tags: Scikit-learn Python Software Architecture Machine Learning Developers Code Quality Testing Coverage Contributions
In our previous blog posts 1 2, we examined the vision and goals behind scikit-learn and discussed how these elements have been combined into the underlying software architecture. We considered several views and perspectives in which the software product operates and the trade-offs that were made to balance functional requirements with non-functional requirements.
In this blog post, we will evaluate how scikit-learn safeguards its architectural, code and testing quality. Ensuring quality is essential for any open source project since contributors might have a wide variety of quality standards or use different conventions for programming. Therefore a project should specify clear guidelines that people can use. In addition, we will relate the latest code changes to the roadmap specified by the authors.
The first section discusses the concrete guidelines that are in place for contributing. Then we will investigate how these guidelines are used in practice, followed by an analysis of how effective the guidelines are. Finally, we investigate the current focus of the project and how it relates to the quality guidelines as well as the previously specified roadmap.
The plan
Before evaluating the state of code quality in the project, we will consider how the project managers encourage contributions to the project. Proper guidelines are crucial for contributors to be able to make a valuable contribution.
The repository of scikit-learn on Github links to several documents providing guidelines for contributors on the website 3 4. In addition, the repository contains a CONTRIBUTING.md file providing a summary of the information mentioned in the larger documents on the website.
The extend of the guidelines indicates that the authors of scikit-learn appreciate community contributions to the project and are certainly welcoming to changes and contributions to the project. Let’s investigate what the specific guidelines specify.
PR/Issue guidelines
Formulating clear issues and pull requests are important to the project. There are specific guidelines for bug reports in particular. Bug reports need to contain extensive information regarding the issue and the surrounding environment in which the problem occurred. (stacktrace, code snippets, OS version, etc.).
There are templates for both issues and pull requests. Issues fall into five different categories: Bug report, Documentation improvement, Feature request, Usage questions and “Other”. Each type of issue has its associated guideline. Pull requests are not divided into sub-categories as they all follow the same template. However, contributors must follow a checklist 5 before they are allowed to submit their pull request. During code review, the scikit-learn maintainers will take a set of code review guidelines 6 into account.
Coding guidelines
Using guidelines scikit-learn is able to maintain a standardised format over the whole codebase, with over 1600 contributors 7. There is a special chapter dedicated to contributing code 6 which specifies how you can contribute. This process is a bit more involved then branching from the main repository and changing the code. The authors recommend users to fork the repository on Github and build scikit-learn locally.
There are no specific guidelines on coding conventions/style but the review guidelines 6 specify to what quality standards the code must comply. Code needs to be consistent with the scikit-learn API as described in our previous essay 2, as well as have necessary unit tests associated with each component. Readability and documentation are also important for a good contribution. Finally, and more relevant to the specific case of scikit-learn, the efficiency of the code is also taken into account during the review. Some guidelines on coding style and conventions can be found spread across the guidelines for contributing page 4.
Test guidelines
Scikit-learn has a very high test coverage, as mentioned in the previous post 2. This implies that testing is considered very important for developers of scikit-learn. The guidelines 6 specify that all public function/class should be tested with a reasonable set of parameters, values, types and combinations between the former. In addition: the guidelines refer to an article explaining conventions for writing tests in python in general 8.
List of CI Tools
Scikit-learn uses a variety of tools for Continuous Integration (CI). Every contribution must be guaranteed to not cause faults in different parts of the system. Depending on the part of the system that is affected, a commit might have up to 19 CI checks!
Three tools are used to run CI 9:
- Azure Pipelines is used to test scikit-learn on different Operating Systems using different dependencies and settings;
- CircleCI is used to building the documentation, linting the code and testing with PyPy on Linux;
- CodeCov is used to measure code coverage of tests across the system.
Execution
All these guidelines and CI tools are only useful if they are actually effective and are being consulted by developers. In this section, we explore the impact of these guidelines and CI tools.
