tags: Scikit-learn Python Software Architecture Machine Learning Developers Roadmap Stakeholders
Scikit-learn’s main goal is to make machine learning as simple to use for non-experts while remaining as efficient as possible. To do this scikit-learn has to hide all the complexities and variations between the different machine learning algorithms. In this blog post, we will explore how these requirements have resulted in the current architectural style and which trade-offs have been made to achieve it.
Architectural design choices
Scikit-learn has made 3 key architectural design choices to implement its goals.
Firstly, scikit-learn truly embodies the design idiom: “program an interface, not an implementation”.
From a users perspective, all estimators have the same API.
Even though they are doing completely different things behind the scenes 1.
They make the usage of different machine learning algorithms as easy as learning the very small and well-defined API, while still allowing developers to change the behaviour behind the scenes through hyper-parameters.
Secondly, scikit-learn is designed as a library, not a framework.
There is no need to inherit from a specific class.
Users only need to import the required modules and instantiate the object with the desired functionality.
This design property makes scikit-learn easier to use.
It also helps the developers to create a more modular structure in the code.
Thirdly, the creation of an estimator has been decoupled from the learning process.
Hyper-parameters are provided at the creation of the estimator.
When the fit method is called with the training data the hyper-parameters are considered frozen.
This design choice is similar to the idea of currying. This choice allows users to combine multiple estimators into a single pipeline estimator with the same API.
These design choices also put some additional constraints on the non-functional requirements. Which meant that some trade-offs had to be made.
Non-functional trade-offs
To achieve its goals scikit-learn had to make 3 architectural design trade-offs:
-
Readability vs Performance: Readability is, in general, deemed more important as this helps to improve understanding and ease of maintainability. When implementing algorithms it is prefered to implement them in Python using Numpy and SciPy. To make use of their readability and vectorized performance properties. However, in some cases, it is not possible to efficiently implement algorithms using only vectorized code. Only then is it allowed to implement the bottleneck parts using Cython to improve performance 2.
-
Performance vs API design: Scikit-learn wants to gain as much performance from vectorization as possible 2. Vectorized algorithms achieve higher performance on batched inputs rather than single sample inputs. That is why scikit-learn’s API has been designed to prefer batched inputs over single sample inputs 3. This is also the reason why data is encoded as NumPy arrays instead of objects.
-
Usability vs Decoupling: In its design, scikit-learn has decided to combine the model factory (estimators) and the trained model produced by the factory (models) into a single object. This increases useability since there is no need for a second class. It also increases understandability as there are no parallel class hierarchies. Due to this choice users have to deal with more complex software dependencies in some specific cases, such as exporting fitted models 3. However, since these there are fewer of these cases, scikit-learn has chosen usability over decoupling.
We now know the key architectural choices that have been made to implement scikit-learn. Now let’s look at how they affected the development, runtime and the deployment view.
Development view
The development view “describes the architecture that supports the software development process”4. Rozanski et al. specify six main concerns and we will cover them in this section.
Module Organisation
Our colleagues from 2017 5 have already discussed the module organisation aspects. They have, for example, already discussed the grouping of related code in the code base4. The structure of scikit-learn has not changed a lot over time, so we will extend on their work by adding other viewpoints and other common practices within scikit-learn development with help of the other five criteria.
Common Processing
It is important to identify and isolate common processing into seperate code units4 and in Figure 1, which contains the dependency graph of the scikit-learn code base, we can see that scikit-learn has achieved this with three packages: sklearn, which is the base package, utils, and metrics, which contains code for evaluating prediction performance6.
utils contains utilities specified by a list of common development practices which means tools in several categories such as linear algebra & array operations, matrix operations, random sampling and input validation tools. Furthermore, it is encouraged to let the NumPy and SciPy libraries handle as much of the processing as possible2. As stated earlier, scikit-learn has also added support for Cython which allows c-like performance within Python7. The use of Cython is encouraged when “an algorithm cannot be expressed efficiently in simple vectorized NumPy code”2.
