Studying software architecture is a fantastic way to understand the planning behind a system and how it operates. In our previous posts, we illustrated key aspects of Ludwig’s architecture from various perspectives. Now, with this post, we move beyond the building of the system and on to its maintenance and upkeep.
In our analysis of Ludwig’s architecture, we briefly touched upon Ludwig’s handling of issues such as quality control and standardization. Now, we aim to explore the underlying code that forms the system with a focus on the safeguards and guidelines that uphold the quality and integrity of the system.
Quality Guidelines and Feature Integration
With Ludwig being a young, open-source project, the core development team has put considerable thought and effort into streamlining Ludwig’s development process. As a result, Ludwig’s documentation is both methodical and thorough - catering to the open-source developer community, offering detailed information about codebase structure as well as code standards/guidelines for feature implementation. This facilitates contributions while ensuring that any contributions to Ludwig must meet these strict standards.
For example, as documented, Ludwig takes a standardized, feature-centric approach to codebase organization from top to bottom. This means that features and corresponding logic(s) that make up certain features follow a standardized implementation. In short, Ludwig’s guidelines define features and the (minimum required) methods to implement these features. This feature-centric nature promotes uncomplicated addition of features to the system.
Additionally, components of Ludwig’s system ((e.g.) Encoders, Decoders, training logic, etc.) are modularized so that they can be used by multiple features while operating independently. This modular structure also ensures that additions to the codebase only require isolated code changes, thereby insulating the system against failures.
Ludwig’s CI Process
Software testing evaluates a system with the intent to find out if it satisfies a set of specified requirements. This is usually done by (either automated or manually) executing the system under controlled conditions and evaluating the outcome. The most efficient way of early-problem-detection in systems is by verifying code check-ins during the CI (Continuous Integration) stage by automating builds with various tests. In Ludwig, the CI process involves two checks which take up around 10 minutes in total to execute.
DeepSource’s Python Analyzer
The first check that runs in Ludwig’s CI pipeline and is implemented over the entire system. DeepSource is a code analysis tool that helps in managing bugs, syntax, performance, anti-pattern issues, etc. present in code. From our observations of Ludwig’s pull requests, this check generally lasts from 10 seconds to 2 minutes (depending on the number of issues resolved and introduced after a commit) and produces its analysis report which includes detailed insight into:
- Security Issues
- Performance Issues
- Bug Risks
- Coverage Issues
- Anti-Patterns
- Typecheck Issues
Finally, this check is passed only if no blocking issues exist for the commit.
Travis CI Build
This check, hosted by Travis CI, involves building the software and performing a set of developed tests. The check’s parameters (including programming language, version, build and test environments, etc.) are specified in a .travis.yml file in the root directory. Ludwig’s CI performs this test twice i.e., in Travis CI-Pull Request where the tests are performed in automerge state and in continuous-integration/travis-ci/pr where the tests are performed in the current state of the branch that the commits were pushed to.
Provided Test Coverage
Ludwig’s core developers have provided a set of coverage tests for use by contributors. These tests primarily test interactions between Ludwig’s modules to expose possible defects in their interfaces or interactions. For instance, in test_experiment.py, one of the test modules, consider the method test_experiment_seq_seq(csv_filename) (source). This method tests its functionality by running an experiment with cnnrnn/stacked_cnn encoders and tagger decoder defined in its input and output feature respectively. The success of this test would indicate the proper functioning of the encoder and decoder modules as well as their interactions.
Several such integration tests are defined that ensure end-to-end functionality. However, the Ludwig team is planning to incorporate more tests to the test suite in coming releases.
Test Quality Assessment
Ludwig currently only supports a set of integration tests in its test suite. The rationale behind this is that with Ludwig being a relatively young project, its current state/structure is expected to undergo alterations in the coming releases and a more restrictive test suite containing extensive unit tests would only hamper the speed of development of the project1. However, the core development team has expressed an interest2 in gradually expanding the test suite and currently do so regularly by adding integration tests ((e.g.) The latest release v0.2.2 added an integration test for SavedModel).
Code Quality Assessment
A study on “Software Defect Origins and Removal Methods” found that individual programmers are less than 50\% efficient at finding bugs in their own software. And most forms of testing are only 35\% efficient
This illustrates how difficult it is to write and maintain good code simultaneously. Therefore, it is important to take certain key aspects into consideration while measuring code quality as a part of the inspection process. In order to determine the relevancy of these aspects, we ran Ludwig’s code (as of 25th March, 2020) in sonarcloud, a code-analysis tool.