Code coverage overview
The pull request reviewing guidelines state all code added in a pull request should aim to be 100%. Untested lines are only accepted with good exceptions[^scikit-learn-contributions]. With this guideline, scikit-learn aims for total code coverage of at least 90%4. When running the code coverage tools on version 0.23.dev0 we found a branch coverage of 96%. This shows that the goals on code coverage set by the scikit-learn guidelines are realised.
Effect of failing tools in Pull Requests
Scikit-learn developers aim to maintain a high level of code quality in the master branch of the scikit-learn repository. To illustrate this, we added a selection of comments from pull requests. In these images, it is clear to see that even small issues like code quality warnings are addressed.
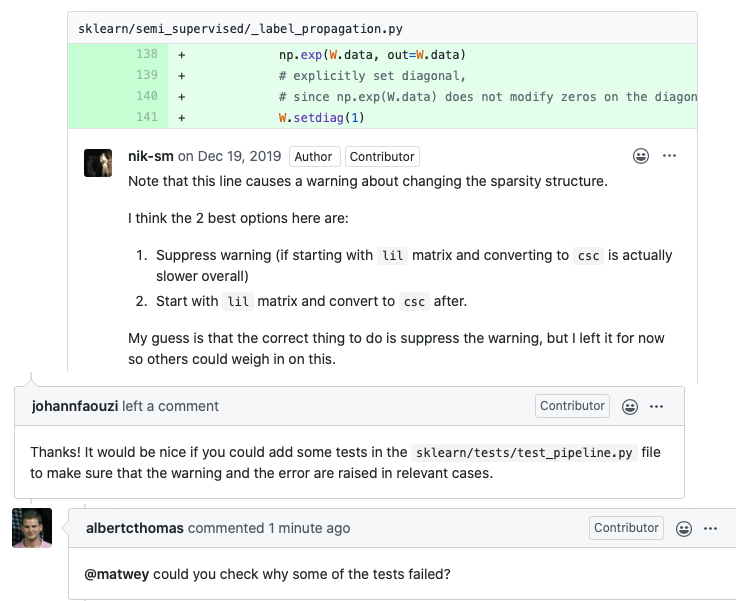
Figure: Comments from pull requests 15922, 16714, and 16721 respectively.
Furthermore, investigation of the list of pull requests reveals that new features are almost never merged when the pipeline is failing.
Analysis of the effectiveness
In this section, we will first discuss the SIG results and how they are related to the code quality plans. Then we will discuss how these results are related to the technical debt in scikit-learn.
The relationships between the SIG results and the code quality plan
SIG has run a maintainability analysis on a snapshot of the master repo from 20-02-2020.
| Type | Rating |
|---|---|
| Test code ratio | 120.2 % |
| Volume | 4.3 / 5 |
| Duplication | 4.0 / 5 |
| Unit size | 1.7 / 5 |
| Unit complexity | 1.6 / 5 |
| Unit interfacing | 0.5 / 5 |
| Module coupling | 3.6 / 5 |
| Component balance | 4.5 / 5 |
| Component independence | 2.3 / 5 |
| Component entanglement | 2.1 / 5 |
There are four important things to note in this table. Firstly, there are more lines of test code than lines of production code. Which means that the test guidelines have paid off. Secondly, the duplication and the module coupling metrics have also scored very high. This is an indication that the strict review guidelines also have paid-off. Thirdly, the unit related metrics score very poorly. This is mostly caused by the relatively high amount of arguments used in scikit-learn functions. Scikit-learn prefers to improve useability and readability by using keyword arguments instead of encapsulating these parameters in an object 1. All the keyword arguments also have a default value to improve usability, which increases the McCabe complexity 10 as a side effect.
