Addressing quality from a software point of view deserves some caution in openpilot’s case. Image yourself as an openpilot software engineer and picture a variety of cars driving around seamlessly and without active human efforts because the code you wrote is good. It sure is an awesome feeling. Now imagine a less cheerfull scene with a car collision, beware that this is not your average lightweight javascript view library, peoples lives depend on it. As the company rightly pointed out, quality is represented by the stability of the cars that are driven by their software (and partially hardware). Therefore assessing quality deserves an unusual integral approach in this non-deterministic context that the code runs in. Think about all the slightly different traffic lights at every corner of the street, think about quaint driving lanes with potholes, think about ludacris other drivers, no situation is the same. An autonomous car is not an ordinary car and a comma two is not an oridnary android device.
The quality mark of openpilot’s parts
Considering guidelines of maintaiable, future proof code in software engineering, openpilot passes the first inspection. As was highlighted in our previous post, concerns are separated in modules that are loosely coupled through the use of the publish and subscribe pattern. Additionally, it seems like the company is taking small codebases to the next level by advocating externalization. Together with the automated tests (see below) this demonstrates great awareness of building maintainable software. For the remainder of this post, we will look at how these abstract principles are made concrete by comma.ai.
openpilot’s CI process
Perhaps the most efficient way to get programmers to write working code is to enforce them in the CI (Continuous Integration) stage, by rejecting any commits that sport the dreaded “Build Failed”. openpilot is no different. A variety of unit and integration tests are run against every single commit to ensure no regressions slip through the cracks. The whole test suite takes about 30 minutes to run.
Unit Tests
As we learned in our previous post, openpilot is not a monolithic application, but instead consists of many cooperating processes that communicate using a message queue. It seems only logical that the unit tests follow the same pattern. Out of the 20-something total processes that run within openpilot, only a couple have unit tests. Upon investigating specific unit tests, it seems that some tests require a deep understanding of autonomous driving and the mathematics behind it. Many tests contain variable names that are abbreviations of domain-specific jargon.
In the agile world, unit tests are part of the documentation. However, the scarcity of unit tests, cryptic function or variable names, and their complexity makes them impossible to use as documentation.
Most of you will be familiar with the AAA pattern when writing unit tests: Arrange, Act, Assert (although sometimes Given, When, Then is used). Consistently applying this pattern will go a long way in making unit tests small, comprehensible and fast. In openpilot, however, assertions are often mixed with actions. This makes it especially hard to see what is actually being tested.
We would even argue that most “unit tests” in openpilot are not actually unit tests, and that they are instead much closer to functional tests. They take a long time to run (unit tests should be fast), they make many different assertions in one test (assertions and actions should not be intertwined), but above all there should be more unit tests.
Maneuver Tests? (Functional Tests)
Openpilot, being a autonomous driving system, obviously needs robust functional testing to ensure all of its components work together to create the desired output.
Another step in openpilot’s CI pipeline is executing maneuver tests. That is, certain pre-determined maneuvers (scenarios) are presented to openpilot, which are then acted upon by the system. Pass or fail is determined by running a list of checks for each maneuver.
This sounds complex, so let’s add an example.
“fcw: traveling at 20 m/s following a lead that decels from 20m/s to 0 at 5m/s2”
(source)
Translation: check that openpilot gives a Forward Collision Warning when following a lead car that decelerates from 20 m/s to 0 m/s at 5 m/s².
openpilot runs ~25 of these maneuvers. Each takes about 10 seconds to simulate, so that adds up to around 4-5 minutes.
Regression Tests (Replays)
Next up in openpilot’s CI pipeline: preventing accidental changes in process output. By comparing the output of processes against the output of a reference commit, unintended changes to the output of openpilot can be noticed and mitigated. These tests live in selfdrive/test/process_replay/, along with the reference output. Whenever this test fails, the author can inspect the output and update the reference output if deemed correct.
Coverage
There is just one piece missing in the CI pipeline: coverage. Test coverage is definitely a very important tool to find untested parts of your codebase (do, however, keep in mind that test coverage says absolutely nothing about the quality of tests). Currently, coverage is not part of openpilot’s CI process. It seems that, since openpilot relies mainly on functional tests, the developers deemed it unnecessary to add as part of the development life cycle.
