Software variability is the ability of a software system to be personalized, customized, or configured to suit a user’s needs while still supporting desired properties required for mass production or widespread usage. In the current age of the Internet and Technology, software systems are all-pervasive. Thus, for any software to be effective in today’s market, portability, flexibility, and extensibility are more important than ever before. Therefore, software variability is a crucial aspect of any software system that must be addressed within its structure1.
The idea behind designing for software variability is to put in extra effort during the development stage to provide a base (usually, within the core code) that allows the end-user to generate customizable products with minimal effort. The sources of variability in software are numerous - right from supporting different hardware or software platforms, to functional or even merely executional variability.
To study the variability of a software, we view it as a product line of sorts2. This product line consists of many products formed from a single software system that differ from each other in the features that they implement and the platforms they support (platform and architectural variability). Additionally, certain features in these products may have dependencies or implementations that restrict or necessitate combinations of the features with others (variability in installation). Further, the products may differ in user accessibility (variability in interfaces). Now, we aim to study these sources of variability in Ludwig and their implementations in the repository.
Search for Variability
In Hardware and Platform support
As discussed in our second article, Ludwig runs on top of TensorFlow, using it as base infrastructure. Hence, Ludwig’s system requirements match those of TensorFlow and by extension, its variability in hardware/platform support. Thus, Ludwig supports Ubuntu, MacOS, Windows, and Raspbian platforms and for GPU support, CUDA-enabled cards in Windows and Ubuntu are among its hardware requirements.
In customized installation
In keeping with its themes of flexibility and ease-of-use, Ludwig also offers some degree of variability in installation. The dependencies of Ludwig’s functions are divided into multiple Python packages to afford the end-user freedom to pick and choose packages to cater to their needs. Ludwig consists of a (mandatory) base package and (optional) feature packages.
The base package accounts for dependencies for Ludwig’s basic functions (training models and prediction). Other features such as result visualization, serving on HTTP servers, additional datatype support (such as images, audio, and text), and tests have their dependencies conveniently packaged into individual/separate Python packages.
The following feature-model diagram gives an overview of the installation packages and their customizations available in Ludwig. For simplicity, only 8 dependencies for the Ludwig-base package is illustrated.

Implementation
Taking a look at the SetupTools setup.py script, we see that Ludwig implements this variability by separately parsing each set dependencies while creating the Ludwig Python package. The script lists the base dependencies as mandatory requirements for the Ludwig package while each of the optional package’s dependencies are listed as extra dependencies. So, this allows installation of base Ludwig package using pip install ludwig. Additionally, the optional feature dependencies can be installed using pip either individually, or grouped together or in full (i.e., pip install ludwig[viz] installs the visualization support; pip install ludwig[text,viz] installs both the visualization and the text feature packages; pip install ludwig[full] installs the full set of dependencies).
In the architecture
From our previous article on Ludwig’s Encoder-Combiner-Decoder (ECD) architecture and Input model-definition file functionality, it can be inferred that variability plays an important role in Ludwig’s architecture. A considerable number of feature-types are currently supported in this architecture. Further, each feature-type is presented with one or more encoder(/decoder) types. For instance, Sequence Features can support 8 possible encoder types: Embed, Parallel-CNN, Stacked-CNN, Stacked-Parallel-CNN, RNN, CNN-RNN, BERT and Passthrough Encoders and can be decoded using either Tagger or Generator decoders. However, the choie of encoders afford more variability as most feature-types do not support more than one decoder option. In fact, some feature-types do not support any decoder yet and hence cannot be used as an output feature, for instance, audio-features. In the case of combiners, three different types are currently implemented in Ludwig: Concat, Sequence Concat and Sequence Combiners which are not necessarily feature-type specific.
Adding to the variability within the architectural elements, the model definition YAML file extends it by providing parameters for each of these elements and the training pipeline as listed below:
- Input Features: Eight different parameters, namely: name, type, encoder, cell_type, bidirectional, state_size, num_layers.
- Combiners: Two different parameters, namely: type and layer size of fully connected layers.
- Training: Model hyper-parameter definitions, for example: number of iterations, learning rate, batch size, optimizer and regulators for their model.
- Pre-processing: Feature-specific data pre-processing parameter definitions
- Output Features: Similar structure as Input Features with decoders, loss types, etc.
To clearly understand this variability, let us take a look at the feature-model diagram below. It can be observed that Ludwig basically requires just two input parameters: an input data file to train and a model-definition file to configure the training process. For the sake of simplicity, only 4 feature types per input(output) features are illustrated here. Also only elements of the ECD architecture are expanded further to match the scope of this section.