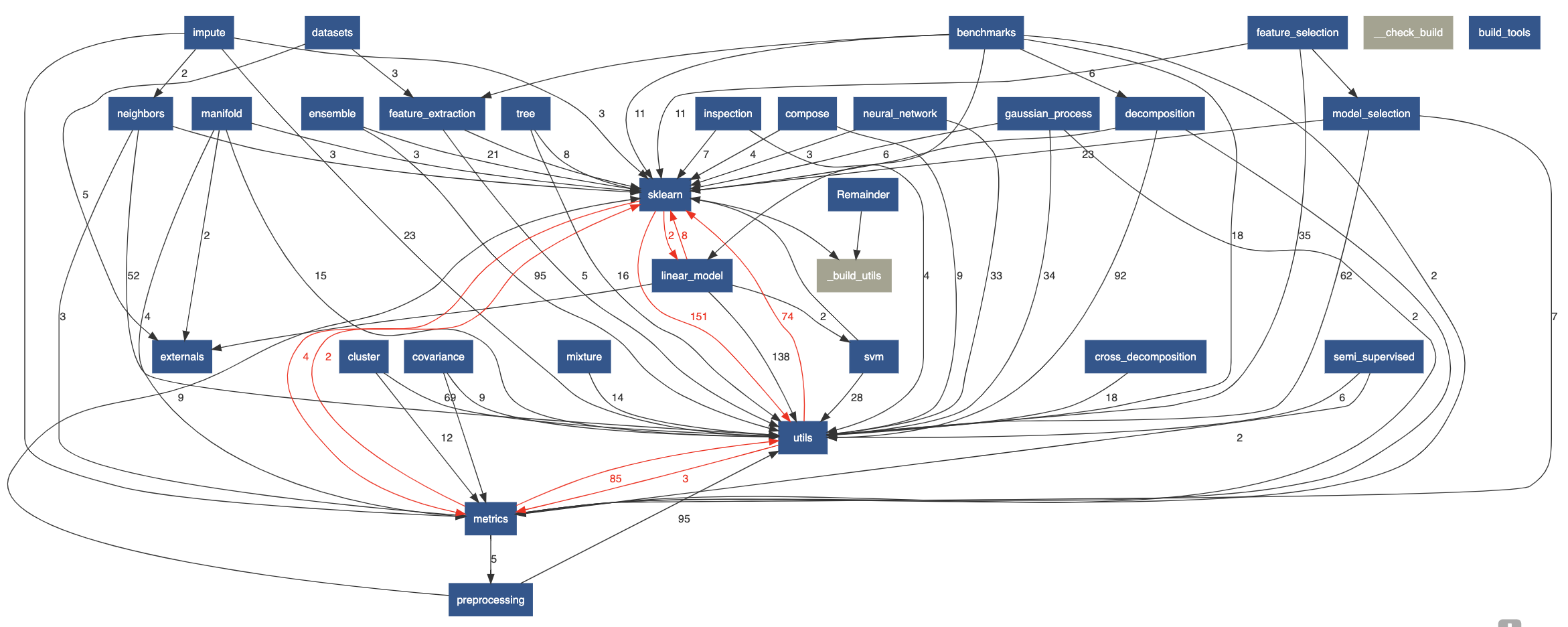
Figure: The dependency graph of the scikit-learn modules. The red arrows indicate cyclic dependencies.
Finally, the component independence and entanglement are a bit on the low side. This is caused by the cyclic dependencies between thesklearn, metrics & utils modules as can be seen in figure. Which is interesting because there are no specific guidelines or plans to prevent these kinds of issues.
Technical debt and possible refactor options.
SIG has also provided a list of possible refactoring candidates that will help to reduce technical debt. We will discuss the three refactor categories we deem the most useful for scikit-learn.
Firstly, the McCabe complexity in some functions is very high. This complexity is mostly created by very long functions or by branches that are responsible for checking the pre-conditions on different (optional) parameters. Either way, we recommend that scikit-learn tackles this problem by splitting these functions into smaller ones. This will not only decrease the complexity but also increase the readability and maintainability of the code 11.
