Architecture is a representation of a system that most if not all of the system’s stakeholders can use as a basis for mutual understanding, consensus, and communication. When we talk about the architecture of a software, we refer to a plan that describes aspects of its functionality and the decisions that directly affect these aspects. In this sense, a software’s architecture can be viewed as a set of interconnected business and technical decisions.
So, having looked at Ludwig’s architecture in a high-level system context, we now aim to delve into its technical structure so as to better understand the choices and decisions that have gone into Ludwig’s development.
However, this implies taking into consideration all kinds of requirements: system functionality, system organization, how the system modules interact with each other, whether there are external dependencies, what information needs to be managed or presented or stored, what risks to take into consideration, and much more. To try and answer these questions, we have attempted to split Ludwig’s technical aspects with relation to the various architectural views mentioned in Rozanski and Woods1.
Primary functional elements
The primary functional element - the Ludwig core performs two main functionalities: training models and model based prediction. In addition to this, there exist several visualization and distribution elements. The primary interfaces for Ludwig are the CLI (Command Line Interfaces) entry points that allow users to: train, predict, test/evaluate, visualize and serve.
Information and Data Flow
Ludwig treats user inputs and processed outputs as follows: Ludwig takes user inputs (CSV and model YAML). It then splits and preprocesses the data and builds a model. This is then trained until accuracy stops improving. Finally, Ludwig places the (output) trained model along with its hyperparameters and statistics of the training process in the generated /results directory.
Building Ludwig’s code-base from a Development Viewpoint
In order to understand the the planning and design of the development environment that supports Ludwig’s software development process, let’s dive into Ludwig’s codebase2 and focus on it’s Development Viewpoint.
Module Organization
The figure below illustrates Ludwig’s core and test module organization and their inter-dependencies inspired from Sigrid.
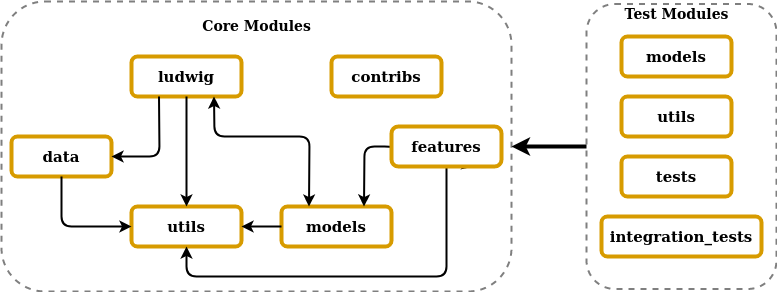
A brief description about each module’s role is:
-
Ludwig: Responsible for integrating and running other modules to perform training, testing, prediction and visualisation for data sets and other configuration parameters.
-
Data: Deals with managing input data for the entire training process beginning from csv file-read to pre-processing and post-processing.
-
Features: Includes feature classes that are responsible for data-type-specific logic implementations required to pre(post)-process specific raw data types.
-
Models: Responsible for combining processing modules such as
encoders,decoders,loss modules,optimization modules, etc., to provide results to the post-processing unit. -
Utils: Includes all minor necessary components and functions that run the system such as
math_utils,print_utils,time_utils, etc. -
Contribs: Includes third-party-system integration files and ensures easy integration of other systems with Ludwig by adding flags to the CLI.
Standardization of design and common processing
Ludwig’s code is structured in a modular, feature-centric way to permit streamlined feature addition involving isolated code changes. In addition to this, the structured nature of the codebase is well documented and guidelines for developers can be found in the documentation.
For example, at a module level, logic pertaining to datatype logic is in the features module under ludwig/features/. Within this module, various feature classes contain pre-processing logic specific to each data type. Each of these classes in turn is required to implement either a build_input or build_output method in addition to their datatype-specific logic used for computation. So, the codebase structure from the code level to module level is consistently (pre)defined and must be adhered to. Additionally, all contributions to Ludwig are expected to meet stylistic guidelines pertaining to the codebase (i.e., code should be concise, readable, PEP8-compliant, and conforming to 80 character line length limit).
Standardization of testing
Ludwig’s test coverage is limited to provided integration tests that ensure full functionality when adding new features. They can be found in the tests/ directory and pytest framework is used to run the test set. To run the entire test set, a user can run python -m pytest from the root directory. Tests can also be run individually if necessary.