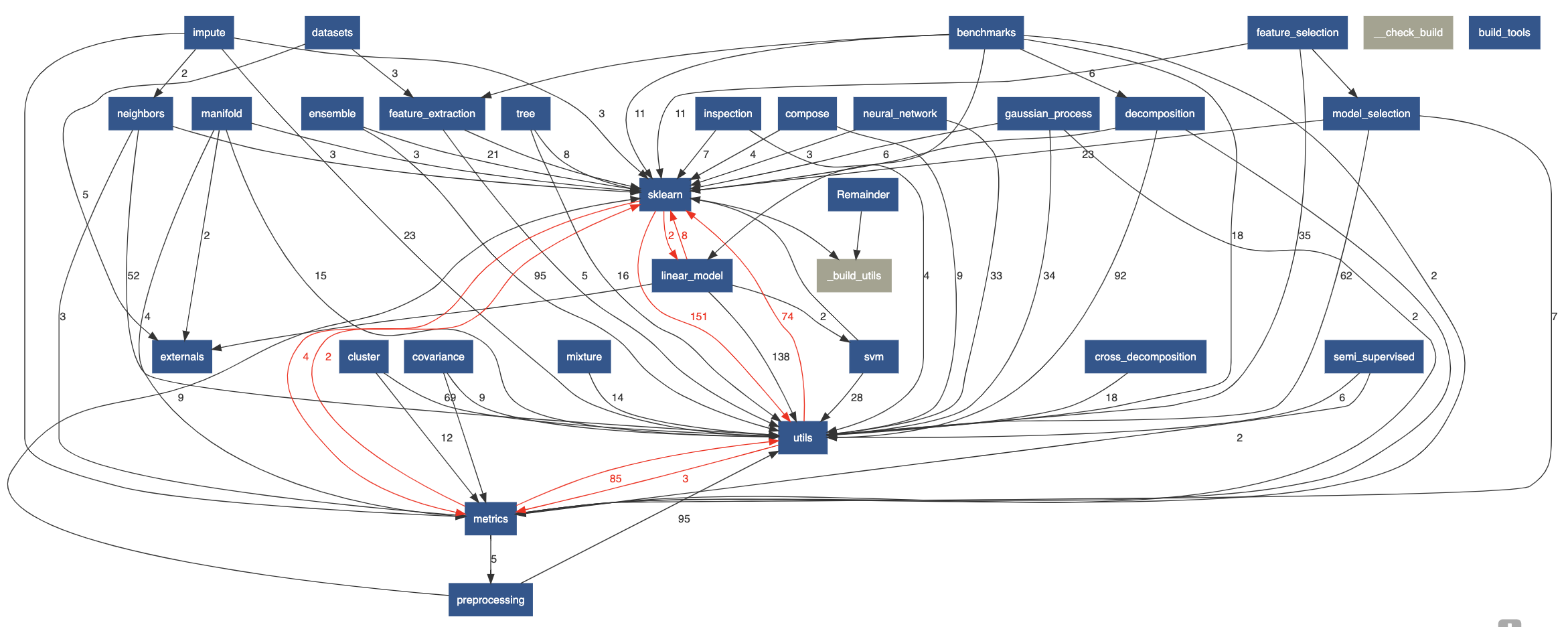
Figure: The dependency graph of the scikit-learn code base.
The dependency graph of the scikit-learn code base.Standardisation of Testing
Testing in machine learning frameworks is very important as bugs do not necessarily have to be apparent on the surface. The code can still run without errors or slow-downs and networks will still train and losses will still drop 8. Scikit-learn is no exception. Thus scikit-learn expects all code to have a test coverage of at least 90%. All testing is done using the pytest9 package and each package in de code base has a dedicated test folder.
Instrumentation
Rozanksi et al. define instrumentation as “the practice of inserting special code for logging information about step execution, system state, resource usage, and so on that are used to aid monitoring and debugging” 4. However, there are no best practices specified on instrumentation in the scikit-learn guide, but there are practical guidelines for optimization using IPython10 which will highlight issues in the code regarding memory usage and processing bottlenecks2.
Codeline Organisation
All code resides on GitHub and multiple continuous integration (CI) systems are used. Azure CI is used for platform specific (e.g. Windows/Linux/macOS) testing, CircleCI is used to build documentation for viewing and some Linux specific testing11. Travis CI is used for development builds where also non-stable libraries are used. These CI jobs run in set intervals as opposed to after each pull request because their failure does not necessarily have to do with errors in pull requests12. Furthermore, scikit-learn specifies a lot of guidelines regarding contributing code and for the pull request reviewing process in order to guarentee stability11. Backward compatibility is delivered by supporting deprecated methods for two releases and annotating them as deprecated in that time11.
Standardisation of Design
The main design pattern used in the scikit-learn codebase is the fit-predict-transform-estimator API we discussed in our first post “Scikit-learn, what does it want to be?” so we recommend reading that if you have not already.
Now that we considered the design from a development perspective, we focus on the concerns a user might have at runtime.
Runtime view
A runtime view defines how components interact at runtime to realize key scenarios 13. In the case of scikit-learn, this involves the entire pipeline as described in the previous section. First, let’s describe the (runtime) dependencies that scikit-learn contains:
- Python, version:
3.5+ - Numpy, version:
1.14.0+ - Scipy, version:
1.1.0+ - Matplotlib, version:
1.5.1+(only for plotting capabilities) - scikit-image, version:
0.12.3+(only for some examples on website) - pandas, version:
0.18.0+(only for some examples on website)
Having established runtime dependencies, let’s investigate how the components described previously interact at runtime.
