In our last article, we looked at the architectural decisions made during the development of GitLab. The vision behind most decisions was to enable everybody to contribute. This time, we will look at the different methods used to maintain high-quality standards for a software project where everybody is invited to contribute. Furthermore, we will investigate the project in detail to highlight potential points of improvement.
Quality processes, workflows and guidelines
As we have discussed in previous articles, anything under development at GitLab has this peculiar meta-characteristic to it that it will also be used for developing GitLab itself. A result of this is that they not only build tools to improve the software quality processes for their customers, but also for themselves. In this section, we will give an overview of the software quality processes that are deployed in the development of GitLab. This will be divided into their automated processes such as continuous integration and manual processes such as code reviews. This section will furthermore cover GitLab’s testing policies and the overall quality that results from these processes.
Code reviews
Each contribution, either made by an employee of GitLab or the open-source community, must be reviewed before it is merged to ensure it is up to standard. These reviews are performed inside the GitLab web application and consist of two steps1. First, a reviewer is asked to generally review the contribution on the code level. After the feedback of the reviewer is resolved by the contributor, the reviewer approves the changes and assigns the merge request to one or more maintainers. They are responsible for the affected parts of the codebase and are allowed to merge.
As there are several maintainers for different parts of the backend, it can quickly become difficult for a contributor to determine who to ask for a review for all the involved parts. GitLab solved this with the creation of ‘Reviewer Roulette’. This tool analyses the merge request and suggests a reviewer and maintainer for each part of the backend with changes. The reviewing workload is spread over all maintainers by taking into account the number of recent reviews.
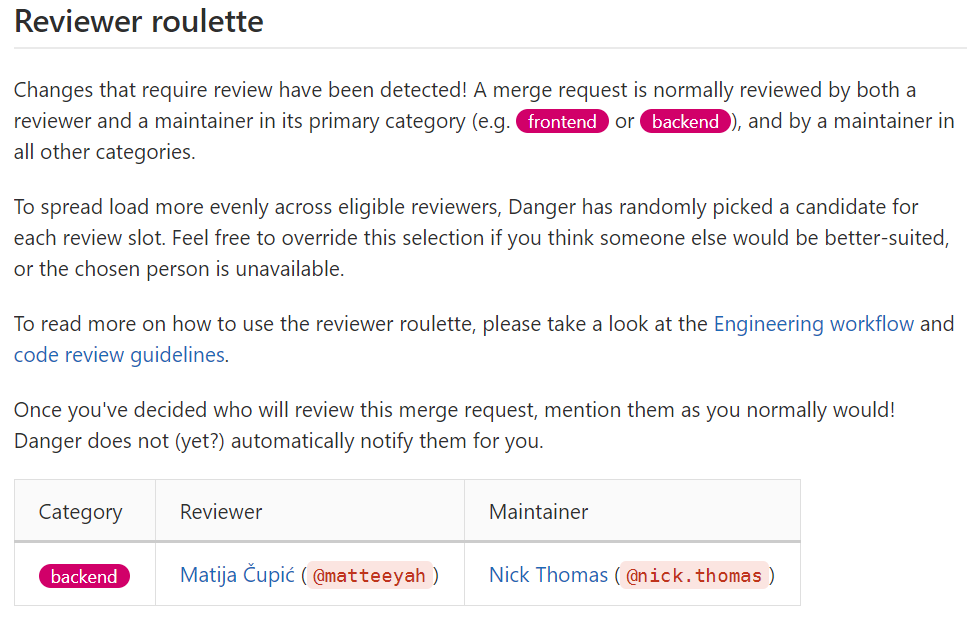
Real-world output of ‘Reviewer Roulette’ on a recent merge request.
Continuous integration
An example of dogfooded tools are the continuous integration and delivery pipelines of GitLab. They assist the reviewers and maintainers by running all tests, create releases for both the community and enterprise editions from the same source2 and analyse certain branches further. One can think of test coverage measured using simplecov but also the performance in terms of runtime and memory usage of all tests. This is useful to decrease the runtime of the pipeline as it currently takes hours to complete without parallelisation. There are also some rules to speed up the pipeline for certain types of contributions3. It is, for example, useless to run the tests when only documentation is updated4.
