://www.gatsbyjs.com/incremental-builds-beta/ ↩