One of the great aspects of scikit-learn from an architectural perspective is that the architectural design allows for a very modular specification of the model. It is therefore easy for a user to adapt his/her model to changing needs. The only interaction with each model is through the functions: fit, predict and transform. Therefore, at runtime, the dependencies are only through the estimators and their nested calls. Scikit-learn has, as mentioned in the previous essay, two main use-cases: Selecting a model and processing the data to train the model and applying the model in production.
In the first use case, the user selects a model to use for fitting the (labelled or unlabelled) data. Data can also be preprocessed in some way (separating labels from features, etc). Data must be provided in the form of a NumPy array. Once the user has selected a model and has formatted the data correctly, he can begin to train the model by calling the fit function on the data. This returns the model with trained parameters. Thus the same model is returned, but its internal state has changed. This reveals the clever architectural design discussed previously. While the user is able to interact with all the models in a similar fashion, the complexity that runs behind that interface is hidden away from the user. Also, as described earlier, the user needs not implement any classes in order to use scikit-learn to train a model.
The second use case involves using the model trained previously and applying it to an (unlabelled) data set. Data can be classified using the predict function of the model. This returns labels which can consequently be used for plotting, checking, etc. Again, the architectural design that we have discussed so far hides away the complexity of applying the model to the data. In addition, the interaction during end-to-end execution is only with the scikit-learn library. This hides away all dependencies that might occur if it were implemented with inverted control.
There are many more involved use cases, but the previously highlighted scenarios illustrate the general execution of the project in a runtime fashion. More examples of use-cases can be found on the website.
Deployment view
Now that the runtime view has been established, we will consider the deployment view. This describes how the application is deployed such that the end-user, developers who want to use scikit-learn, can use it. We will illustrate how the system can be deployed on a computing system and what (runtime) requirements the system imposes on that system 14.
Scikit-learn can be deployed through Python package managers such as pip and conda. The installation is relatively straightforward, the user simply has to type the installation command for each respective package manager: pip install scikit-learn (pip) or conda install scikit-learn (conda).
However, to deploy scikit-learn, there are some minimum system requirements. The theoretical minimum requirements are any minimal computing machine that can run Python and has enough disk space to install all the dependencies. Python does not officially have any minimum hardware requirements, but one can assume that anything that can perform basic computing tasks can run Python (Python is known to being able to run on small devices like a Raspberry Pi).
In practice, however, one would require a much more sophisticated computing system to run scikit-learn. Since machine learning problems often involve repeated intense calculation on big data sets, one would expect a system running scikit-learn to have above-average hardware specifications.
Conclusion
In this essay, we have explored how the previously outlined vision of scikit-learn has been translated into its architecture. One of the advantages of scikit-learn’s API design is that it allows for a very modular use where one model can be easily replaced by another for changing requirements. This essay also considered all components and provided an analysis of the six concerns outlined by Rozanski et al. 4. Furthermore, we considered other views of the architecture: the runtime, deployment and non-functional view.
-
# Scikit-learn, what does it want to be? https://desosa2020.netlify.com/projects/scikit-learn/2020/03/06/scikit-learn-what-does-it-want-to-be.html ↩
-
How to optimize for speed, https://scikit-learn.org/dev/developers/performance.html ↩ ↩2 ↩3 ↩4 ↩5
-
API design for machine learning software: experiences from the scikit-learn project, https://arxiv.org/pdf/1309.0238.pdf?source=post_elevate_sequence_page————————— ↩ ↩2
-
Nick Rozanski and Eoin Woods. Software Systems Architecture: Working with Stakeholders Using Viewpoints and Perspectives. Addison-Wesley, 2012, 2nd edition. ↩ ↩2 ↩3 ↩4 ↩5
-
DESOSA 2017, https://pure.tudelft.nl/portal/files/37061591/desosa_2017.pdf ↩
-
Model Evaluation, https://scikit-learn.org/stable/modules/model_evaluation.html#model-evaluation ↩
-
Cython, https://cython.readthedocs.io/en/latest/ ↩
-
How to unit test machine learning code, https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765 ↩
-
pytest: helps you write better programs, https://docs.pytest.org/en/latest/ ↩
-
IPython Documentation, https://iPython.readthedocs.io/en/stable/ ↩
-
Contributing, https://scikit-learn.org/dev/developers/contributing.html ↩ ↩2 ↩3
-
Maintainer / core-developer information, https://scikit-learn.org/dev/developers/maintainer.html ↩
-
https://www.viewpoints-and-perspectives.info/home/viewpoints/operational/ ↩
-
https://www.viewpoints-and-perspectives.info/home/viewpoints/deployment/ ↩