The Ludwig team has also expressed plans to expand the test coverage in the future. This way of standardized testing ensures a reliable and objective way to check contributions with minimal effort as all contributors are required to ensure that added features pass the given set of tests.
Codeline Organization
As mentioned previously, Ludwig has a standardized codebase structure to make it easy for developers to locate and modify code. Contributors to the ludwig project are mainly interested in the core ludwig/ and integration tests tests/ directories whose folder structures are as shown below.
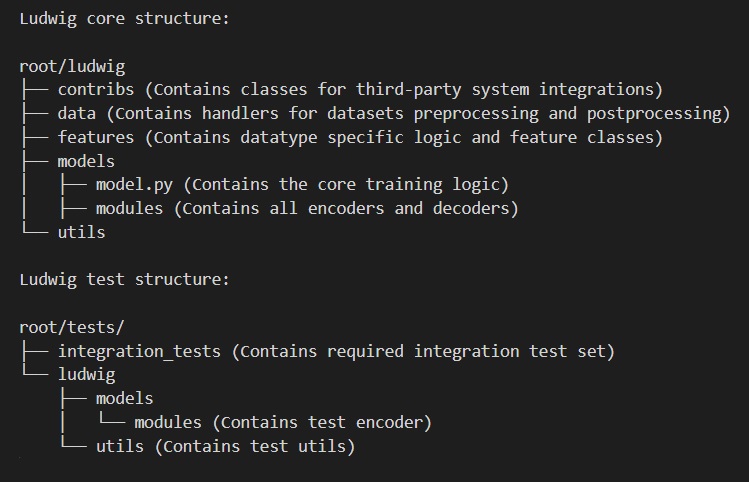
Other Directories
- Additionally, Ludwig’s repository contains directories pertaining to documentation and examples.
- The
docsdirectory contains the official Ludwig documentation. The documentation is built using MkDocs and created using scripts in theMkDocsdirectory. - The
examplesdirectory contains example programs used to demonstrate Ludwig’s API. - Finally, the root directory contains build files (primarily, the python script
setup.pyandDockerfile) and additional required documentation (such asLICENSEandREADME.md).
Distributed execution
The modular nature of Ludwig’s elements allows for implementation of distributed training and prediction by emplying Horovod(another open source software developed by uber). This allows for training and prediction of models to be distributed over multiple machines with multiple GPUs.
Under Ludwig’s Hood
To understand how the system modules interact to make Ludwig functional, we illustrate the run-time view of Ludwig in two simple steps. First, the creation and admission of a declarative model definition and next, the realization of this definition by a training - prediction pipeline.
Declarative Model Definition: This schema allows users to define an instantiation of the ECD architecture (discussed below) to train on their data. This in turn leads to a separation of interests between the end users and the authors implementing these models.
There are 5 types of definition a user can declare namely input features, combiner, output features, pre-processing and training. Depending on these definitions, every component from the pre-processing to model to training loops in the training pipeline are dynamically built. The parameters used for these definitions can be provided by the users concisely (leading to the apllication of defaults) or in a detailed manner (leading to more user control). How we define these paremeters is illustrated in the figure below.

Figure: Selection_069
Training - Prediction Pipeline : After defining the model parameters, a data-processing pipeline is implemented as illustrated below.
