tags: Scikit-learn Python Software Architecture Machine Learning Developers Roadmap Stakeholders
In this first blog post, we will examine the following aspects of scikit-learn. First, we will describe what scikit-learn is and what it is capable of doing. Then we will describe what stakeholders are involved in the project and finally, we will lay out a roadmap of future development of scikit-learn. This essay thus gives the necessary context for anyone how wants to study the architecture behind scikit-learn.
Scikit-learn: All Machine learning models with a single API
Let’s start by discussing: what is the problem scikit-learn wants to solve? Scikit-learn is a machine learning (ML) library containing a lot of ML models and techniques. Scikit-learn has been designed to be simple and efficient, accessible to non-experts, and reusable in various contexts.
Scikit-learn is very cautious in its selection of techniques. For example in their selection of new techniques they only consider techniques whereby it is at least 3 years since its publication, it has 200+ citations and it fits in the API of scikit-learn.
All algorithms, both learning and pre-processing, in scikit-learn have been implemented with the same fit, predict and transform API. As soon as you have learned this API you can use any algorithms without knowing the exact details of how it works. It also makes algorithms, for the same learning problem, interchangeable in the code. The API also hides all the complex optimization choices that have to be made. You can control these by changing the hyper-parameters of the estimator. The effects of these choices have been well documented in the API documentation and the provided tutorials of scikit-learn. However, in most cases, this won’t be necessary as one of scikit-learn’s core design principles is to provide sensible defaults. Making scikit-learn efficient and easy to use for non-experts.
Key Capabilities and Properties
Knowing the problem scikit-learn tries to solve, we will provide the key capabilities and properties of the library and discuss how far the library is able to solve ML problems. The scikit-learn library includes a lot of ML algorithms, both supervised and unsupervised1. Moreover, scikit-learn provides algorithms to tune hyper-parameters automatically.
For supervised learning, the problem can either be a classification or regression problem 2. Scikit-learn provides lots of algorithms for these types of problems such as linear models, Bayesian Regression, k nearest neighbours, the decision tree, etc.
Scikit-learn also provides algorithms to solve unsupervised learning problems3, such as clustering, density estimation, etc. The choice of algorithms per problem is also quite diverse as is shown in the image below.
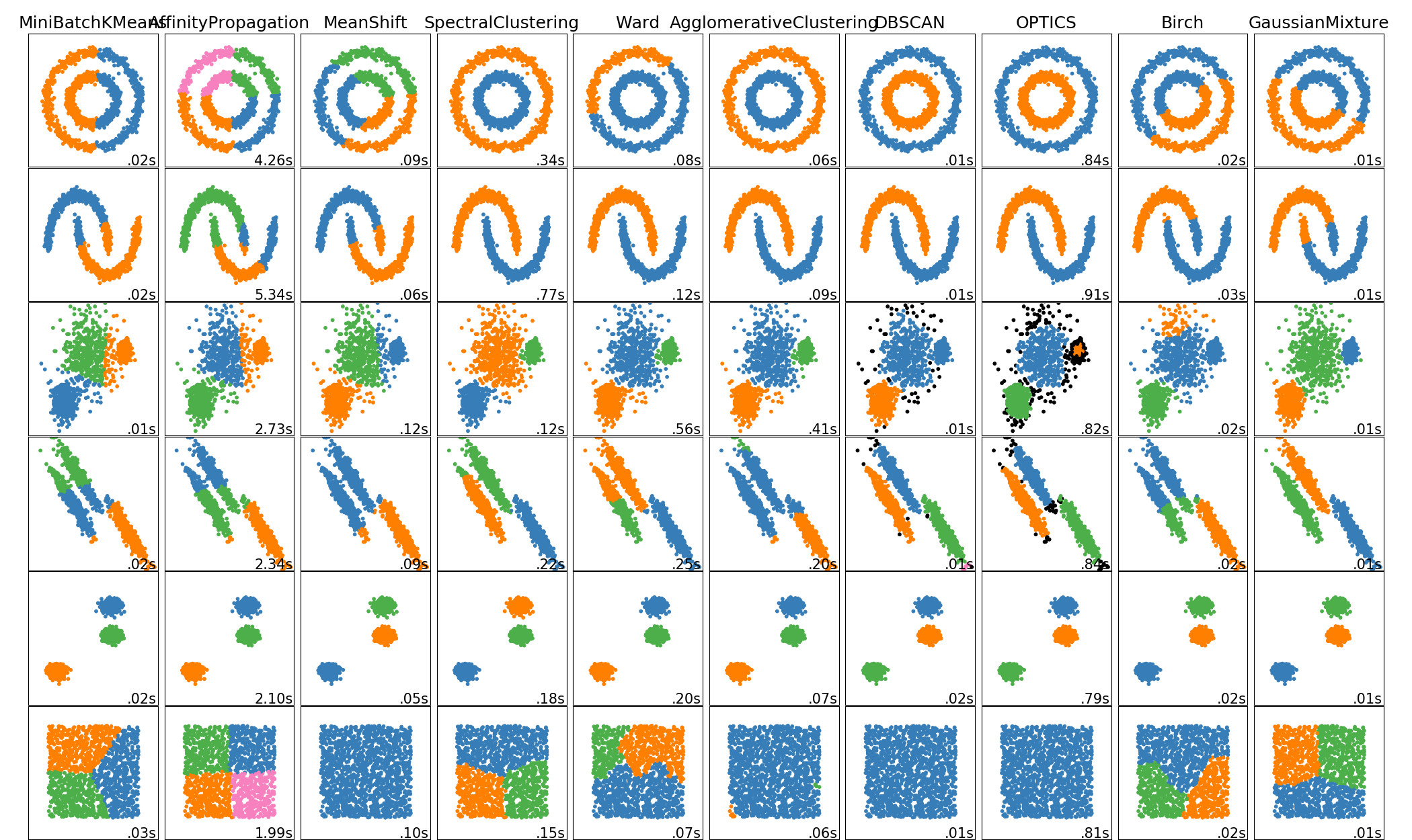
Figure: Different types of clustering algorithms
