Technology should be accessible to everyone - be it an expert in a domain or a novice. Ludwig is such a toolbox that bridges this gap with it’s singular motive to make machine learning as simple and as accessible as possible.
What is Ludwig?
![]()
Ludwig is a machine learning toolbox started by Uber in its endeavour to promote open source development. With its main motive being to make machine learning simpler and easily accessible to everyone, Ludwig attempts to provide you with a toolbox that lets you train your deep learning model without writing code. Furthermore, a suite of visualization tools allows you to analyze models’ training and test performance and to compare them. This aims to help experts from other domains without a lot of deep learning or programming knowledge to build and test their own models with minimal effort (However, programmatic (Python) API are also available to use for those so inclined). It can be used by practitioners to quickly train and test deep learning models as well as by researchers to obtain strong baselines to compare against and have an experimentation setting that ensures comparability by performing standard data preprocessing and visualization.
Ludwig was built with accessibility in mind, meaning that its fundamental values included flexibility, generality, and simplicity of use. Additionally, it was structured so as to be extensible - allowing for easy and methodical addition of support for new data types as well as new model architectures.
End-User Mental Model
Anyone dealing with the application of machine learning need not always be interested to learn about the underlying principles that make the ML algorithm run or implement it from scratch. For instance, for a developer at the very beginning of his/her deep learning career, it may be important for him/her to train, test or visualize ML algorithms without much programming to get a proper understanding. For a researcher, it may be important to obtain accuracy in the results of his/her experiments through the application of sophisticated ML algorithms. Or, for a deep learning practitioner, it may be essential to create fast prototyping and experimentation in order to further develop the model. Ludwig responds to the needs of all these users by implementing the principle of data-abstraction in order to ensure that the user focuses mostly on building his/her model without much coding and debugging. All that the user needs to provide is a model description in a yaml file and a dataset in csv format, in order to obtain a suitably trained model.
Key Features and Capabilities
In order to understand the capabilities of the Ludwig toolbox, an analogy stated by it’s authors is as follows: If deep learning libraries provide the building blocks to make your building, Ludwig provides the buildings to make your city, and you can chose among the available buildings or add your own building to the set of available ones.
With this in mind, some of the major features and capabilities of this toolbox is stated below:
- A new data-type based approach to deep learning model design
- A suite of visualization tools enabling users to analyze thier algorithms
- Fast prototyping and experimentation
- Abstraction of data types leading to a more understandable model
- Flexibility over different deep learning models and training procedures
It is also important to keep in mind the limitations of the scopes provided by this toolbox. They are as follows:
- All those data types that require data-type specific implementations are not allowed
- Tensorflow 2 support is not provided
- It does not allow pre-trained models used in the translation of languages
Stakeholder Analysis
A stakeholder is a person, group, or organization that has rights, shares, claims, or interests concerning the realization of the system or its functions to meet their needs. The following section gives an analysis of the stakeholders of Ludwig. The stakeholders are categorized on the categories defined by Rozanski and Woods1. In addition, we have analyzed the competitors and facilitators of Ludwig to provide a more complete overview of the interest in the system.