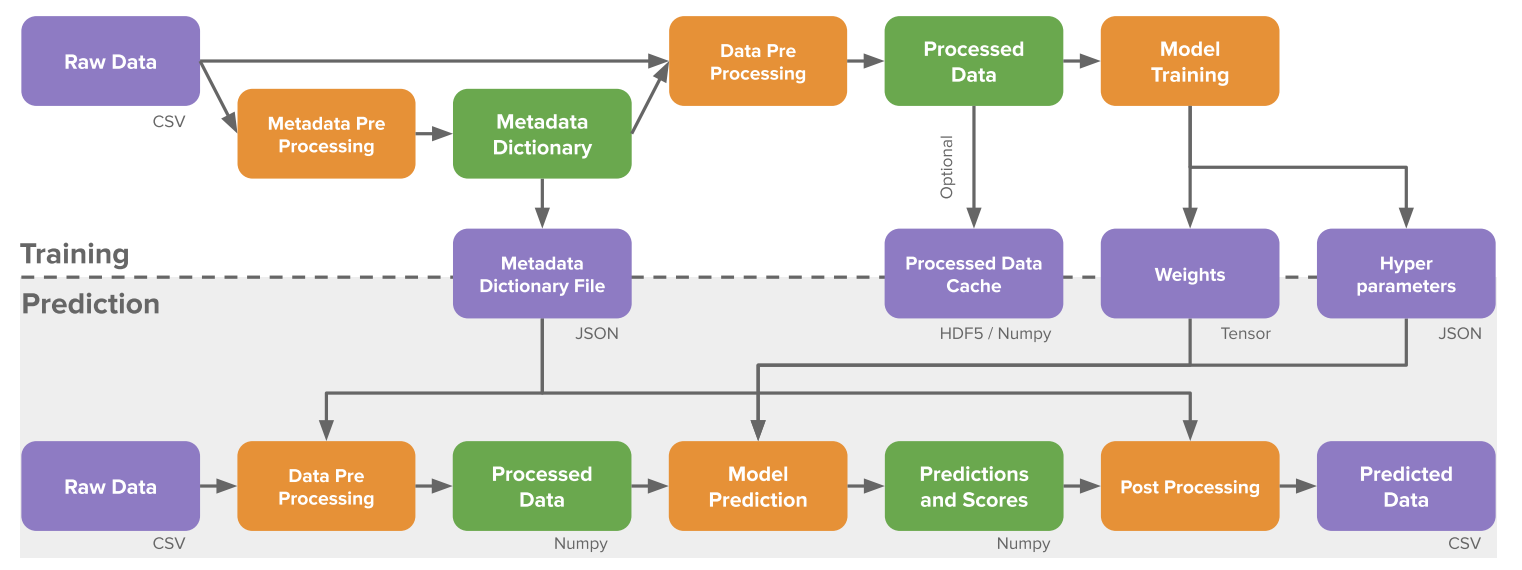
Figure: image-20200318163211997
It is clear from the figure above that the processing pipeline includes: training and prediction. In the training pipeline, during the metadata collection phase, a Metadata dictionary file is used in order to apply the same pre-processing to the inputs during prediction time. A similar reasoning can be provided for storing the model weights and hyperparameters obtained.
In the prediction pipeline, the metadata stored in the dictionary is implemented on new inputs and prediction is performed by defining the model through the trained weights and hyperparameters. These predictions are further post-processed into data-space by employing the same mappings obtained during training.
Implementing a training session
1) Model definitions are provided in yaml format. ludwig/api.py is called to create LudwigModel object.
2) Training data provided in csv format. ludwig/feature component is called and input data is built according to its feature class.
3) ludwig/models component initializes the Tensorflow session and Encoder-Combiner-Decoder architecture.
4) During this session, ludwig/data component is called to create processed data cache.
5) After finalizing the session ludwig/feature component is called in order to build the output.
Deployment and Strategies for Operation
-
Hardware and Infrastructure: Ludwig runs on Tensorflow. Therefore, it is clear that Ludwig extends Tensorflow and uses it as a base infrastructure. Tensorflow is able to run on both CPU and GPU of users device. Consequently, the hardware requirements of Ludwig are also the same. The following Figure illustrates the Ludwig’s requirements.
