In previous posts, we focused on the business, technical and quality side of openpilot. Today it’s time to zoom in on some different aspect that might not be the first thing that pops into your mind when thinking about the architecture of a software product: Variability! Now you might think, variability is everywhere or variability is unavoidable. In the world of software, both are true! This post will be dedicated to defining, identifying and coping with variability from an architectural point of view. We will do this by identifying the aspects of the software that are susceptible for variability and how individual components relate to each other. Subsequently we will look at the meta-side of variability and which effects it has on those concerned. Finally, we will have a look at openpilot’s strategy for managing variability.
Good is variable, variable is good
Let us first narrow down our scope and identify three areas that are the potential host of variability and go over the applicability in this context. We can have variability in:
-
Hardware: In this context, the hardware is the comma two. Since this is an Android device, comma.ai controls and always has controlled the distribution, no variability can be found here that is worth mentioning.
-
Software: openpilot is a product that in continuous development. As a result, sometimes paradigms shift like when the business advocated externalization. Additionally, in a previous post about the architecture, the modularity of this product was highlighted. Is the architecture well-suited for this kind of variability? Also the fact that openpilot is implemented in both Python and C++ makes it prone for disturbance. Considering the numerous amount of people that contribute to this project, how would you deal with different coding standards, variable naming conventions and formatting settings for linters?
-
Platform: Although different than our common definition of platform, we will treat the car as the platform for this blog. It goes without saying that the root of a lot of variability in openpilot is due to the large number of cars it supports. As you probably will understand by now, we can not simply ssh into a car to open up a UNIX shell and issue some commands that makes it steer to the right. Each (brand that makes a) car is unique in its own way. Despite the fact that there is some uniformity, there are still fundamental differences.
Should we eliminate it all then?
Important to note here is that in an ideal case, we want have as little variability as possible in either of the domains (software, platform) without limiting functionality. Before addressing how openpilot deals with such a quandary, the picture below depicts a feature diagram. This diagram was made with FeatureIDE and provides a coarse overview of the concrete features and possibilities that openpilot has to offer to it’s end-user.
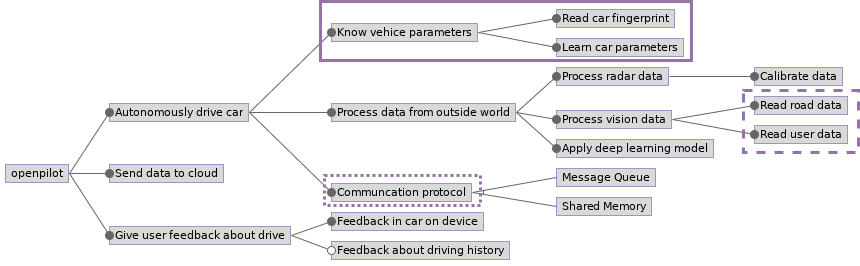
Figure: Feature diagram, boxes indicate variability
At first sight, this looks quite static since the only (mutual exclusive) choice that developers (product owners in this case) have, concerns the messaging protocol (indicated by the dotted line in the figure). This however is a software variability that is encountered during design time, this can and will be managed by making one default for the future. As mentioned, the platform variability (having to support a variety of cars) is indicated in the figure with the solid line. This variability occurs at load time and you would assume that this can be tested, right? We will address that in further sections. The last box with the dashed border is software variability that occurs during run time. Suppose you place a camera in your car (or another preferred transportation vehicle) and look at the footage you recorded after one day, how many frames are exactly similar? Well, indeed, a fundamental source of variability is the input data of your software. Combine this with the different cars, cloud connection, modular code bases and a messaging protocol and you will end up with an equation that has a lot of parameters. We will discuss how openpilot manages all these parameters in the following sections.
Variability Management
Now that we have seen an overview of the variability within the system, we will take a look at how this variability is managed for different stakeholders and which mechanisms are put in place to help ease this management.
Stakeholders
The stakeholders that we will take a look at are the ones that have to do with the product, comma two, namely the end users, open-source developers and comma.ai.
First of all, let’s take a look at the end users. The variability that the end users will encounter will be the different car brands and models they use, or the fact that the user switches cars and now wants to use the product in the new car. As long as the car the end user wants to use the product in is supported by openpilot, this variability will all be managed by the product with the use of fingerprinting, which will be explained later on, so even switching cars is no problem. This means that the user just needs to install the comma two in their car, which can be done by following the installation guide on the Comma.ai website, and the product will manage the rest. In terms of variability, the end users are directly linked with the variability in the software that occurs during run (driving) and load (installation) time. This is managed by testing and feeding the data to the neural network to let the model deal with with it.