| Stakeholder | Description | Definition |
|---|---|---|
| Acquirers | According to 1, acquirers oversee the procurement of the system or product. In our case, this clearly indicates Uber as the sole acquirer as Ludwig was developed in the Uber AI Labs and has been adopted for building a bunch of products at Uber such as COTA, Uber Eats and many more applications that are currently in production. | Oversee the procurement of the system or product |
| Assessors | Uber in addition to being the acquirer, can also be considered as the assessor of the Ludwig project. Specifically, Piero Molino is the main architect and maintainer of the Ludwig project | Oversee the system’s conformance to standards and legal regulation. |
| Communicators | The primary source of documentation of the Ludwig toolbox is the Ludwig website. Additionally, 2 describes the operation and framework of the toolbox. (Contributors Pranav Subramani and Emidio Torre developed the documentation and landing pages of the Ludwig website) | Explain the system to other stakeholders via its documentation and training materials. |
| Developers | Ludwig, being a fairly recent project, has over 60 direct contributors including the Ludwig Core Development team and various members of the github community | Construct and deploy the system from specifications (or lead the teams that do this) |
| Maintainers | Piero Molino, one of the authors of Ludwig is the maintainer for this project. He oversees all modifications to the system via merge requests. | Manage the evolution of the syPost a question on StackOverflow where other users can answeronce it is operational |
| Suppliers | The ludwig toolbox is implemented in Python and runs on top of TensorFlow. The suppliers of the Ludwig toolbox includes the various dependencies (Python modules) that make up the Ludwig system and the platforms on which it runs. The ludwig project uses github for code version control, issue tracking, and releases. | Build and/or supply the hardware, software, or infrastructure on which the system will run |
| Support Staffs | Ludwig does not have staff dedicated to support users with issues. However, they can receive help from the community in the following ways: (i) Post a question on StackOverflow where other users can answer (ii) Consult the extensive Ludwig toolbox documentation (iii) Raise an issue on github where primarily development issues and errors can be raised and answered by the active developer community. | Provide support to users for the product or system when it is running |
| Testers | The ludwig toolbox comes with a set of integration tests (based on pytest module) which ensure end-to-end functionality. All code contributors are expected to perform unit tests on their code before performing a pull request. Therefore, all active contributors to the project can be considered as testers. | Test the system to ensure that it is suitable for use |
| Users | This toolbox can be used by two different categories of people i.e., non-expert machine learning practitioners and experienced deep learning developers and researchers | Define the system’s functionality and ultimately make use of it |
| Additional stakeholders | Description | Definition |
|---|---|---|