Openpilot’s Garage
Now that the context an conditions are clear, it is time to shed some light on the way openpilot is maintained. As mentioned in previous posts, it is maintained by professionals but the decentralized nature allows for aspiring mechanics to gain experience through open-source contributions, For the occasion of writing this essay, we put ourselves in the shoes of an independent mechanic and ran code analysis tools on openpilot’s code.
SonarQube Analysis
We ran SonarQube on commit f21d0f3 and investigated its assessments based on the static code analysis:
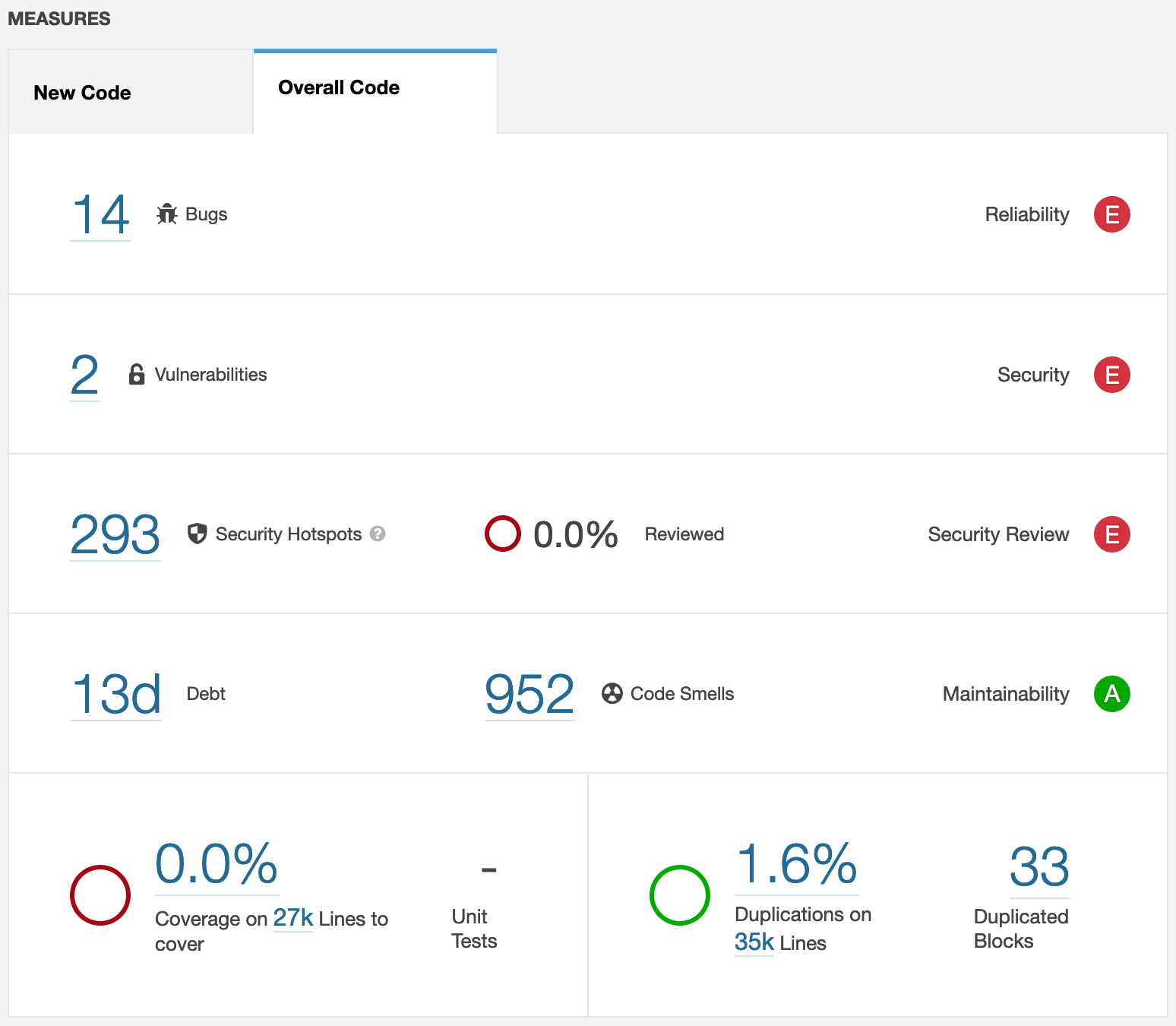
Each metric and it’s evaluation will be discussed next.
