tags: Scikit-learn Python Software Architecture Machine Learning Developers Configurability Variability Usability Features
So far we have covered many aspects of scikit-learn from a software architectural perspective. In our first essay 1, we described the vision behind scikit-learn. In the second essay 2, we described how this vision translates to an architecture. Then, in our last essay 3, we investigated how scikit-learn safeguards its quality as an open-source system.
In this essay, we will consider another specific architectural aspect of scikit-learn. That aspect is configurability (or variability) and the tradeoff that needs to be made between configurability and usability. It can be hard for systems to balance these two aspects as allowing users to have more freedom in configuring the system also introduces extra complexity. We have found in our investigation of the project, that scikit-learn has found some clever ways to optimize this balance.
First, let us investigate what kind of configurability is desired by the relevant stakeholders. Here, we consider a configuration of scikit-learn to be an ML pipeline that uses scikit-learn to solve an ML problem.
The need for Configurability
As we described in our first essay 1, scikit-learn is designed to be simple, efficient, reusable and maybe most importantly, accessible to non-experts. So let’s find out how these design goals translate to variability requirements.
In our first essay 1 we defined four groups of stakeholders: competitors, funders, users and contributors. Each of these stakeholder groups have varying desires of configurability. Due to the lack of involvement in the project, we will leave the group of competitors out of scope for our analysis now. We will, however, describe the configurability needs of the other three groups of stakeholders. The developers of scikit-learn need to take this into account during system design.
Funders want the configuration abilities that suit their (business) needs. In scikit-learn’s case, the funders are both educational institutions (universities) and businesses. Universities may want the product to be highly configurable for research purposes but also accessible for non-experts (students). Business may want the product to be configurable for their business needs to deploy it in their service line.
Scikit-learns user base is broad: the website 4 lists several notable businesses, but it is also the go-to library for anyone who wants to play around with machine learning. Therefore, configuration needs to be open to a very wide user base.
Contributors are concerned with the implementation of the application in various forms. Therefore, they seek to have a very smooth development process.
Contributors thus desire that configurability does not add additional complexity to the development process, but still meets all requirements. In the next section, we will see how this balance is managed by scikit-learn.
Maximizing configurability and usability
In machine learning, your chosen implementation and hyper-parameter configurations have a significant impact on both the accuracy and the performance of your model.
Which means that there is a huge need for configurability.
However, if configurability is implemented incorrectly your product will be hard to understand and use.
So there must be a natural balance between configurability and usability.
This balance is implemented directly into scikit-learn’s estimator design.
Every estimators fit method is highly configurable.
In this section, we will first discuss how configurability works from a users perspective.
Then we will discuss how this balance has been implemented.
Finally, we discuss the trade-offs that had to be made.
User perspective
From a users perspective, configuration happens in the following way. First, the user selects the model he wants to configure. Then the user looks at the API documentation on scikit-learn’s website. As can be seen in figure 15, this documentation provides a clear overview of the configuration options and their effects.

Figure: 1: A small part of the configuration documentation for an MLPClassifier.
The user then constructs the selected model and provides the configuration through the parameters.
All the missing parameters will keep their default configuration.
The configuration will only be validated once the user calls the fit method.
This method will raise a ValueError if the validation is invalid.
If the configuration is valid the fit method will act as described in the configuration.
The configuration is only considered frozen during the execution of the fit method.
The user is free to change the configuration dynamically using the set_param method at any time.
So from a users perspective, the binding flow is rather easy and well documented.
However, from a configurability perspective, the configuration is limited to a fixed set of options.
Implementation
The constructor and the set_param method only store the configuration.
They don’t validate them.
While the fit method both validates and executes the configuration.
Which means that this method can quickly become rather complex.
However, scikit-learn does it best to hide this complexity from the user using a Façade design pattern 6.
All this complexity is also hard for the developers to keep in mind.
That is why they divided this large function into 3 major parts.
First, the fit method will always call the _validate_hyperparameters method.
This method will raise a ValueError if any of the parameters don’t adhere to the value constraints as stated in the documentation (figure 2 7).
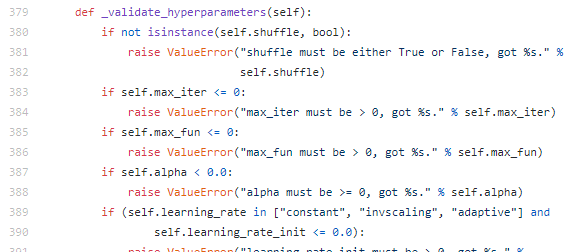
Figure: 2: An example of how a _validate_hyperparameters method in an MLP
Secondly, after validating the parameters, the fit method will update the parameters that are incompatible with each other to values that are.