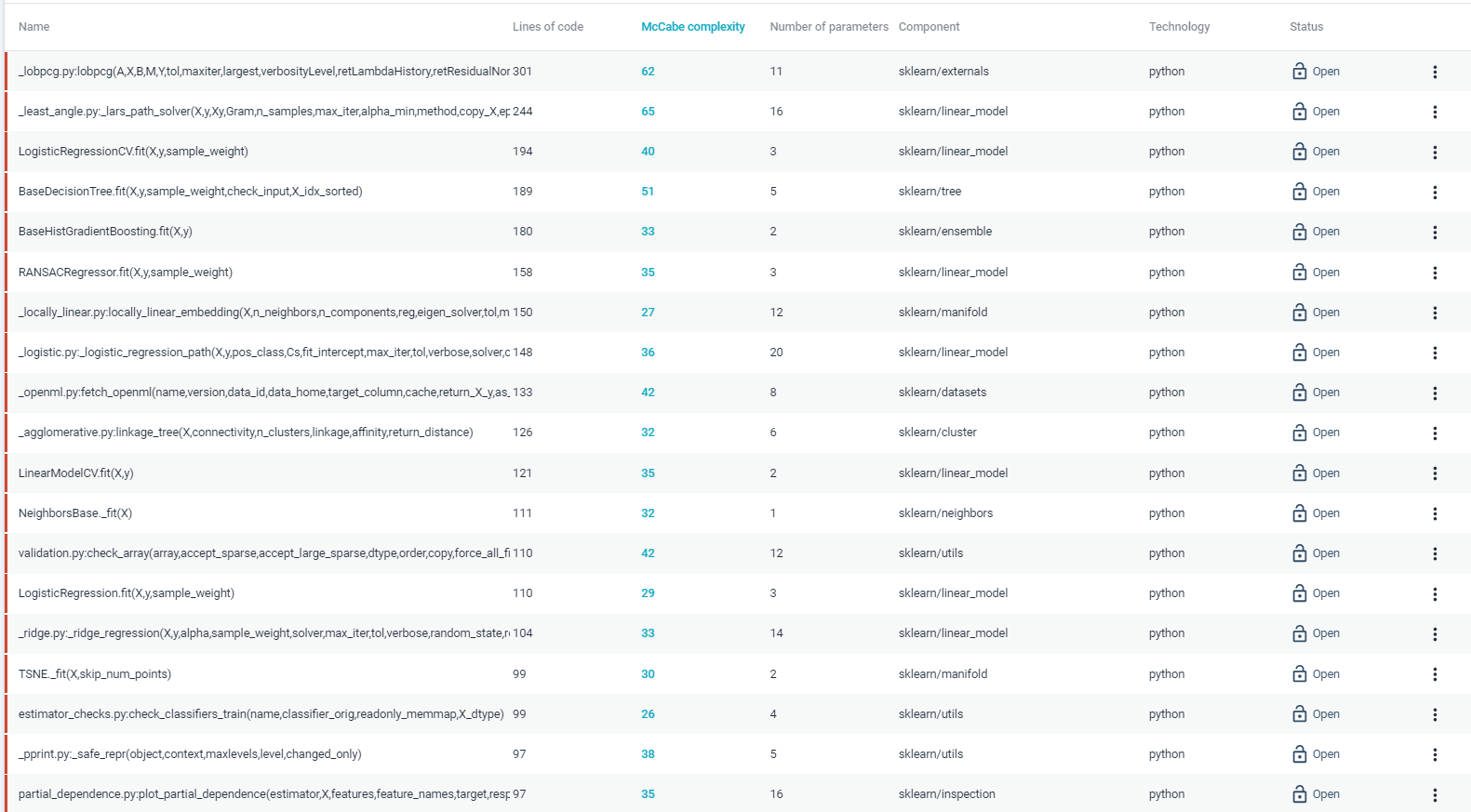
Figure: A subsection of the recommended unit complexity refactors.
Secondly, there are cyclic dependencies between the sklearn, metrics & utils modules that should be solved.
Cyclic dependencies are dangerous because they can cause unexpected bugs that are very hard to resolve.
They also limit the flexibility in developing new features as developers need to work around these cyclic dependencies.
Scikit-learn realized this and is currently adressing it 12.
Thirdly, the number of function arguments in scikit-learn is relatively high as indicated by the unit interfacing metric. This is a design choice so we won’t recommend them to change this 1 2. However, what has become a problem is that scikit-learn accepts both positional & keyword arguments. Making it easy to introduce swapped argument bugs. The contributors have also realized this and they are planning to solve this by only allowing keyword arguments as stated in SLEP009. Which is a statement that updates their future API roadmap.