The figure below illustrates the overview of the key aspects obtained from this analysis.
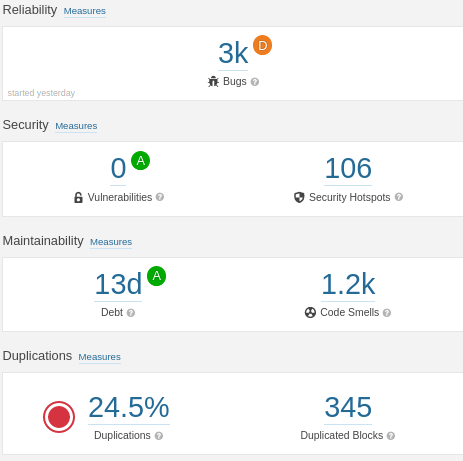
Figure: Overview
Now, let us discuss these aspects and examine the corresponding results of our analysis.
Reliability
This aspect defines how trustworthy a system is. From our analysis, Ludwig scores a “D” in it’s reliability aspect. This is clearly due to its 3003 bugs as denoted in the report. On scrutiny, we found that these bugs are mainly present in documentation modules docs/. and mkdocs/. and are mostly due to styling mis-alignments, duplications, etc. in HTML and CSS files. As critical sections such as (ludwig/.) report fewer bugs, the system can be considered to be more reliabile than the report suggests.
Security
An important aspect that curbs vulnerabilities in a system. Ludwig scores an “A” as it does not have any vulnerabilities. However, the report presents 106 security hotspots, indicating codes in those sections have to be reviewed to ensure proper security before changes to the code make them vulnerable. However, further discussion on this issue is beyond the scope of this essay.
Maintainability
In the event of system failure, the effort that is required in order to restore the system’s functionality is determined by its maintainability. As discussed earlier, Ludwig follows a standardized, feature-centric approach to it’s code-base organization due to which its maintainability becomes systematic and the analysis report with a maitainability score “A” aligns well with this fact. On deeper examination, we see that there is a debt ratio of 0.2\% and an estimated 13 days of technical debt. Further, out of the 1199 code smells, 80\% are present in documentation modules docs/. and mkdocs/. and the remaining in the source and test codes. The figure below illustrates Ludwig’s technical debt.
[Note: Bubble size indicates the volume of code smell. And each bubble represents a separate file]
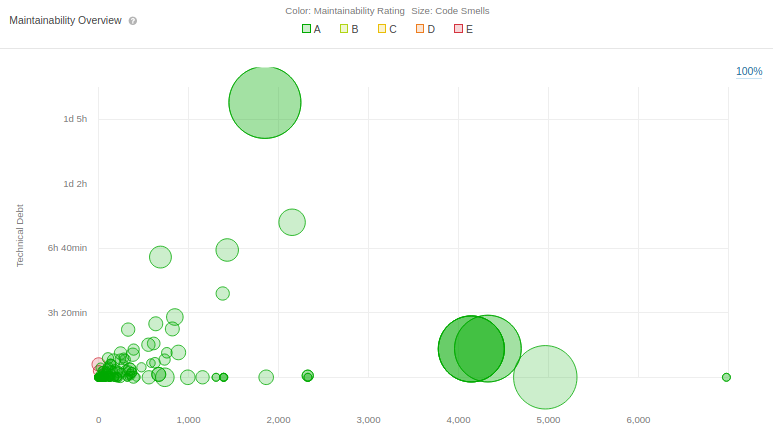
Figure: Tech_Debt
Our analysis of the files containing code smells indicate that most of these code smells are present due to:
- The number of parameters of a function are greater than the 7 authorized by SonarCloud
- Cognitive complexity of a function is higher than the 15 allowed
- Duplicated code
- The presence of unused variables
Duplications
This aspect measures code repetition which is not considered to be beneficial due to its several demerits. Ludwig presents a duplication of 24.5\% out of which 7\% is present in its source code. This is one of the most important aspects that requires code refactorization.
Although, most of the issues discussed in all the four aspects do not impact Ludwig’s functionality, however, they need to be addressed sooner or later in order to avoid any future damage that might arise due to accumulation of these issues.
Now that we have gained some idea about Ludwig’s code quality, let’s take a look at some on-going developments in its code.