Automatically correcting the incompatible configurations.
This code can usually be found in the main body of the fit method.
For example figure 37 shows how the batch_size configuration parameter is updated based on the solver type.

Figure: 3: An example of how incompatible parameters are handled in an MLP
Finally, the configured method is implemented as a separate method.
This method will be called at the very end of the fit method with the configured parameters.
For example, figure 4 8 show the configured method for the MLP is finally called, whereby the implementation truly depends on the configuration.
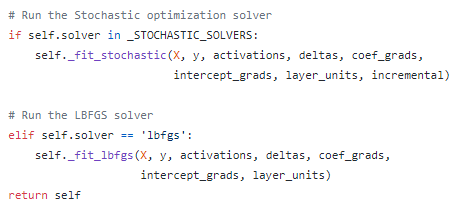
Figure: 4: An example of how the configured fit method is called in an MLP
Trade-offs
Based on the previous section, it is obvious that scikit-learn has chosen to increase configurability and usability at the expense of development complexity. This also becomes clear when we want to add a new configuration parameter to an estimator. This requires a rigorous amount of testing due to all the branches and edge cases it introduces. Secondly, usability is still a bit more important than configurability. This is why users are not able to extend the configuration with their own code, as is possible in some other frameworks.
Configurability in scikit-learn’s features
Now we know why it is important for scikit-learn to be configurable and how scikit-learn balances its configurability with usability, how can these aspects be found in the architecture of scikit-learn? To answer this question we will look into the different functionalities provided by scikit-learn and how they compliment each other, then we will go more in depth into one feature and see how configurability is handled on a lower level. In both cases we will model the configurability with the help of a feature diagram.
scikit-learn’s feature sets
To model the features of scikit-learn we first need to look back at the functionality that scikit-learn offers. We have of course discussed this in our previous essays, but we will summarize the most important functionalities which are relevant to create our feature diagram.
Estimation
Most of scikit-learn’s functionality is based around estimation. “An estimator is any object that learns from data; it may be a classification, regression or clustering algorithm or a transformer that extracts/filters useful features from raw data.”9.
Model Evaluation
After estimation comes evaluation in which the performance of a model is measured. The main components of model evaluation are the different metrics offered by scikit-learn. These metrics can be used on separate predicted/actual value pairs or in combination with a scorer which uses the given metric to train a model10.
Inspection
Summarising module performance using metrics is, however, often not enough as then the assumption is made that the metric and test dataset perfectly reflect the target domain, which is often not true. Scikit-learn, therefore, offers a module which offers tools for model inspection such as partial dependence plots and the permutation feature importance technique11. Scikit-learn also offers an API for creating quick visualisations without recalculation12.
Datasets
Then, when users want to test their models, scikit-learn offers a datasets module. This module contains a dataset loader, which can be used to load small toy datasets and a dataset fetcher which can fetch larger datasets which contain ‘real-world’ data commonly used by the machine learning community to benchmark algorithms13.
Feature diagram
Figure 5 views the most general features, but to get a sense of the amount of variability within scikit-learn we need to go deeper. When picking scikit-learn as a machine learning library the most important variabilities are within the different estimators that are available, therefore, we will go more in depth into how that can be seen in the scikit-learn architecture in the next section.