Coding Activity
The analysis by SIG are a good indication of how scikit-learn is doing and where it can improve, but does this really represent the current focus of the library? In this section we will discuss the hotspots and the mapping of the system’s roadmap onto the architectural components and its underlying code.
Scikit-learn’s hotspots
Using the git history, were are able to discover the hot spots of the scikit-learn repository. We have mapped the 20 most changed files overall and of the past 6 months in a bar graph and we can see in the figure below that the main focus in both cases is in the documentation.
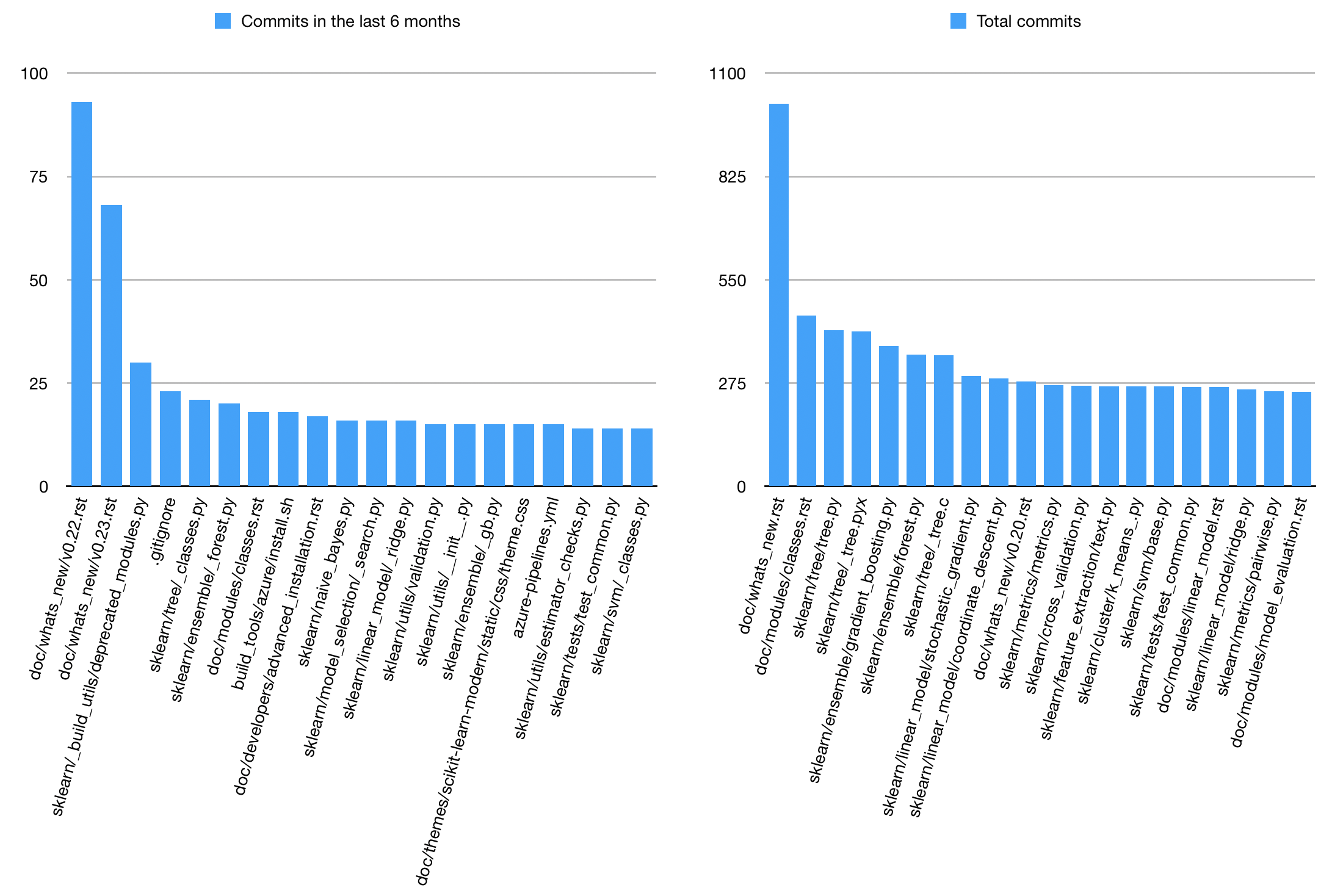
Figure: Amount of commits per file in the scikit-learn repository from the past 6 months and in total untill 25 March 2020 of the 20 most changed files.