The continuous integration pipeline consists of a total of eight stages with a total of 200 jobs. Most of these jobs contain spec tests, but there are also jobs which check the coverage, code quality and run static analyses. An example of the current GitLab pipeline is shown in the image below.
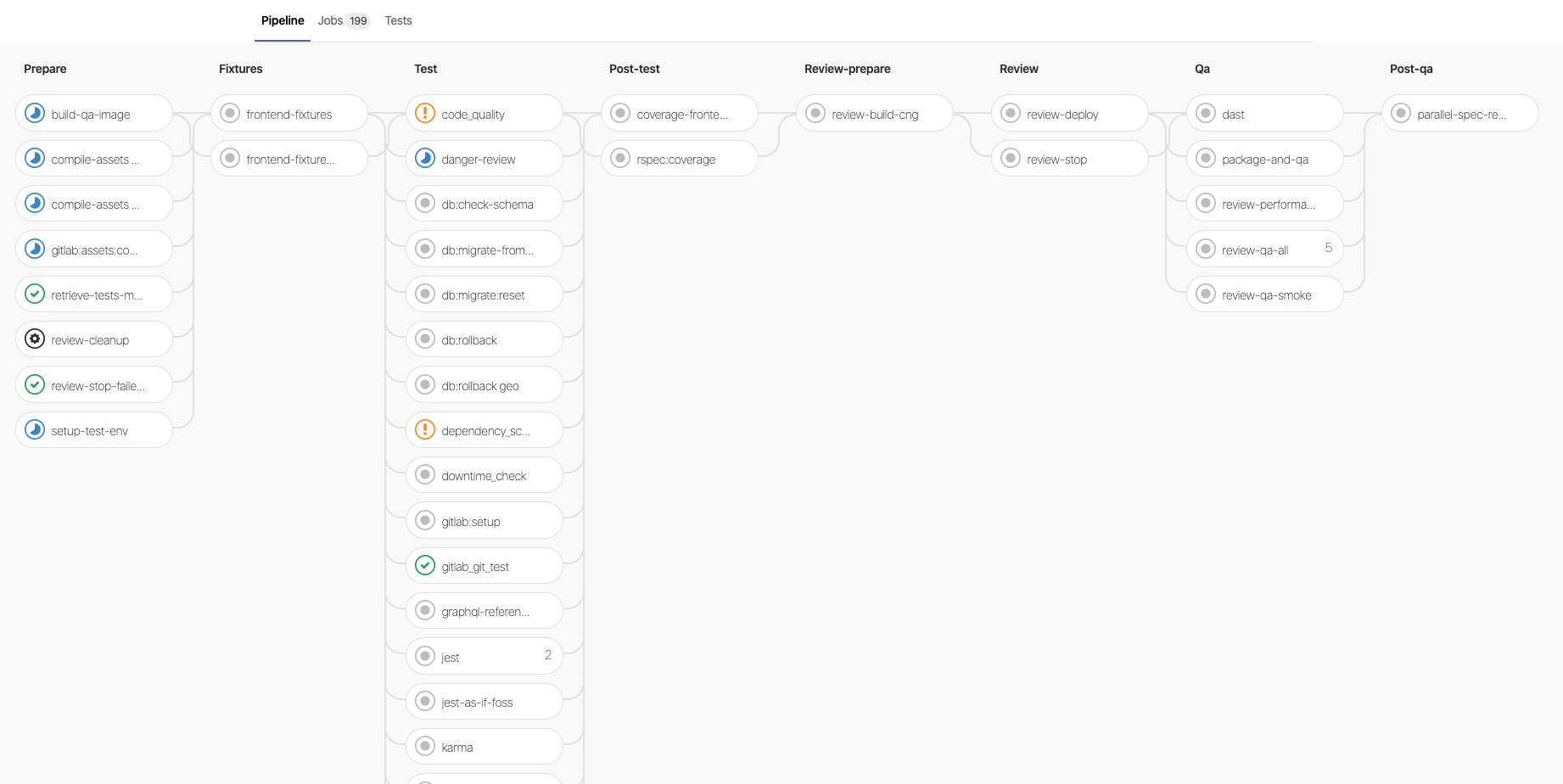 Example of the CI pipeline at GitLab
Example of the CI pipeline at GitLab
Testing
At GitLab, tests are treated as first-class citizens. The extensive testing guidelines describe best practices to which all contributions should adhere. This includes requirements on which level every architectural component must be tested5. It makes a distinction between unit, integration and end-to-end (e2e) tests. The difference between integration and e2e tests is that the former tests the interaction between components but doesn’t require the actual app environment. The latter, however, requires a browser introducing a lot of overhead but ensures proper functionality of the complete application.