Secondly, we have the open-source developers, of which most (if not all) are also a part of the end users. As they are primarily concerned with the varibility in the software that occurs at run time and design time, it is key to establish uniform guidelines. The first stop for open-source developers is the GitHub of openpilot. This GitHub, as well as those of the used submodules, contains multiple useful markdown files to read before you start developing. For open-source developers who would like to make a port for their own unsupported car, there are two medium post, one more general post and an actual port guide, describing how to port a new car. These are posts made by Comma.ai in order to make sure that when an open-source developer adds a new car port, this is done in the same way as the already supported cars. On top of this, there are tests that the developers can locally run in order to check whether or not their implemented changes/additions have the desired outcome.
The last stakeholder we will take a look at is Comma.ai, which mainly consists of developers, thus the points mentioned in the previous section are also in force here. As the owner and supervisor of the project, every type of variability applies to them and they have a decisive role in this. Looking at the figure, we see the (dotted line) possibility to choose between the communcation protocol. This is simply a design consideration and solely depends on their preference as a company. Additionally, the possibile extension of the supported communcation protocols with flexray is something that they have veto authority on. The reason that Comma.ai made the software open-source is because this would create more variability, as people are able to add a port for their own car. In order to manage this variability, Comma.ai decides which cars get fully supported and which not. This is partially based on whether or not the car is used by a significant amount of people. On top of this, Comma.ai will make sure that the code of a new car port meets the safety and code quality standards that they have set for their product.
Ease of the Variability Management
In order to make sure that the variability stays manageable, Comma.ai has made certain mechanisms and design choices. One of them is a test to check whether or not the supported cars can be identified correctly, with the use of fingerprinting. On top of that, it is also possible to watch replays/simulations from data of previous driving sessions, which can help identify potential causes of bugs during the process of porting a new car or maintaining a supported car. However adding more cars can make the abstraction within the system weaker, because every car requires its own safety model. This causes duplicate code between dbc files of cars with the same brand but a different model. As the abstraction helps managing the variability, it is important that the architecture of the system keeps the abstraction. One way of keeping the abstraction is with the use of an observer like design pattern, as publish subscribe (explained in a previous post). This pattern fits perfectly for openpilot, as openpilot contains multiple different components that need to communicate with one another. Openpilot also uses Cap’n Proto, which creates common typed specifications of car states, further touched upon in the next section.
Implementation Mechanism and Binding Time
This section discusses how openpilot detects which car it is connected to and how different cars are supported.
Fingerprinting
The comma two tries to identify the car it is connected to at engine startup. The series of messages produced on the CAN bus at start is assumed to uniquely identify a car. This series is then matched against a collection of known series, called fingerprints. When openpilot successfully matches against a known fingerprint, it can apply the correct decoding specification to interpret the CAN messages. Later, when sending control messages to the actuators, openpilot is able to take car-specific parameters into account.
Implementation Mechanism
The goal of openpilot is to constantly improve the driving quality and safety. To achieve this, the (machine learning) model and other code to compute adjustments is changed and improved frequently. To avoid having to maintain a dozen different versions for each car, a general CarState object is used as an abstraction layer. A CarState object holds information about the runtime state and user settings. Information in the runtime state includes the current estimation of speed and yaw rate. The user settings includes the set speed limit and acceleration. These CarState objects are created by a car specific carstate.py function from car specific CAN messages. Carstate.py uses a car specific .dbc file containing the CAN message encoding/decoding scheme. It furthermore uses the common typed specification of a CarState object created in car.capnp.
The adjustments computed by the model called by the control loop in controlsd.py are returned as CarController objects. These objects are then consumed by a car specific carcontroller.py script. This script in turn creates the car-specific messages for autonomous driving. This procedure is depicted below.