The most recent coding activity is located in utility files. Those files contain tools, which are meant to be used internally in scikit-learn to help with development13. For the total amount of commits, most of the work is in the different machine learning models.
Relation to the roadmap
As described in an earlier blog post1, the roadmap of scikit-learn is focussed on maintaining high quality and well-documented models, to make it easier for developers to develop external components and to improve the integration with modern data science tools. We can see in the coding activity of the recent months that scikit-learn is most active in the documentation and utility files. The improvement in the documentation makes it easier for people to understand scikit-learn. The improvements and additions of utility files make scikit-learn easier to use for developers. So both area’s of improvement reflects scikit-learn’s roadmap.
Conclusion
In this essay, we tried to answer the question: how does scikit-learn seek to safeguard its quality and architectural integrity? We have provided an overview of the guidelines and tools that scikit-learn uses to promote its quality and integrity. We have also analyzed the effectiveness of these measures. Finally, we mapped recent coding activity to the roadmap that was defined previously by the authors.
We found that scikit-learn’s measures have been very effective in promoting quality: the test coverage is very high, there is a strict code review and inadequate code is not merged into the repository. The measures have also been effective with regards to ensuring architectural integrity: most flaws in the code are a result of design choices, not inadequate contributions. However, we found that there are still some refactoring improvements possible. Finally, it seems that recent coding changes reflect the desired changes laid out by the roadmap. These are mostly focussed on utilities and documentation.
That being said, a project always keeps evolving and it’s a continuous struggle to maintain a project. However, we are confident that scikit-learn’s measures will ensure a healthy project evolution in the coming years.
-
Scikit-learn, what does it want to be?, T. de Boer, T. Bos, J. Smit and D. van Gelder, https://desosa2020.netlify.com/projects/scikit-learn/2020/03/06/ scikit-learn-what-does-it-want-to-be.html ↩ ↩2 ↩3 ↩4
-
From Vision to Architecture, T. de Boer, T. Bos, J. Smit and D. van Gelder, https://desosa2020.netlify.com/projects/scikit-learn/2020/03/15/ from-vision-to-architecture-20893.html ↩ ↩2 ↩3 ↩4
-
Scikit-learn’s developers guide page, https://scikit-learn.org/stable/developers/index.html ↩
-
Contributing guidelines for developers of scikit-learn, https://scikit-learn.org/stable/developers/contributing.html ↩ ↩2 ↩3
-
Scikit-learn pull request checklist, https://scikit-learn.org/dev/developers/contributing.html#pull-request-checklist ↩
-
Code review guidelines for scikit-learn, https://scikit-learn.org/dev/developers/contributing.html#code-review ↩ ↩2 ↩3 ↩4
-
List of contributors of scikit-learn, https://github.com/scikit-learn/scikit-learn/graphs/contributors ↩
-
Jeff Knupp, Improve Your Python: Understanding Unit Testing, Dec 9, 2013, https://jeffknupp.com/blog/2013/12/09/improve-your-python-understanding-unit-testing/ ↩
-
Contrinous Integration specification for scikit-learn: https://scikit-learn.org/stable/developers/contributing.html#continuous-integration-ci ↩
-
Cyclomatic complexity on Wikipedia, https://en.wikipedia.org/wiki/Cyclomatic_complexity ↩
-
Clean Code by Robert Cecil Martin ↩
-
https://github.com/scikit-learn/scikit-learn/issues/15123 ↩
-
Utilites scikit-learn, https://scikit-learn.org/stable/developers/utilities.html#utilities-for-developers ↩