Reliability
Because of 14 bugs, openpilot scores an E. The majority of these bugs live in non-critical parts of the codebase like tests and debugging tools. Most bugs relate to an incorrect amount of parameters provided in a function call and useless self-assignments. While these issues should be fixed, we are happy to see that none of them resides in critical core functionality.
Security
Because of 2 vulnerabilities openpilot scores an E, one is discussed.
Weak SSL/TLS protocols should not be used
What we see here is a connection with the online logger service, using an insecure TLS protocol version. Exploiting this could possibly expose privacy-sensitive car data.
def open_connection(self):
...
ssl_version=getattr(
ssl,
'PROTOCOL_TLSv1_2',
ssl.PROTOCOL_TLSv1
),
...
This should be fixed by upgrading both server and client to the latest TLS (1.3) version.
Maintainability
Interestingly, the codebase scores an A on maintainability. We are actually surprised by this result, since we expected it to be a bit lower because of our findings regarding lengthy files and missing comments. Looking further, we see an estimated debt ratio of 0.6% and 13 days of technical debt. While there are 952 code smells in total, they seem very distributed over the 395 analysed files. SonarQube visualizes this in the Maintainability Overview, note that each bubble represents a file.
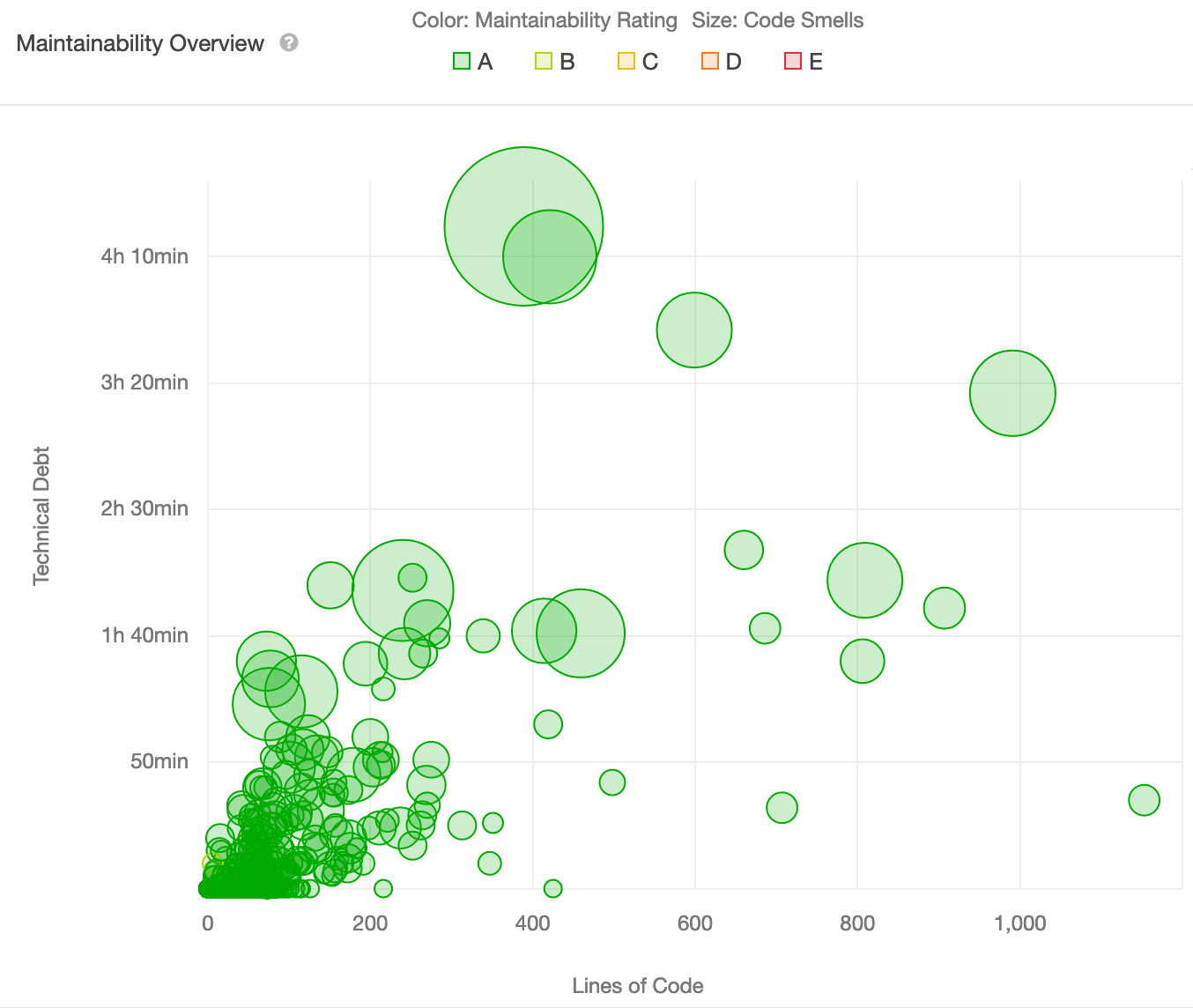
This highlights refactoring candidates because of their lines of code.
When investigating the code smells, often recurring ones are:
- Snake case function and variable naming instead of camel case (the vast majority of all 492 minor issues);
- Cyclomatic complexity being (way) higher than the allowed 15;
- Duplicated code;
- More function parameters than the allowed 7.
These issues can and should be fixed to preserve long-term maintainability. Inconsistencies resulting from missing standards could lead to different coding styles. This makes it hard for new contributors to understand the codebase and decide on which style/standards to adapt.
Other Technical Debt
