In this second article in a series of four, we, four Computer Science master students from Delft University of Technology, continue our pursuit to analyse the open-source project GitLab. In our previous article, we discussed the fundamental concepts and product vision of GitLab. In this article, we will dive deeper into the key architectural elements of the system to gain a better understanding how these concepts and visions were realised.
GitLab’s mission is to enable everyone to contribute1. But are we able to see this back in its architecture? To find out, we will first take a look at general architectural views on software systems and elaborate why these are relevant for GitLab. Next, we will dive deeper into the architecture of GitLab itself and how the different architectural views influence its design.
Architectural views
An architectural view, as described by Phillipe Kruchten’s “The 4+1 View Model of architecture”2 (later standardized by IEEE Standard 14713) is used to “address a specific set of concerns of interest to different stakeholders in the system.”
In their book4, Rozanski and Woods continue on Kruchten’s work and present “seven core viewpoints for information system architecture”. They define a view as follows: “A view is a representation of one or more structural aspects of an architecture that illustrates how the architecture addresses one or more concerns held by one or more of its stakeholders”. So, a view should show stakeholders how the architecture addresses their concerns. In short, all viewpoints are relevant to GitLab. To see why, we will briefly look at how each applies to the project.
GitLab is made by and for developers, and developers are part of all the stakeholder groups of the project. The system interacts with developers and other systems, like the CI runners that users can host themselves, to function. Having an overview of GitLab’s relationships, dependencies and interactions with its environment is therefore helpful. Within GitLab, different components interact with each other. Databases, web interfaces and Git itself are some of the basic elements of GitLab that help it function. To know how these elements can be interacted with positively influences the system’s ability to change. To ensure GitLab functions quickly for everyone in its large userbase, parts of its functionality can run concurrently, such as the web interface. This helps decrease waiting time, and overall increases performance for both the systems and its users. Identifying the components that can run in concurrency is vital for the developers to coordinate. From this we can see that the Context, Functional and Concurrency viewpoints are relevant to GitLab.
Code version control is the cornerstone of GitLab. Whenever a file is created, edited or deleted, the information describing this must be stored and maintained somewhere. Besides this, GitLab itself provides users with the ability to create issues, merge requests, labels and comments, which all must be stored and displayed. As information management is important for the functionality of GitLab, describing how the system does that is essential. The Information viewpoints is therefore relevant.
The Development, Deployment and Operational viewpoints are discussed in greater detail in the following sections, where we can see why they too are relevant to the project.
Developers first
The design philosophy of Ruby on Rails, the framework GitLab is built upon, has two main principles; ‘Don’t Repeat Yourself’ (DRY) and ‘Convention over Configuration’5. The first implies one should not write duplicated code to improve maintainability and stability. The latter comes from the fact that Ruby on Rails has strong assumptions about the needs of developers and enforces certain conventions. As Sid Sijbrandij, CEO of GitLab, illustratively said “… in every kitchen you enter, you never know where the knives and plates are located. But with Ruby on Rails, you enter the kitchen and it’s always in the same place …” 6. A tool like Ruby on Rails is exactly what GitLab needs to accomplish its mission to enable everybody to contribute. In this section we will see how this framework affects the applied architectural patterns and we will decompose the system into its main modules.
Software decomposition
In 2016, DESOSA7 explained and visualised the Model-View-Controller architecture which GitLab inherited from Ruby on Rails. Since then, small changes to the architecture has been made which are visualised in the system decomposition below. The differences are visible in the Controller module where Serializers, Uploaders, Presenters and Policies are added, and in Model where Graphql is added.
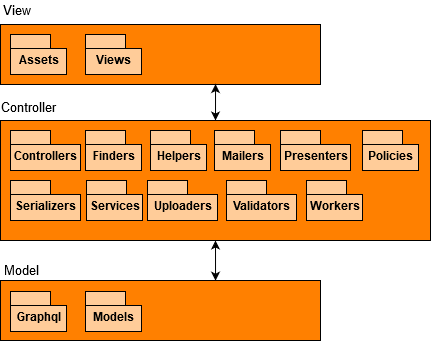
System decomposition illustrating the Model-View-Controller architecture of GitLab anno 2020.
The addition of the Graphql package in the Model module is explainable by the current transition from using the current REST API towards the usage of Graphql, an open-source query framework for APIs aiming to reduce the number of requests developed by Facebook.
Each other new module is created to improve the architecture. Uploaders, Policies, and Serializers are designed to apply business logic easier. For example, the latter is used to apply business rules on the conversion from models to exposable JSON. Presenters contain the view related logic extracted from the models to adhere to the single-responsibility principle.
Performance second
Ruby and Ruby on Rails are both designed with ease of use of the developers in mind8. Since they are not optimized for performance, systems built upon these technologies have significant overhead. However, to keep contributing to GitLab as convenient as possible, new components are first built in Ruby on Rails. When scaling and/or performance issues arise changes can be made6. This leads to the majority of GitLab still being developed in Ruby on Rails and small parts being optimized. Examples of this are the usage of the Vue JavaScript framework for frequently accessed pages and rewriting parts in more performant or memory-efficient languages like Go.
In this section we will provide examples where the non functional requirement of ease of development in Ruby on Rails has been exchanged for performance. The lifecycle of an HTTP request during runtime will be used to illustrate how the system behaves.