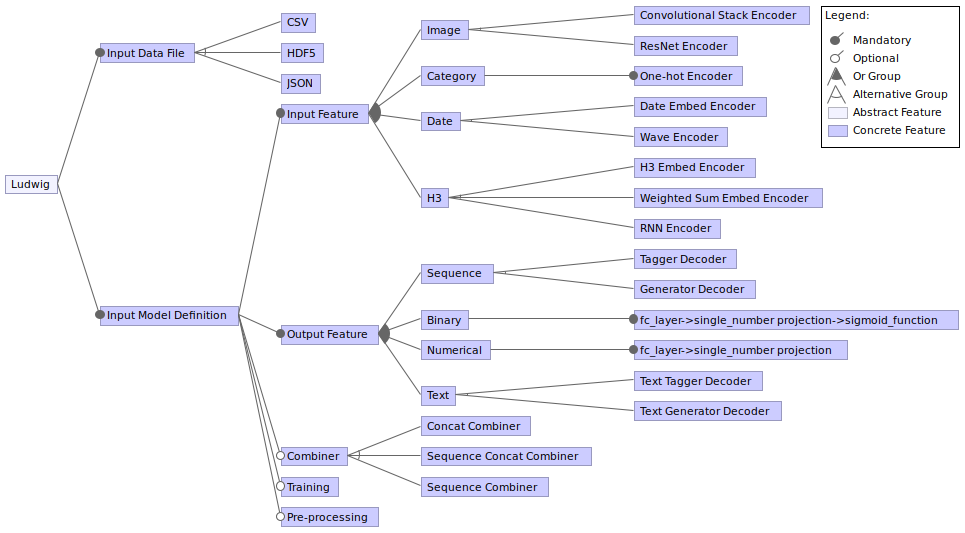
Implementation
Considering the large number of variabilities in the ECD architecture, one can imagine how difficult it can get to structure the entire code-base specific to each feature-type. Moreover, the process of adding new features would also become cumbersome. Hence, to simplify the process, Ludwig uses a template-based design pattern which enables modularity in the code-base design. In this implementation, three different classes: the BaseFeature Class (that deals with the pre-processing of input feature-data), the InputFeature Class (that builds the inputs with corresponding encoders for the model to train) and the OutputFeature Class (that builds the output model with decoders and implements post-processing functionalities) are defined as base classes in base_feature.py file. A parsing and mapping of the respective features from the model-definition file to the specific feature module is done in the feature_registries.py file. Further, each feature module defines sub-classes of the respective base classes overriding the abstract methods with feature specific ones. And, to implement encoder(decoder) types, mapping registries are used which map the types with corresponding encoder(decoder) modules defined in the modules directory.
In the Command Line Interfaces
By this point, it should be clear that Ludwig does not support any Graphical User Interface. Hence, the only method to access Ludwig is through its CLI. To ensure uniformity in access across all operating systems, Ludwig’s CLI consists of six different entry point commands:
- train: To train a model on the input file specified. No variability within this command exists, which in turn avoids any misunderstanding in its usage. However, different flags are provided and can be optionally used according to the users needs (e.g.,
-kffor k-fold cross validation,-uhfor horovod,-gffor gpu usage, etc.) - predict: To predict the results of a previously trained model. Similar to training, multiple flags for prediction are also provided.
- test: To predict on a pre-trained model and analyse the prediction performance with respect to a ground truth.
- experiment: To run a full experiment comprising of training a model and then testing it.
- visualize: To analyse the results for the model on the data-set and to present a variety of plots to understand and evaluate the results. These plots can range from simple learning curves to confusion matrix plots.
- collect_weights: To collect the weights for a pre-trained model as a tensor representation.
- collect_activations: To collect tensor representations corresponding to each data-point.
- serve: To load a pre-trained model and serve it on an http server.
The detailed explanation with parameters and usage guidelines of the CLI can be found in its documentation. For all of these commands, variability is presented through the use of different flags. Hence, by shifting the majority of the variability to the underlying architectural domain and maintaining a simple user entry point, Ludwig aims to broaden its consumer base by catering to a wider range of end-users.
Implementation
Taking a look at the code-base implementing the CLI optionalities in cli.py file, we found out that the code flow was pretty straight-forward. In this implementation, a CLI class defines all the entry points as methods. A dispatcher design pattern is used to invoke a method if the input command matches the corresponding method name. Further, each method on getting invoked, creates the corresponding command object and uses the “cli” method to access its functionality along with the input flags. The variability of these input flags are implemented in the target files for each command. For instance, on running the training command, ludwig checks all the flags and runs the pre-processing modules (with necessary flag parameters) followed by the training modules. Further, to add a new flag, one can simply add a system argument and modify the module in which the flag would be used. Ludwig also provides an open-ended method through which one can create their own module and add a flag in the cli.py file to run the module.
Managing Variability in Relation to Stakeholders
So now that we have explored the many facets of variability in Ludwig, we conclude by attempting to discuss the impact of variability on its stakeholders (primarily the end users and developers) and glance at how Ludwig tries to manage this impact using documentation and information sources.
It is important to keep in mind that Ludwig’s end users can range from a novice to an experienced Deep Learning enthusiast. Hence, Ludwig provides different levels of variability depending on the level of expertise of the end-user. For instance, to a novice end-user, Ludwig does not really offer much variability. The user only needs to provide a CSV input file and define suitable input and output feature-types in the model-definition file. All the other parameters use their default values/types to train the model. On the other-hand, an experienced user has the opportunity to explore a much wider variety of options available at an architectural as well as processing-level in Ludwig. This includes encoder(/decoder)-types, hyper-parameters, loss types, etc. To provide the user with a better understanding of these variations, a well-documented user guide is maintained by Ludwig’s core development team. Moreover, considering the variations in the installation packages, a well-documented installation-guide is also provided that lists all the necessary dependencies and extra packages required to train specific feature types.
Developers can be considered as those experienced deep-learning enthusiasts who play a role in Ludwig’s design/development process in addition to their role as end-users. To manage Ludwig’s growing open-source developer community, there are uniform guidelines to be followed to contribute to its development via Github. These guidelines ensure that feature additions or implementations follow a specific standard (refering to how they are called or the way their parameters are defined in the created feature class). This results in an improved cognitive complexity analysed in our previous post.
So, this study of variability in Ludwig lends credence to our previous assesments of Ludwig and show that Ludwig has been designed with extensive variability in mind, both in terms of architecture/implementation as well as in accessibility.
-
Mastering Software Variability with Feature IDE, Authors: Meinicke, J., Thüm, Th., Schröter, R., Benduhn, F., Leich, Th., Saake, G. ↩