Most technical debt is very hard to discover or quantify with static analysis tools. This stems from the fact that technical debt most of the time is a feeling that a developer has about a codebase, which is quite clearly not objectively quantifiable. Ask a developer to implement a new feature, and he/she will use that feeling to provide a time estimate.
So what do openpilot developers consider technical debt? A look at the current issues page reveals that project lead George Hotz has identified a number of improvements to be made for openpilot’s next release. Some noteworthy issues:
- [issue] Custom VisionIPC should be replaced with the more stable but functionally equivalent msgq. This is an example of technical debt that simplifies a project, and therefore simplifies future contributions.
- [issue] Fingerprinting code needs to be refactored to use a new API. Uniform code is more easily digestible for new and existing contributors.
- [issue] Elimination of code duplication. Less code duplication leads to readable code, which leads to less cognitive overhead, which leads to happy developers.
The Road Ahead
In the first blogpost the roadmap of the system contains two important elements, creating ground-breaking technology by learning from drivers and ensuring that the MTBF of autonomous driving outperforms that of human driving. We will now look at which components of the architecture, described in the second blogpost, will be affected by the roadmap.
Learning From Drivers
As mentioned, the goal of the system is to learn everything from drivers. So far the system is already well underway with accomplishing this, but it should eventually become capable of simultaneously performing steering, gas and brake end to end.
If we look at the architecture diagram, displayed in the second blogpost, the components that will be affected by the future changes, are the components within the Self-drive Core part of the architecture. This part of the architecture will be affected as this section receives the driving data in order to return an action. The two most important components to highlight from this section are modeld, it applies the machine learning model on incoming data, and plannerd, it creates a task for the car.