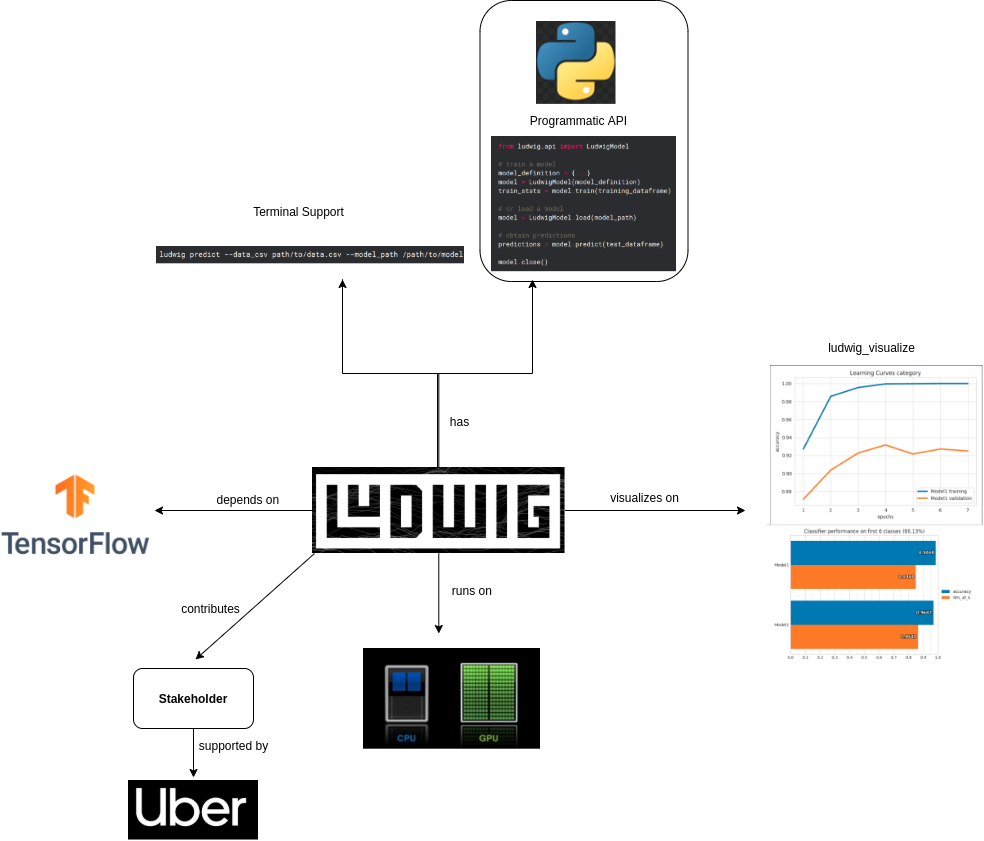
Figure: Ludwig's requirements and infrastructure
-
Installation and upgrade: Ludwig’s basic dependencies are as listed here and Ludwig can be installed via
pipor from the python scriptsetup.py. Additionally, extra features are divided into separate packages (installed using:pip install ludwig[<package>]) with separate dependencies for convenience. -
Data Migration/Reuse: When Ludwig trains a model it creates two files, an HDF5 and a JSON. These are later used for prediction and can also be used for retraining.
-
Operational Monitoring: Ludwig’s CLI supports multiple logging levels (critical, error, warning, info, debug, and notset(default)) to set the amount of logging displayed during training. Additionally, the
--debugflag turns on TensorFlow’stfdbg. -
Configuration Management: Ludwig’s CLI supports a wide range of configuration settings independently for each of its CLI entry points.
Architectural patterns
Ludwig’s architectural style can be viewed from two different contexts3. First, a Type-based Abstraction style which involves modularizing the system components based on the data-types of the input features used. Second, a more generic Encoder-Combiner-Decoder style that maps most of the deep-learning architectures enabling modular composition.
Type-based Abstraction Architecture
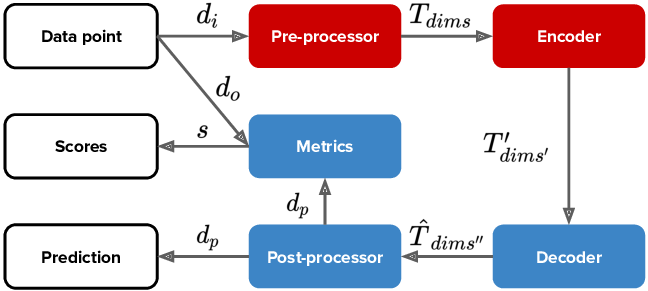
In this architectural style, each data-type is associated with five different function types as depicted in the figure above.
- Pre-processor
- Encoder
- Decoder
- Post-processor
- Metrics
In order to understand this architecture, let’s consider a data point input feature of text data-type. This input is pre-processed by tokenizers either by splitting on space or using byte-pair encoding and mapping tokens to integers and forming a tensor. This tensor is further encoded by certain encoding functions such as CNNs, bidirectional LSTMs or Transformers and the output tensor moves on to the decoder or combiner (to be discussed in the next architectural style). After application of the decoding function, the output tensor is post-processed by either mapping integer predictions into tokens and concatenating on space or using byte-pair concatenation to obtain a single string of text. Finally, a metric function (loss functions) produces a score based on the ground truth and post-processed data.