The cost and value of a test must be taken into account when deciding which type of test should be created. To summarise Noel Rappin, who clearly describes all sorts of costs and values in his blog post6, costs are related to the time it takes to create, maintain and run the tests while the value comes from the time saved due to early discovery of bugs and running them automatically. Rappin states that “… the goal in keeping your test suite happy over the long-haul is to minimize the costs of tests and maximizing the value”.
The table below shows the relative distribution of tests over the different testing levels. The distribution is not surprising as GitLab used the same line of reasoning as described. Unit tests are short, execute quick and are therefore low cost. However, they also provide little value. It are the end-to-end tests which provide a lot of value but also come with a significant cost due to slow pipelines.
| Test level | Community Edition | Enterprise Edition |
|---|---|---|
| End-to-end | 12.1% | 7.6% |
| Integration | 18.2% | 17.2% |
| Unit | 69.7% | 75.1% |
The relative distribution of tests over the testing levels measured at 2019-05-01.
An example of these trade-offs can be found with a quick look at the public dashboard containing the testing analytics. Mailers are the least tested architectural component with barely 90% line coverage. This can be explained by the fact that mailers should, according to the testing guidelines we mentioned earlier, only be tested with integration tests instead of unit tests.
Value of community in processes
GitLab is made by and for developers, which can be seen in its open-core nature. The Community Edition (CE) of GitLab is open-source, so everyone can contribute.
On March 25th, 2020, we had a video call with Community Manager Ray Paik and Senior Education Program Manager Christina Hupy. In this call, we got to discuss the way non-employees influenced the development of GitLab.
GitLab welcomes all contributions, and these contribtions help GitLab employees see the project from a different view. Ray Paik quoted a coworker on merge requests from an outsider, stating every time he sees a merge request from a non-employee, he gets to experience a new perspective on the project.
Ray Paik stated that over 900 non-employees have had at least 1 merge request (MR) merged, and that last year, around 15% of merged MRs were from outside the company. While most of the development is done by GitLab employees, this is still a significant amount, showing the value of GitLab’s community.
Quality assurance through architectural choices
Now that we have a view of the quality assurance processes in place for the development of GitLab, we will transcend these processes and take a look at the quality of the overall architecture. What measures have been taken to make the architecture future-proof and what plans are in place to keep it that way? We will also assess the technical debt present in the system.
The Rails Doctrine
GitLab relies heavily on Ruby on Rails, a framework which, as the name would suggest, provides a strict format for writing web applications. In the so-called Rails Doctrine, David Heinemeier Hansson states that such a strict framework leaves the programmer with less code to write7. This might improve the quality of the code because there is less room for mistakes but this is only the case if such a framework provides the right tools for the job. In the case of GitLab, this is certainly the case, as it is a very good example of a web application.
Another advantage of using a predefined framework like Ruby on Rails, is the amount of quality assurance tools there are. One of these tools is Rubocop Rails. This is an extension to the popular Rubocop static code analysing tool for Ruby. It provides a way to enforce certain code conventions and best practices, which can then be used as an automatic quality assurance tool within the development process.
The Big Merge
Interestingly, not too long ago GitLab made a major architectural desision to maintain the quality of the code base8. Before 2019, GitLab had two repositories; GitLab Community Edition (CE) and GitLab Enterprise Edition (EE). This made it easy to separate open-source and proprietary code, which has certain benefits such as licensing.