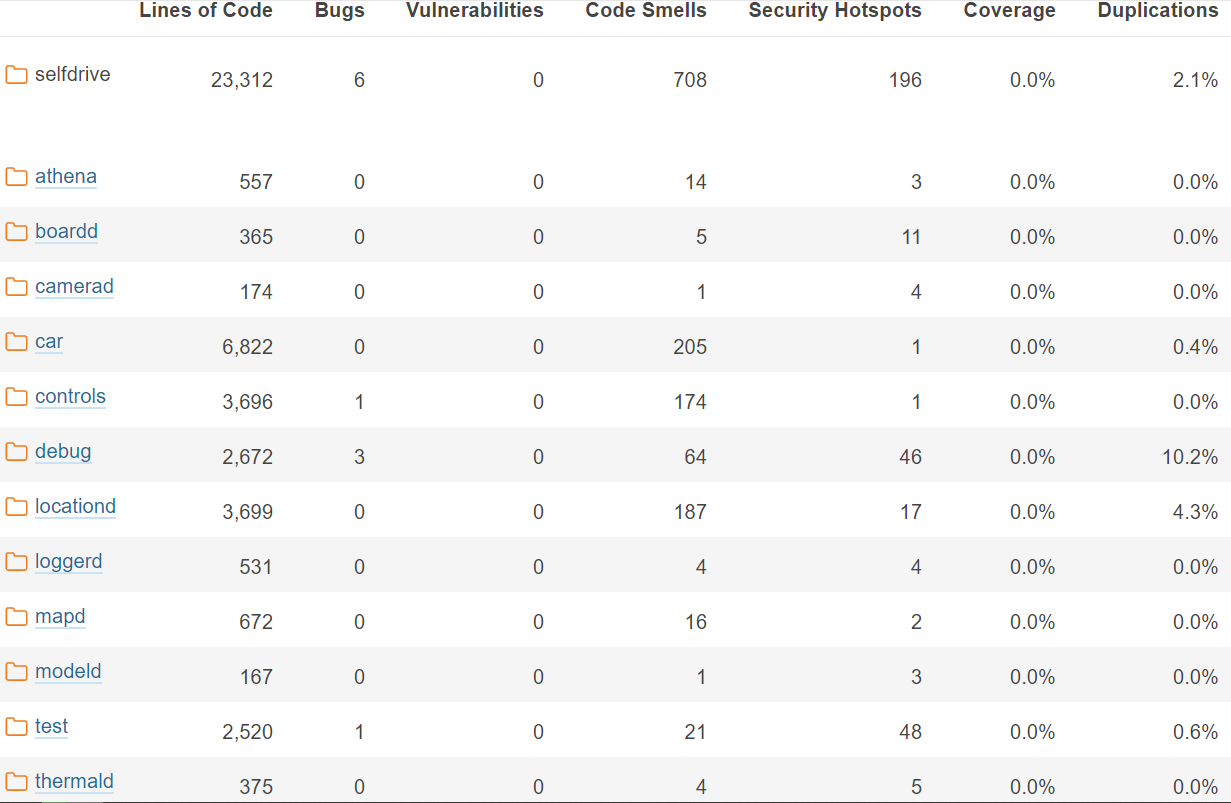
Taking a look at the self-drive core components in the image above, where plannerd, radard and controlsd are located in the controls folder, we see in these sections that there is just one bug, which is within a test in the controls folder, almost no security vulnerabilities, and a couple of code smells, except for the car folder. If we just look at the modeld and plannerd part of the code, we even see that there is just one code smell and three security vulnerabilities. This shows that the overall quality of the self-drive core components is decent, the quality of modeld and plannerd is great, and the maintainability overall is outstanding, as previously seen.
Autonomous Over Human Driving
Two important factors to improve the MTBF of the system are having maintainable code and fully understanding bugs/system failures. As the MTBF is related to the whole system, all the components, displayed in the architecture diagram, will be affected. It basically comes down to the reliability and maintainability of the system, of which we have previously seen an overview. There we saw that the reliability of the system got the grade E and for the maintainability of the system, the score was an A. While the bugs found by SonarQube reside in non-critical parts, and the maintainability is great, these bugs and the code smells found by SonarQube should be fixed in order to achieve longterm reliability and maintainability.
We hope we gave you some insights in the perception of quality that openpilot has. In conclusion, we can say that openpilot is a prime example of how much of an interdisciplinary field software architecture is. With dependencies on things like the culture and business, every architectural decision eventually matters. The future is bright for comma.ai and openpilot. Not only is the quality of their software and hence their entire system a key driving factor, more and more people want to enjoy this quality. With the first user willing to monetarily incentivize someone who can help drive his car better in February 2020 and an official bounty backlog, the urge and urgency for quality is high. Quality that is achieved by writing maintainable code.