Ludwig’s Hotspots
In order to maintain the quality of the overall system code-base, it is essential to assess the quality of those sections of code or modules which are frequently modified, also known as hotspots. These hotspots present the highest risk of breaching at least one of the quality aspects discussed above which would finally add up to technical debt.
To catalog hotspots, we check the latest commits of the coming release. This will give us an overview of code hotspots in terms of lines of code and as a distribution of commits over the components.
To distinguish these hotspots, we put Ludwig’s repo under analysis in CodeScene. The figure below illustrates this. [Note: The most frequently modified files are the most red ones].
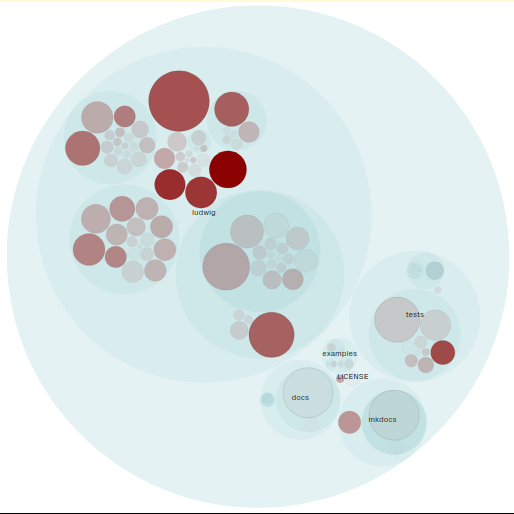
Figure: Hotspots
Now, let us take a look at the quality aspects of some of these hotspots in order of their frequency of modification.
| File Name | LOC | Bugs | Security Hotspots | Code Smells | Duplications |
|---|---|---|---|---|---|
| ludwig/api.py | 636 | 0 | 9 | 2 | 2.4% |
| ludwig/train.py | 554 | 0 | 8 | 3 | 5.3% |
| ludwig/experiment.py | 613 | 0 | 7 | 3 | 22.4% |
| ludwig/visualize.py | 2151 | 0 | 28 | 3 | 4.6% |
| ludwig/data/preprocessing.py | 848 | 0 | 13 | 1 | 0.0% |
| tests/integration_tests/test_experiment.py | 420 | 0 | 0 | 0 | 0.0% |
Though most of these modules have duplications as well as code smells, this amount can be fairly assumed to be on the safe side. The code smells in all these modules can be explained with similar reasonings as provided earlier. However, these issues should be addressed as early as possible before they pile up further adding to technical debt.
We can further investigate commits in the latest release for hotspots in Ludwig.
Inspecting the Latest Commits
Ludwig, being a young platforms, has over a 1000 commits. Studying the distribution of these commits to Ludwig’s modules is done by sorting the commits with respect module name using the following command:
git log --name-only --pretty=format: | sort | uniq -c | sort -nr | grep "name of component" | awk '{ SUM += $1; print $1} END { print SUM }'
The output can be summarized as follows:
| Component Name | Number of Commits |
|---|---|
| ludwig/models | 182 |
| ludwig/features | 246 |
| ludwig/data | 78 |
| ludwig/utils | 205 |
| ludwig/contribs | 23 |
| tests/ | 152 |
As the coming release of Ludwig is under construction for improvements announced in the roadmap, there are numberous commits involving these improvements and bug fixes due to these changes in the code. Additionally, the documentation is also being updated to keep pace with the additions to the system.
Ludwig’s Roadmap
From our analysis above, it is clear that most frequent changes are made to Ludwig’s core module. This supports our expectation as the core module houses Ludwig’s architectural building blocks which are constantly undergoing change. In accordance to the roadmap stated in our first post, the following modifications are in progress:
- Adding new encoders and decoders - New encoders and decoders are added in models directory. #206 #588
- Time series decoding - Should be added in models directory. #244
- Adding new feature types (point clouds etc.) - New feature files are added in features directory. #449
- Pre-processing support #217
Having a look at the merged pull requests on github tells us that some of the planned features like adding audio data type 3, BERT encoder 4 have recently been merged and additional work includes porting to Tf2 5 and improving Horovod 6 (another open source software for serving) integration with Ludwig. On looking at the pull requests, we see that most pull requests include changes in the code to add more featues and the improvements addressed earlier by uber during the previous release of Ludwig. Since ludwig is a relatively new software, as addressed in our previous essay, it still has a lot of limitations and requires additional functionalities. The blogpost release by uber team during every major release contains the possible additions in their future releases.