| Competitors | Sonnet, Keras, AllenNLP, and other similar libraries are similar to Lud-wig in the sense that these libraries provide a higher levelof abstraction over TensorFlow and PyTorch. And therefore can be considered direct competitiors. | An organization or product engaged in commercial or economic competition with the system. Related works section of paper [2] |
| Facilitators and enthusiasts | There are a number of Ludwig tutorials on various media (YouTube, Medium, Reddit etc.) from facilitators and enthusiasts such as Uber Eng, Gilbert Tanner etc. | A person or a group that is involved in creating content relating to the system for educational or leisure reasons. |
Current and Future Context
In order to provide a clear understanding of the scope and operation of the Ludwig project, we have an illustration that depicts various dependencies, relationships and intersections of Ludwig as a product with various external entities.
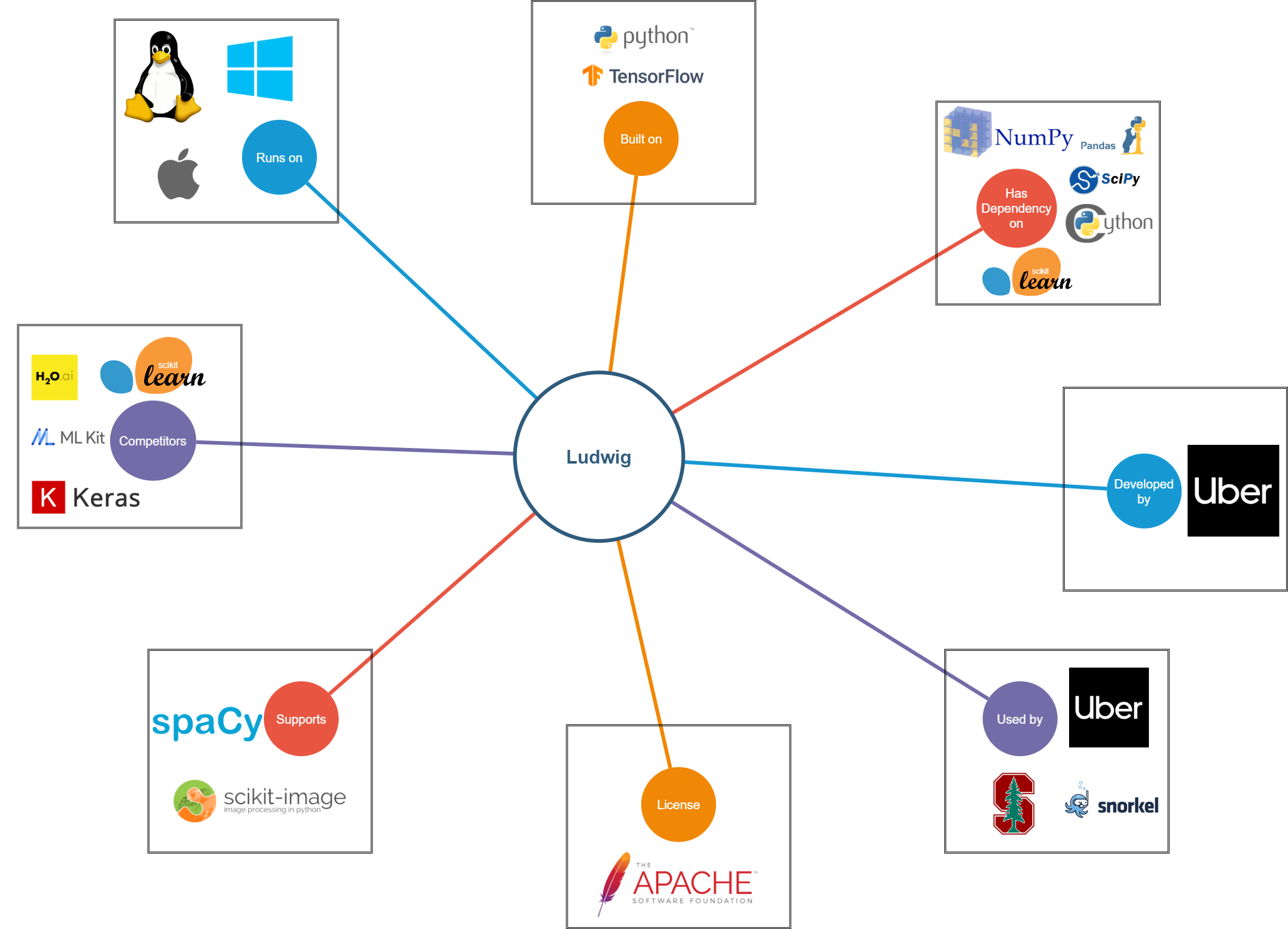
Ludwig is solely written in Python and built on top of TensorFlow. It is actively maintained with an open source Apache License 2.0 on Github where it encourages contributions from the dev-community with an exhaustive list of code conventions and how-tos. It has been used in more than ten projects inside Uber, consisting of text classification, entity recognition, image classification, information extraction, dialogue systems, language generation, timeseries forecasting, and many more 3.
The future plan aims at improving the data preprocessing system existing in Ludwig. Currently, hyperparameter optimization is a functionality which is actively being worked upon in order to include it in the toolbox. Moreover, a team at Uber is also working with Prof. Christopher Re’s Hazyresearch group at Stanford University to integrate Ludwig with Snorkel, their system for programmatically building and managing training datasets to rapidly and flexibly fuel machine learning models 4.
Product Roadmap
Though the Ludwig team has explicitly stated to consider the addition of new features based on the feedbacks of the community, the following list states the features that they are currently planning to include 5:
- New text and sequence encoders
- Image Encoders and image decoding
- time series decoding
- New feature types (point clouds etc.) and pre-processing support for them
In addition to this, the team has also addressed the current limitations of the product. They are stated as follows:
- Ludwig currently does not support dynamic batch reading of data from memory for different datasets except images
- It does not possess a documentation for lower level functions and UI to provide live demo capability
- It needs to optimize the data I/O to TensorFlow
- It intends to increase the number of supported data formats beyond just CSV and integrating with Petastorm
-
Nick Rozanski and Eoin Woods. Software Systems Architecture: Working with Stakeholders using Viewpoints and Perspectives. Addison-Wesley, 2012. ↩ ↩2
-
Molino, Piero & Dudin, Yaroslav & Miryala, Sai. (2019). Ludwig: a type-based declarative deep learning toolbox. ↩
-
Uber Engineering. (2019). Blog post on: Ludwig v0.2 Adds New Features and Other Improvements to its Deep Learning Toolbox ↩