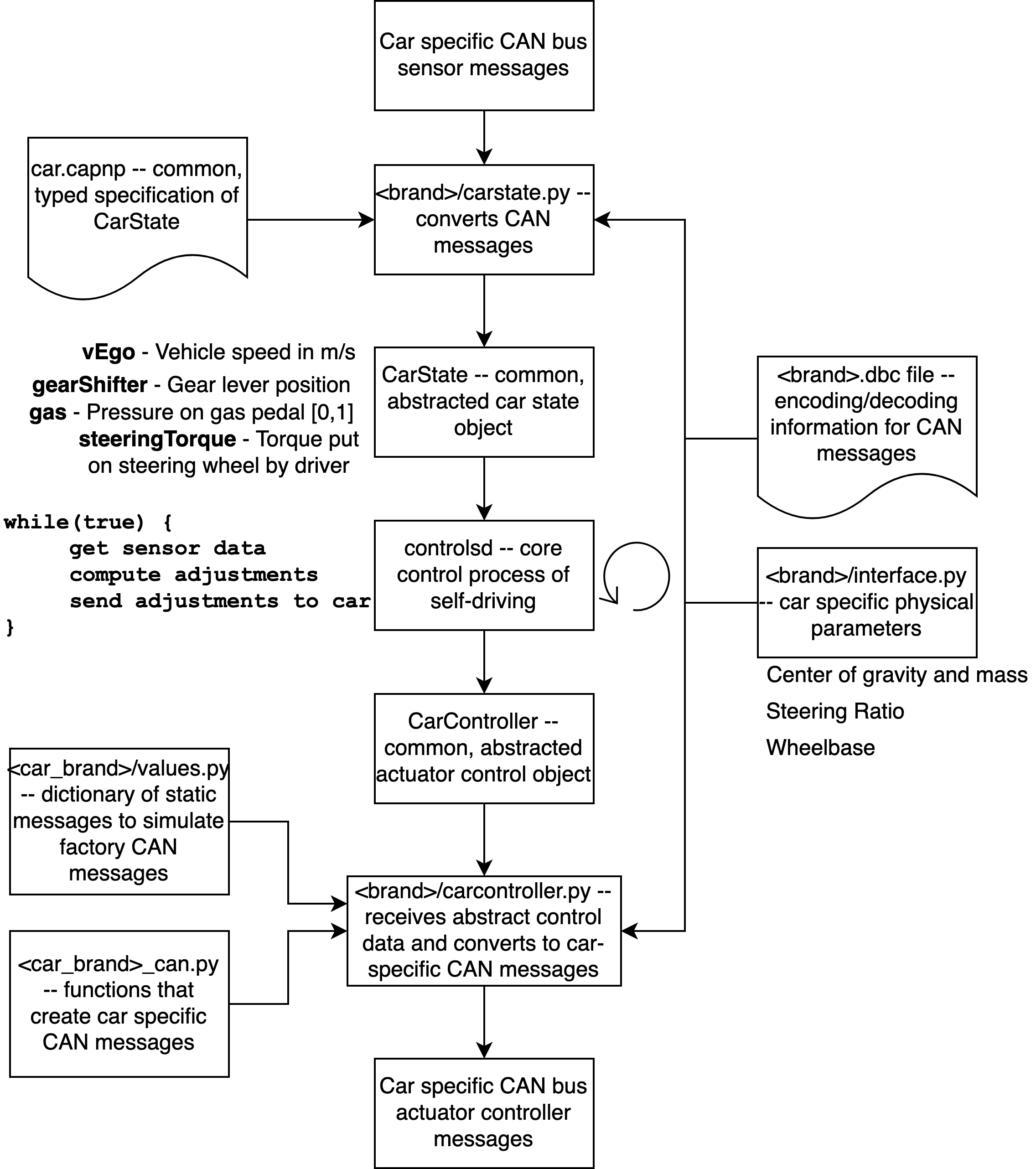
Figure: Variability Implementation
Safety Mechanism
One may wonder how it can possibly be safe to use a model operating on a universally modelled abstracted car. Mistakes in the conversions scripts, carstate.py and carcontroller.py, could result in extreme fluctuations in inputs and outputs. To prevent dangerous situations on the road, the Panda, a hardware adapter responsible for the communication between the comma two and the CAN, constantly monitors the actuator messages the comma two wants to apply. It compares the messages against a safety model in the Panda, and if the changes are too abrupt with respect to the current state, it ignores such messages and requests for user engagement.
Variability Galore!
In this post we identified the main aspect of variability with respect to impact on the architecture: the controlled car (platform). We see that increasing the amount of supported cars and easing maintenance is a shared goal of all stakeholders. The architecture realises this goal by operating on a universal car state. Having implemented a car abstraction layer eases the process of adjusting the model for all cars at once. Adding a new car simply boils down to providing the correct car-specific information files and some light tuning. We foresee no problems in adding more and more cars in the future given the current architecture.