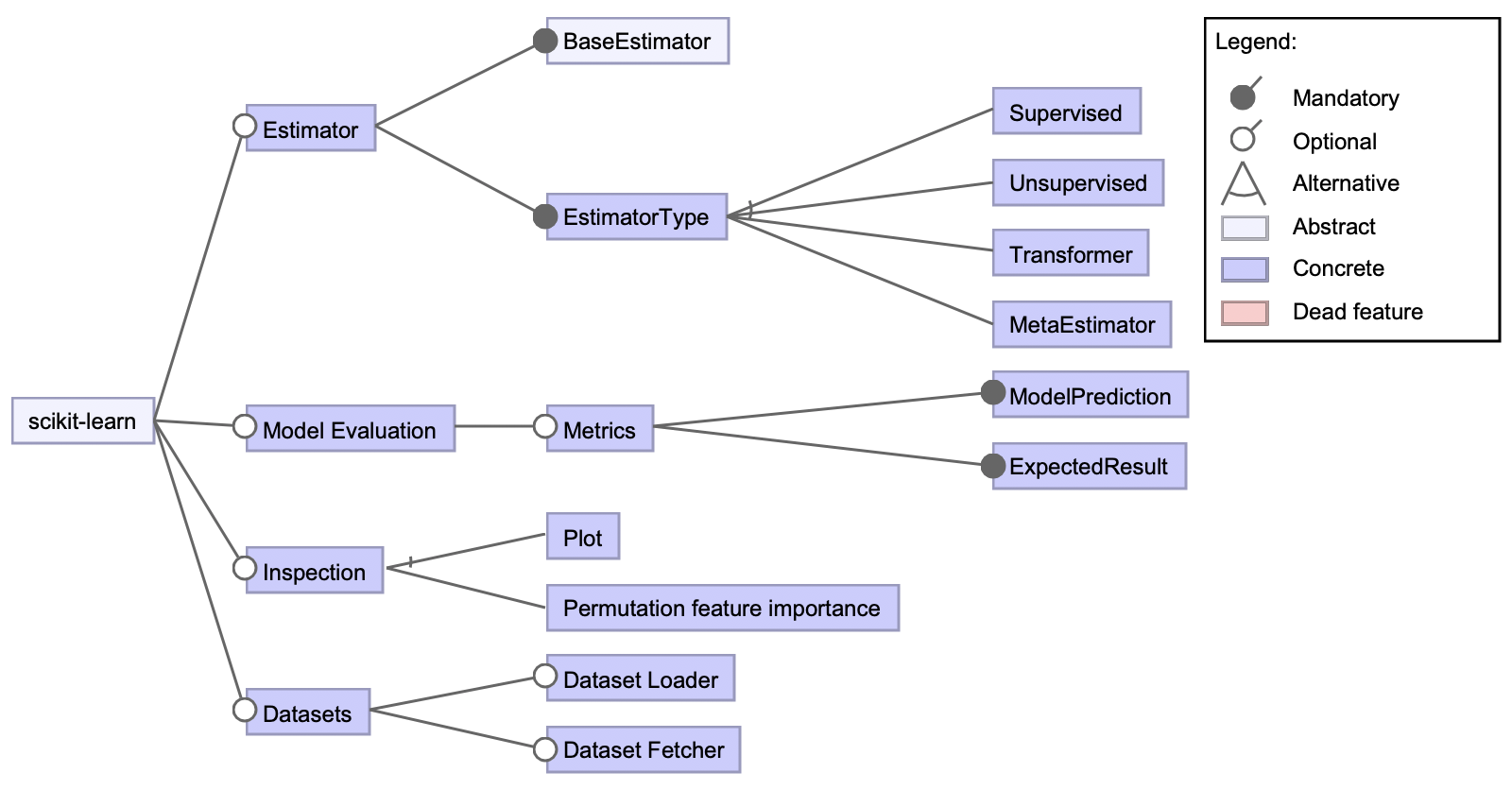
Figure: 5: A feature diagram viewing the most general features of scikit-learn.
We need to go deeper
In order to demonstrate the variability with estimators we will give two examples. For the first example, we will take a look at the linear models. Scikit-learn has divided the linear models into 7 categories. Each category contains several linear models that are implemented in scikit-learn as an estimator. And each estimator can have a lot of parameters that can be configured. In figure 6 the feature model is given for linear models with most categories and models collapsed for a more clear overview.