The image clearly shows how different algorithms perform on different input data. All clustering algorithms require unlabeled data and a function so that it will return an array of labeled training data.
Tuning hyper-parameters can be a lot of work, since it is not always clear what the impact of different values for those parameters are. Luckily Scikit-learn provides a tool4 to automatically find the best set of hyper parameters via cross validation.
Presenting the solution to the users
So that is the problem scikit-learn wants to solve. Now let’s discuss how scikit-learn presents its solution to its users. Let’s discuss this using the end-user mental model from the book: Lean Architecture 5. This model consists of two parts. First, let’s discuss the “What is the system?” part. For the users, scikit-learn is an API that consists of 3 types of core components:
| Component | Description |
|---|---|
| Estimators | Every algorithm, both learning and data-processing, in scikit-learn are implemented as an estimator. This creates a universal way of initializing algorithms and retrieving both the hyper and learned parameters. |
| Predictors | These are estimators that implement the predict & score related methods. These are for example algorithms that do classification, regression, clustering, etc. |
| Transformers | These are estimators that implement the transform related methods. They are mostly used to modify or filter data as a pre-processing step before feeding the data to Predictors. For example, both PCA and one hot encoding are transformers. |
Scikit-learn also has 3 more components that are based on the composition of estimators:
| Component | Description |
|---|---|
| Meta estimators | These are estimators that combine one or more estimators into a single estimator. This allows us to transform a single classification estimator into a multi-classification estimator or to reuse other predictors in an ensemble method. |
| Pipelines | Pipelines combine multiple transformers and their final predictor into a single estimator. This means that all fit, transform and predict methods are combined into a single method. Making a pipeline less error-prone for future predictions. |
| Model selector | These are meta-estimators, that will train the estimator multiple times with different values for the hyper-parameters when the fit method is called. It will then expose the best_score_, best_params_ and best_estimator_ as attributes. |
Python does not have interfaces. That is why scikit-learn implements these components via duck typing and estimator tags.
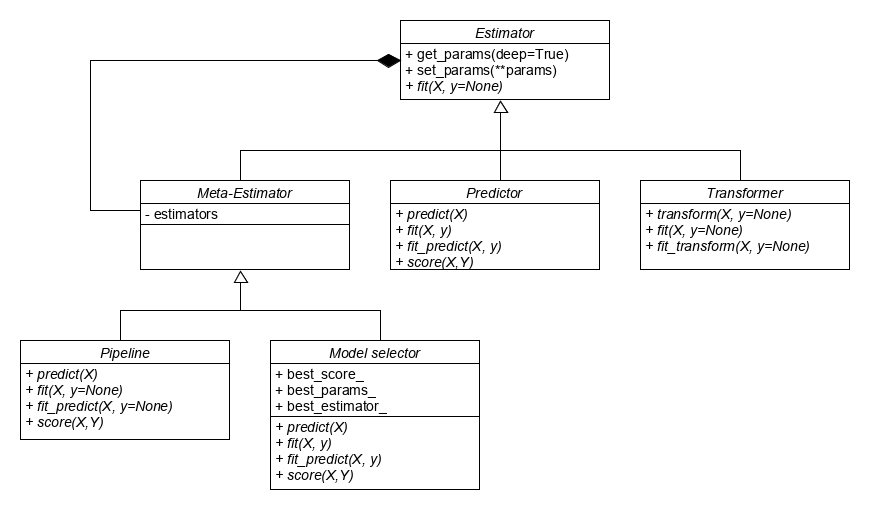
Figure: UML of the scikit-learn components
Now, let’s discussed the “what the user does with the system” part using these components. Scikit-learn provides its users with the ability to train and use ML models. Which means that a typical scikit-learn user will encounter 2 types of use-cases, whereby the user encounters all the previously defined components.