However, as one of the senior engineering managers wrote in a blog post of early 2019, “Feature development is difficult and error prone when making any change at GitLab in two similar yet separate repositories that depend on one another.” Even though they automated most concurrency processes over the years, there were still cases were duplicate work was necessary or other conflicts arose. Resultingly, the two projects were merged into one repository.
Originally, GitLab CE and EE were not ready to be merged. Work had to be done, as was stated in a blog post about the merge: “In total the work involved 55 different engineers submitting more than 600 merge requests, closing just under 400 issues, and changing nearly 1.5 million lines of code”. This clearly was a big investment into the quality of the architecture, but concluded in the post the drawbacks of the seperation began to outweigh the benefits.
What could be improved
Previous sections have analysed various aspects in place to assure the quality of the GitLab project. In this section we will be using the Software Improvement Group (SIG)’s9 analysis to give an assessment on what could be improved.
Software Improvement Group analysis results
At the start of this course, a componentisation of GitLab has been made. Based on this, SIG provided us with an analysis of the system. To see what could be improved, we will look at the refactoring candidates as provided by SIG.
The table below show the SIG score for different system properties.
| System Properties | Score ( _ /5.0) |
|---|---|
| Duplication | 4.3 |
| Unit size | 3.2 |
| Unit complexity | 4.1 |
| Unit interfacing | 4.0 |
| Module coupling | 4.1 |
| Component independence | 2.8 |
| Component entanglement | 1.2 |
We see that the project scores well on Duplication, Unit complexity, Unit interfacing and Module coupling, average on Unit size and Component independence, and poorly on Component entanglement. Let us focus on the worst property.
For Component entanglement, almost all problems are (indirect) cyclic dependencies between components. Over half of all modules are affected, which sounds bad, but is actually the result of the big merge mentioned in the previous section. GitLab’s use of module injection is the cause of this poor score in SIG’s analysis. The drawback of module injection is that components are entangled, but from a maintainability perspective, this drawback is worth it.
Based on the analysis, it would be easy, but wrong, to say that GitLab should focus on detangling their EE and CE components. It’s the result of having two projects in one repository. However, cyclic dependencies also occur between EE modules, and between CE modules. This is not the result of CE and EE sharing a repository, and would benefit from detangling. The biggest refactoring candidate for EE is Cyclic dependency between ee/lib and ee/app with weight 84. For CE, it is Cyclic dependency between lib and qa/qa with weight 75. To put these weights into perspective, the total weight of all candidates is 752.
Personal experiences
While predefined metrics in tools such as the ones SIG use are useful, we would also like to share our experience with the code quality as we experienced by contributing. One of the major challenges we found as new contributors is that since GitLab is such a broad product with many concepts, the cognitive load to grasp what each class and module stands for is quite high. This is also reflected on in a recently opened issue. Their proposed solution is to reduce top-level classes, which also improves maintainability.
To conclude, in this article we have seen various processes in place and choices made to maintain the quality of GitLab. While this only scratches the surface of all the measures GitLab takes, it provides some useful insights in the architectural decisions of a project of this scale.
-
https://docs.gitlab.com/ee/development/code_review.html ↩
-
https://about.gitlab.com/blog/2019/02/21/merging-ce-and-ee-codebases/ ↩
-
https://docs.gitlab.com/ee/development/pipelines.html#workflowrules ↩
-
https://docs.gitlab.com/ee/development/documentation/index.html#branch-naming ↩
-
https://docs.gitlab.com/ee/development/testing_guide/testing_levels.html ↩
-
https://medium.com/table-xi/high-cost-tests-and-high-value-tests-a86e27a54df ↩
-
https://rubyonrails.org/doctrine/#beautiful-code ↩
-
https://about.gitlab.com/blog/2019/08/23/a-single-codebase-for-gitlab-community-and-enterprise-edition/ ↩
-
https://www.softwareimprovementgroup.com/ ↩