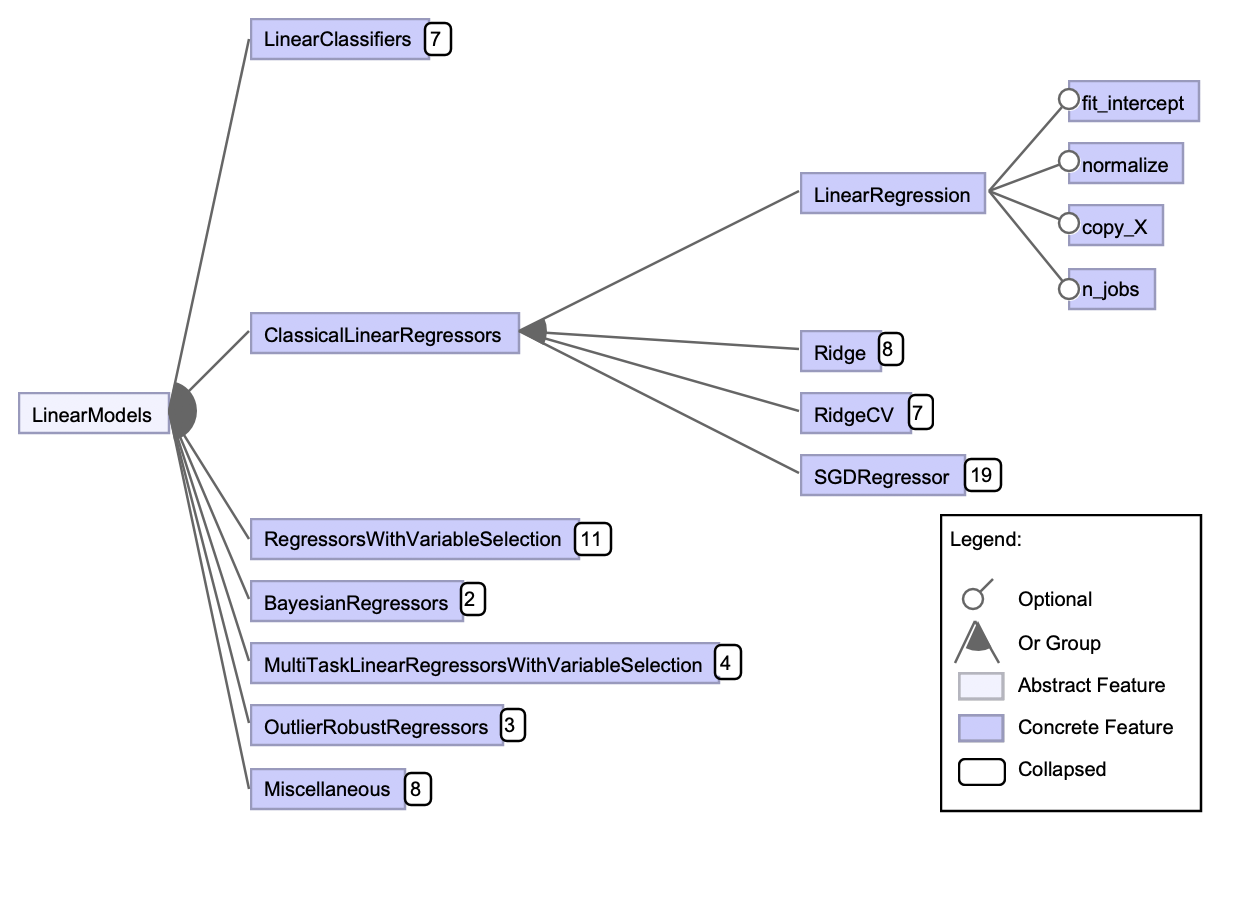
Figure: 6: Feature model of linear models in scikit-learn.
Most of the parameters in the estimators share their names and functionality. A list of the most common parameters can be found in the scikit-learn’s glossary14. We can see that the model LinearRegression only has 4 parameters, fit_intercept, normalize, copy_X and n_jobs. Parameters can be any data type and are all optional because they contain a default value. This estimator does not have a lot of parameters compared to the 19 parameters of SGDRegressor. This gives already a lot of options for Classical Linear Regressors because there is a choice of model and a lot of parameters per model. The other six categories also contain a lot of models, for example, there are 11 estimators in Regressors with Variable Selection with each estimator having its own parameters which can be configured. This gives scikit-learn already a lot of configurability for linear models.
If we then look at the LinearClassifiers we find the SGDClassifier, the Perceptron and the PassiveAggressiveClassifier which are three variants of models using the Stochastic Gradient Descent algorithm.
These are all variants of the SGDBaseClassifier.
This relation is modelled in Figure 7.
The BaseSGDClassifier contains the option for 9 different loss functions, however, when choosing the Perceptron variant of the BaseSGDClassifier the perceptron loss is the only loss applicable.
Also, the learning rate parameter of the BaseSGDClassifier has four values: ‘constant’, ‘optimal’ , ‘invscaling’ and ‘adaptive’.
For the SGDClassifier and PassiveAggressiveClassifier, all options are open, but for the Perceptron the ‘constant’ value is set.