First, let’s look at the model training use-case. Hereby the user selects a predictor and one or more transformers to pre-process the data. He then combines these into a single pipeline. The user then searches for the best set of hyper-parameters using model selection. And finally, the resulting model is tested and if deemed sufficiently accurate is stored using pickle to await usage in production.
The second use case is using the predictor in production. In this use-case the user loads the pre-trained model from disk. This restores the entire pipeline the user has created in the first use-case. Allowing the user to start making predictions without setting up a new pre-processing pipeline as this is already part of the loaded model.
This is scikit-learn solution and how it presents it to its users. However one question still remains.
Who is involved?
For any project it is crucial to identify the stakeholders, as they determine how to project evolves. More importantly, if a project fails to identify stakeholders, it might abandon its audience which would make the project irrelevant. An extensive stakeholder analysis has been performed previously in the 2017 edition of the course 6. The current analysis builds heavily upon that edition. However, the project has evolved since then and it is important to clarify the changes. We propose a similar categorization of stakeholders to the previous analysis. That is, a categorization as follows:
- Contributors: Anyone contributing to the code base in some form.
- Users: Organizations or individuals that utilize scikit-learn.
- Funders: Entities that support scikit-learn in some form, either material (e.g. providing servers) or monetary.
- Competitors: Tools/libraries/frameworks that are similar to scikit-learn and might target the same userbase.
| Stakeholder Category | Stakeholder |
|---|---|
| Contributors | Core contributors (Jérémie Du Boisberranger, Joris Van den Bossche, …), Community Contributors (> 1600) |
| Funders | Members of the Scikit-Learn Consortium, Columbia University, Alfred P. Sloan Foundation, The University of Sydney, Anaconda Inc |
| Users | J.P. Morgan, Spotify, Inria, betaworks, Evernote, Booking.com, and more |
| Competitors | TensorFlow, PyTorch, MLlib (Spark), Dask |
The table shows an overview of the relevant stakeholders according to this categorization at the current state of the project. Note that there are several differences compared to 2017. This probably follows from the changes in context that the system operates in as well as general project evolution. The relevant stakeholders were derived from the project’s website 7. Note that in particular, the list of competitors has changed compared to 2017.
Having described the role of the stakeholders in scikit-learn, we now look forward to see its role in the world in the future.
What can we expect from scikit-learn in the future?
At the time that scikit-learn was developed and released, none of the now equally popular ML frameworks (e.g. PyTorch or TensorFlow) existed. Therefore, scikit-learn was the pioneer in providing a framework for ML. The first public release was in 2010 and consecutive development benefitted greatly from a large international community. PhD students in ML formed a significant part of the contributor community. However, currently these students are more likely to contribute to one of the other popular ML frameworks (as acknowledged by the authors of scikit-learn). Scikit-learn currently operates in a time where ML is experiencing unprecedented popularity. So how will this library continue to grow in such a different context?
Although scikit-learn has been a prominent framework within the ML world, it has also suffered from the paradigm shift within the field. People tend to move to deep learning oriented frameworks like PyTorch and TensorFlow.
