We’re back one extra and final time to explain our experience on working with mypy as an open-source project in hind-sight. Lucky you!
Something really interesting happened, while we contributed some functional and documentation-related features to this python typechecking library. We’ve setup our own workflow, we went through the process of understanding not only the library, but also it’s environment and testing system (CI), and now we’ve got something quite interesting to tell you about what we think mypy can improve on!
Workflow: contributing as newcomer
When a developer decides to invest time into an open source project in the form of contributions, there is an incentive to this action. The attention the developer diverts from his/her normal project clearly is halted by some reason. We’ve found the following reasons to be valid during our past experience on mypy and other software projects:
1) Some feature(s) are missing in the library of choice, making the usage less pleasing. 2) Some bug is holding back the usage, a peer dependency upgrade, or something in the involvement of the library in the original project. 3) Sudden interest is found in the library by an external factor, or a possibility of a great learning experience is met. 4) The library is backed by a company, organisation or group. And a new developer is assigned to the repository’s project.
We’ve found option 1, 2 and 3 to be the most applicable to most of our open-source contributions or usage of libraries. Assuming scenario’s 1-3 to actually be the most occurring, it seems of great importance the the open-source project to guide the developer as much as possible. Only proper guidance through documentation can result in a compact and effective workflow for contributing changes. We’ve noticed that mypy tackles this as follows:
- Assume that a developer finds an issue (possibly low-hanging fruit with
good-first-issuetag.) - Developer inquires about issue, possibly with or without response.
- Contributions are made through a fork of the repo and a PR.
- (Optionally) tests are added.
- The PR might be: ignored, abandoned or completed.
However, the listing above is too simplistic in some ways. When software contribution is done, the developer might spend more time waiting on feedback and information than actually on programming. The following figure shows how the critical and worst-case path in the contribution cycle for a new-comer might be:
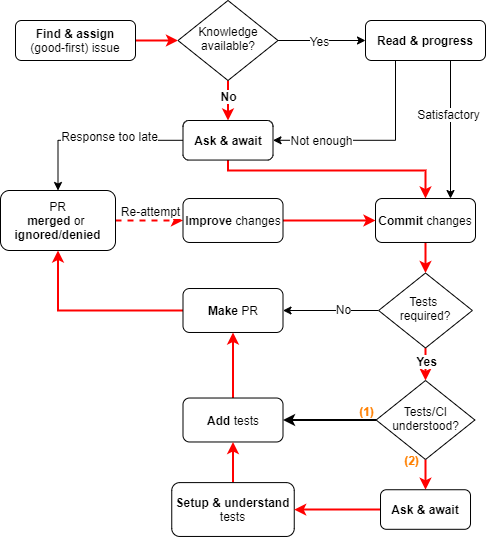
Figure: Deveveloper Flowchart
Critical path of development, with (1) and (2) being critical choices.
The first challenge arises at the Knowledge available? question. Since mypy has a lot of documentation, the developer at hand might be able to get further. A big portion of the crowd however, lost their attention at this point. After the a contribution is made, we arrive at the Tests/CI understood? challenge. This process is standardized partially for mypy, its built up in quite a complex manner, but also poorly documented by multiple documents placed in a unfortunate place. We believe that mypy can easily improve its developer documentation to reach path (1) instead of path (2).
Testing: understanding pytest
As we’ve discussed in a previous blog, in order to contribute to mypy one has to understand how it uses pytest. This library is quite common in the realm of python as a go-to test library. We covered how pytest is extensively used for regression testing of which unit tests and integration tests form the basis. However, we did not cover how mypy runs both python-based TestCase instances as well as DataSuite instances. The latter suite specifies test-data files to run, which provide variability coverage as well as compactness.
We will first explain how the tests are discovered, and then come back to these test suites.
Autodiscovery of test
As we’ve covered, pytest runs the test by scanning the subfolders for any files with the ‘test’ prefix or postfix in their name. Secondly, test-prefixed functions or methods (as well as Test-prefixed classes) are added as testing instances. The pytest runner for mypy starts running multiple workers in parallel to execute the tests.
Now, simply running pytest in the folder will take a long time due to a lot of discovered tests, so the developer will have to look up how to filter on their specific tests. This can become quite a complex call, but it is worth the speed:
python -m pytest .\mypy\test\testpep561.py::PEP561Suite
We are calling the python file testpep561.py and containing the test-suite PEP561Suite. This DataSuite-extending class specifies a files list which refer to one or more *.test files. Those test files have a special syntax, which needs to be parsed, validated and understood by a test-class like PEP561Suite.
Now, you might wonder, why are we going into so much detail about this DataSuite? The reason is: we are trying to show the many steps a developer needs to discover in order to finally be able to know where to look. Only then can they start learning about the syntax of these compact test files, which is not for the feint of heart. We’ll give the simplest example to be found:
[case testFunction]
import typing
def f(x: 'A') -> None: pass
f(A())
f(B()) # Fail
class A: pass
class B: pass
[out]
main:4: error: Argument 1 to "f" has incompatible type "B"; expected "A"
This file is used as input for one of the many test*.py files. It is up to the developer to find which one and based on what criteria (validations)!
Testing, a design debt analysis
The library mypy is becoming quite complex by the day on a functional level, but the testing process could and should be simplified more. We’ve shown that the contribution workflow for a newcomer is possibly obstructed by lack of knowledge. Secondly, we’ve hinted at the complexity of the data-driven tests, which is a big portion of the tests run for mypy.
The data-driven tests are definitely the most compact and readable way to understand the mypy tests run. The challenges however are four-fold:
- The developer needs to know which python test-file he should adjust/add.
- The developer needs to know how mypy runs pytest TestCase instances, let alone tests-suites like DataSuite.
- The developer needs to understand how to find the data file(s) for the Data-driven test.
- The developer needs to know how to add tests (syntax) as well as how to expand the validation/pre-conditions (in the python DataSuite).
As might be clear, this is a lot to learn before actually being able to contribute!
Advice on more test-driven design
We don’t think that mypy is moving in the wrong way by choosing data-driven tests, but we see one primary problem: tests should be as simple as possible and their information should be as contained as possible.
Our advice for mypy is to:
1) Place the data files closer to the data-driven tests near the tested files. 2) Add a very up-front testing documentation (link to github PR) for data-driven tests. 3) Auto-discover test data files like this issue and automatically couple the files to python test-cases.
These options can massively improve the critical path shown in the workflow image presented above. With these tips, we hope you enjoyed this final blog from our side and hope you have become enthousiastic about open-source software, or even about using mypy!