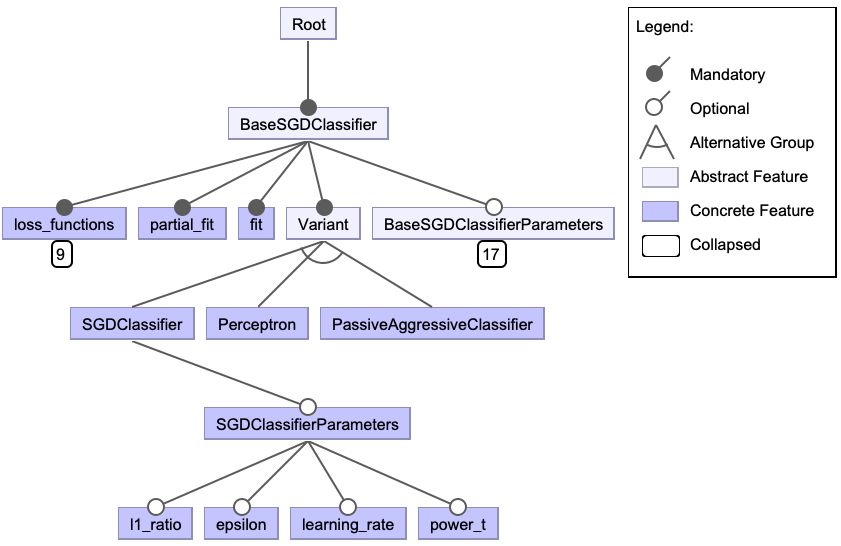
Figure: 7: Feature model of the SGD variants.
Also, the learning rate parameter of the BaseSGDClassifier has four values: ‘constant’, ‘optimal’ , ‘invscaling’ and ‘adaptive’.
Conclusion
In this essay we have taken a look at scikit-learn from a variability perspective. That is, in what ways can scikit-learn be configured for varying requirements? We have seen that scikit-learn offers a lot of configuration options for its users and that it tries to balance configurability and usability. While scikit-learn focuses more on the usability at the expense of complexity and configurability, it offers an enormous amount of variability in the estimators. The reason for this is to make scikit-learn easily accessible for non-experts, which is one of the core design goals of the project. Overall, we conclude that scikit-learn has been succesful in offering variability for its users while not sacrificing usability.
-
Scikit-learn, what does it want to be?, T. de Boer, T. Bos, J. Smit and D. van Gelder, https://desosa2020.netlify.com/projects/scikit-learn/2020/03/06/ scikit-learn-what-does-it-want-to-be.html ↩ ↩2 ↩3
-
From Vision to Architecture, T. de Boer, T. Bos, J. Smit and D. van Gelder, https://desosa2020.netlify.com/projects/scikit-learn/2020/03/15/ from-vision-to-architecture-20893.html ↩
-
Scikit-learn’s plan to safeguard its quality, T. de Boer, T. Bos, J. Smit and D. van Gelder, https://desosa2020.netlify.com/projects/scikit-learn/2020/03/26/scikit-learns-plans-to-safeguard-its-quality-31705.html ↩
-
Scikit-learn’s users/testimonials, https://scikit-learn.org/stable/testimonials/testimonials.html ↩
-
Documentation from the
MLPClassifier, https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html#sklearn-neural-network-mlpclassifier ↩ -
Façade design pattern, https://en.wikipedia.org/wiki/Facade_pattern ↩
-
The source code in the example of how imcompatbile parameters are handled, https://github.com/scikit-learn/scikit-learn/blob/eaf0a044fdc084ebeeb9bbfbcf42e6df2b1491bb/sklearn/neural_network/_multilayer_perceptron.py#L347 ↩ ↩2
-
The source code in the example of how the final configured method is called, https://github.com/scikit-learn/scikit-learn/blob/eaf0a044fdc084ebeeb9bbfbcf42e6df2b1491bb/sklearn/neural_network/_multilayer_perceptron.py#L369 ↩
-
Statistical learning: the setting and the estimator object in scikit-learn, https://scikit-learn.org/stable/tutorial/statistical_inference/settings.html ↩
-
Metrics and scoring: quantifying the quality of predictions, https://scikit-learn.org/stable/modules/model_evaluation.html ↩
-
Inspection, https://scikit-learn.org/stable/inspection.html ↩
-
Visualization, https://scikit-learn.org/stable/visualizations.html ↩
-
Dataset loading utilities, https://scikit-learn.org/stable/datasets/index.html ↩
-
Scikit-learn’s glossary of the parameters, https://scikit-learn.org/stable/glossary.html#parameters ↩