Scaling horizontally
One concrete example of an architectural decision made to improve the performance of GitLab is the development of Gitaly, which is a service performing all git operations through Remote Procedure Calls (RPC). Making a separate service responsible for the git operations, enables GitLab to scale both the backend and Gitaly separately and horizontally. In the beginning this was only scalable vertically. Because of the use of a complex Network File System (NFS) it became horizontally scalable9. However, the usage of a NFS introduced a lot of overhead causing too much latency. Gitaly is developed just like GitLab by the company and the open-source community.
Another example is the development of GitLab Workhorse, which started as a side-project to address timeouts caused by long operations and became the handler of all HTTP requests 10. Earlier on, the nginx webserver directly served static content and redirected all other requests to the Ruby backend served by Unicorn. Unicorn provides lots of useful features but also requires low timeouts. This became a problem and caused lots of timeouts while cloning a large repository and downloading files.
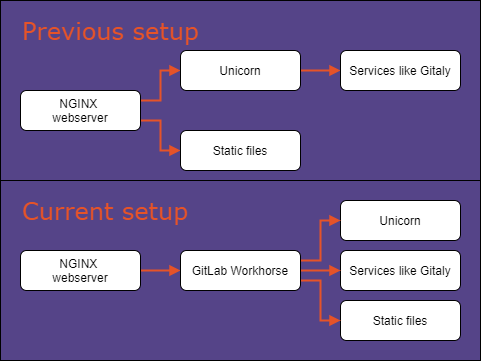
Schematic overview of the situation before and after the introduction of GitLab Workhorse.
Lifecycle of an HTTP request
In the current setup with GitLab Workhorse in place, all HTTP requests are forwarded from the ngnix webserver to the service. It then directly serves the static content, forwards HTTP(S) git commands to Gitaly and preprocesses requests for the GitLab backend. Let’s take a detailed look at what happens with the latter two types of request are received by this system.
1) Web requests received by the GitLab Workhorse are forwarded to the Unicorn ruby webserver. This webserver calls the corresponding controller which could interact with the database via the model definitions, services like Gitaly and returns a view. 2) Git commands, sent by for example git clients, are not forwarded to the backend. Instead, solely the credentials are verified with the backend and the commands are directly forwarded to the Gitaly service which processes it.
And finally, deployment
GitLab is a large system composed of many different components, some we have seen in the previous section. It is also deployed by a large variety of users with different hardware. To make the deployment easier, GitLab provides docker images for popular cloud computing providers like AWS and a package including all services, called Omnibus. Although most of the features of GitLab are dogfooded by the company, it is noticeable that these deploy tools are not used for the public website. This is due to the enormous size of gitlab.com. In this section, we will look at the Omnibus and why GitLab releases every 22nd of each month. We will not go into detail why the deploy tools are not used for the website, but more information about the cloud architecture can be found in the documentation.
The Omnibus
From the outside GitLab might be seen as a single software system, but when looking under the hood, you will see it consists of different servers, databases and other (in)dependent components. To manage and configuring these, GitLab has developed the Omnibus. The Omnibus packages all the services GitLab consists of and publishes them as a single application. This provides a much faster development workflow as it prevents spending a lot of time on configuring all components.
Monthly release schedule
Another way in which GitLab ensures velocity in it’s development, is their monthly release cycle on the 22nd of each month. This time-based release cycle has several advantages. First of all it provides updates via a predictable schedule, which is a must for distributed software systems. Users of the software need to be prepared for possible process breaking updates and should have the choice to stay at a current working version. Another advantage is that a monthly release cycle gives the development a cadence11. This ensures that developers can see the results of their hard work within a month, which has a big impact on morale. Furthermore, it helps with planning team capacity and ensures transparency to external contributors to the open-source code base.
Wrapping up
In this article, we looked at the model-view-controller architectural components of GitLab and the way trade-offs between non-functional requirements like performance and ease of development are made. Some case studies, about Gitaly and GitLab Workhorse, where performance is chosen over ease of development are given together with the approach GitLab uses to make deployments easier. Next time, we will look at the way GitLab ensures the quality of their system and the safeguards they have in place to enforce that.
-
https://about.gitlab.com/company/strategy/#mission ↩
-
Philippe Kruchten. The 4+1 View Model of architecture. IEEE Software 12(6), 1995. ↩
-
https://standards.ieee.org/standard/1471-2000.html ↩
-
Rozanski, Nick, and Eoin Woods. Software Systems Architecture: Working with Stakeholders Using Viewpoints and Perspectives. Addison-Wesley, 2012. ↩
-
https://guides.rubyonrails.org/getting_started.html ↩
-
https://about.gitlab.com/blog/2018/10/29/why-we-use-rails-to-build-gitlab/ ↩ ↩2
-
https://pure.tudelft.nl/portal/files/8039977/desosa2016.pdf ↩
-
https://phptoruby.io/ruby_history/ ↩
-
https://about.gitlab.com/blog/2018/09/12/the-road-to-gitaly-1-0/ ↩
-
https://about.gitlab.com/blog/2016/04/12/a-brief-history-of-gitlab-workhorse/ ↩
-
https://about.gitlab.com/blog/2018/11/21/why-gitlab-uses-a-monthly-release-cycle/ ↩