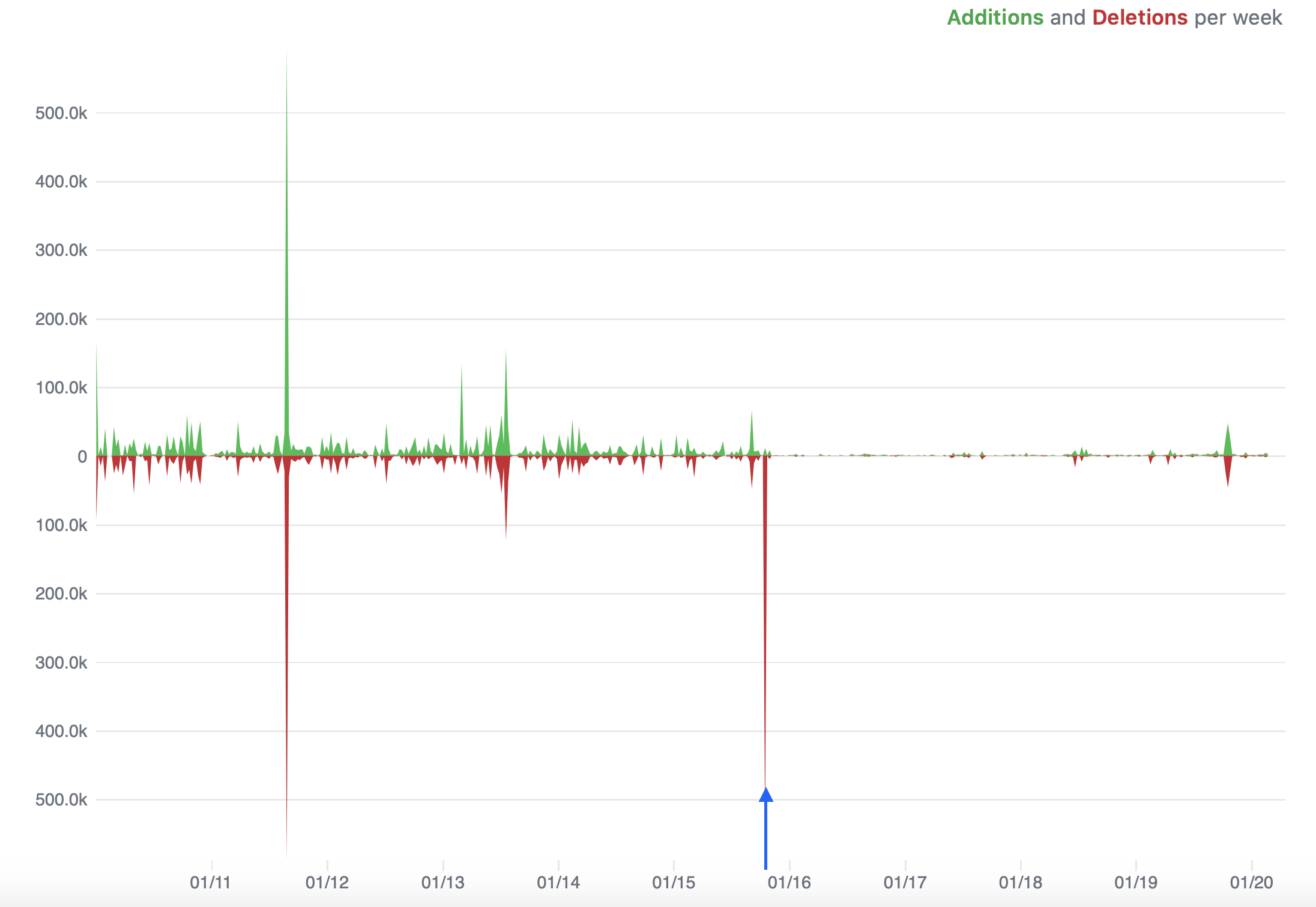
Figure: Code frequency of the scikit-learn github repo
The graph above 8 depicts the code frequency of the scikit-learn github repository. The blue arrow indicates the launch date (November 2015) of Tensorflow. The release of the, deep learning capable, framework seems to be a likely cause for the decline in attention for scikit-learn.
Even though the decline of contributions is acknowledged by the creators of scikit-learn 9, they are not less encouraged to provide a high-quality, fully maintained and well-documented collection of ML and data processing tools. The methods used to realize this objective have improved with more advanced computational tools and better high level python libraries like Cython and Pandas 9.
The main goals then, in this era of the project, as stated by the scikit-learn team are to 9:
- maintain a high-quality, well-documented set of ML and data processing tools within the scope of interest of the scikit-learn project (predicting targets with simple structure).
- make it easier for users to develop and publish external components.
- improve integration with modern data science tools and infrastructures.
We think that keeping the toolkit powerful, yet easy to access, keeps it a gateway into the world of ML, but that making sure that the supported frameworks are up to date will help it to stay relevant in this era.
-
https://scikit-learn.org/stable/tutorial/basic/tutorial.html#machine-learning-the-problem-setting ↩
-
https://scikit-learn.org/stable/supervised_learning.html#supervised-learning ↩
-
https://scikit-learn.org/stable/unsupervised_learning.html#unsupervised-learning ↩
-
https://scikit-learn.org/stable/getting_started.html#automatic-parameter-searches ↩
-
Lean Architecture: for Agile Software Development by James O. Coplien, Gertrud Bjørnvig ↩
-
https://delftswa.gitbooks.io/desosa-2017/content/scikit-learn/chapter.html ↩
-
https://scikit-learn.org/stable/about.html ↩
-
scikit-learn_code_frequency: https://github.com/scikit-learn/scikit-learn/graphs/code-frequency ↩
-
scikit-learn_roadmap: https://scikit-learn.org/stable/roadmap.html ↩ ↩2 ↩3