Encoders-Combiner-Decoders (ECD) Architecture
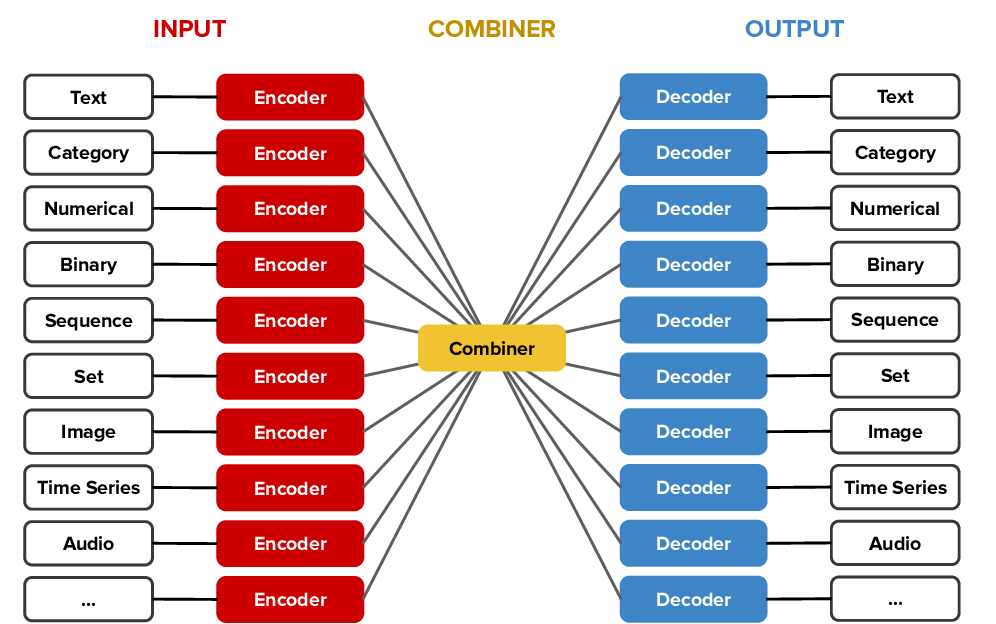
This architectural style in combination with the type-based abstraction is used to define models by just declaring the data types of inputs and output features of a task and assembling suitable standard sub-modules rather than writing the entire model from scratch. Having discussed the functionality of encoders and decoders previously, combiners take up the role as a processing unit (by applying combiner functions) between the two. Combiners such as concat perform the function of flattenning and concatenating input tensors into a stack of fully connected layers.
ECD architecture can take up different instantiations by combining input features of different data types with output features of different data-types. For instance, an ECD with an input image feature and text output feature can be trained to perform image captioning where as an ECD with an input text feature and output categorical feature can be trained to perform text classification or sentiment analysis.
Non-functional Properties
Ludwig’s non-functional properties include:
- Ease of operation - Well written user manuals coupled with support for all major operating systems, ludwig adopts a minimal coding method - making it simple for anyone to work and debug.
- Acceptable inputs and outputs - Ludwig supports most input and output formats (images, text, etc.).
- Encourage contributions - Ludwig has an abundance of community development, though final decisions are resolved by Uber. Since Ludwig is currently under active development, addition of features and debugging existing features are highly encouraged as is evident from the lightning quick responses to queries and pull requests.
- Integration with external software - Code templates and guidelines have been laid out by Uber regarding integration of software with Ludwig.
To wrap up everything, in this essay we looked at the architecture of Ludwig from different perspectives and how it’s various modules are drawn together to make it functional.
-
(Views and Viewpoint) Nick Rozanski and Eoin Woods. Software Systems Architecture: Working with Stakeholders using Viewpoints and Perspectives. Addison-Wesley, 2012. ↩
-
(Development View) Nick Rozanski and Eoin Woods. Software Systems Architecture: Working with Stakeholders using Viewpoints and Perspectives. Addison-Wesley, 2012. ↩
-
(Molino, Piero & Dudin, Yaroslav & Miryala, Sai. (2019). Ludwig: a type-based declarative deep learning toolbox.) ↩