In the last essay we gave an overview of Sentry and its context. We discussed topics like Sentry’s key capabilities, stakeholders and relationships with its environment. But that essay also serves as a stepping stone to the topic of this essay: the architecture behind Sentry. Architecture of software can be viewed from multiple perspectives, as has for example been described by Rozanski and Woods1. Guess what? The last essay already covered two architectural viewpoints, namely the contextual and functional viewpoints! In this essay, we will take a Snuba dive into some more technical architectural viewpoints: development, deployment and runtime.
These different viewpoints by Rozanski and Woods have been listed in the table below along with some explanation and prioritization1. Like we mentioned, this essay will cover two important new viewpoints from this table: the development and deployment views. This essay also adds a third viewpoint, the runtime view, which has been inspired by the arc42 architecture documentation template2. Whereas the development view discusses what software components Sentry is built from, the runtime view will discuss how these components interact in practice. Then, the deployment view will highlight how this software is being deployed as a system.
| Viewpoint | Importance | Explanation |
|---|---|---|
| Context | medium | The context of Sentry has already been analyzed in our product vision. Here we explained the relationship between Sentry and its environment using context diagrams and a description of the end-user mental model. |
| Functional | high | This is an important viewpoint as it provides a general description of how the core functionality of Sentry is coupled in its architecture without going into too much detail. |
| Information | medium | The system does save monitoring data for its history feature. However, saving static data and guaranteeing information quality and consistency are not of high priority in Sentry’s functionality. |
| Concurrency | medium | This viewpoint is not highly important since the system does not need to be optimized in performance and scalability using threads or distributed systems. |
| Development | high | It is an open-source system so the software architecture needs to be understandable for outsiders. They implemented many unit and end-to-end tests so that other people can easily contribute as well without breaking the product. |
| Deployment | high | It needs to be easy to integrate Sentry into the many different development environments of the customers. |
| Operational | medium | This viewpoint depends on the version of Sentry. For the on-premise edition, the customer is responsible for the operationality. For the SaaS edition, both the Sentry team and the customer are responsible for operating the Sentry system. |
The main architectural style
Due to the scale of Sentry we can find several patterns throughout the code. We will focus on the main patterns that are encouraged by the frameworks used. As discussed in our first essay Sentry has been built up from two parts: a front-end (written in JavaScript, uses React) and back-end application (written in Python, uses Django). The front-end is served to the client through the back-end. Together they are bundled in to a single docker image for deployment.
In general this means that due to the separation of data presentation in the front-end and the data storage and logic in the back-end one could argue that from this high level application overview a generic model-view controller has been applied with the front-end as view and the back-end as model. However digging deeper both the front-end and back-end in itself provide similar abstractions.
The back-end of Sentry is written using the Django web framework. This framework follows an MTV (model, template, view) architecture as for every response one defines the template (how the data is shown), the view (which data is shown) and the model (the application logic)3.
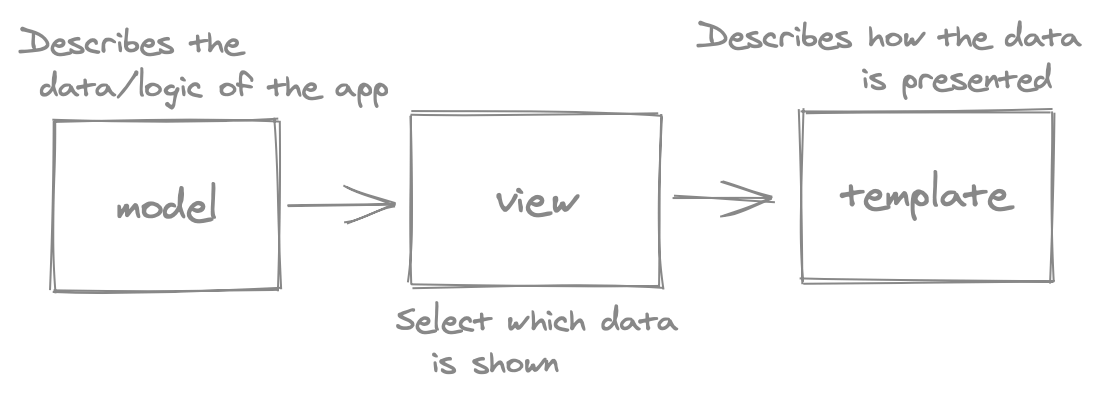
Figure: Model Template View Architecture, visual representation.
This is closely related to the MVC model. This MTV model is followed closely for the authentication part of Sentry, which is the part that is directly served by the back-end (likely for security reasons). The rest of the front-end (once logged in) is rendered by a React application.
The front-end is built with React and makes use of the flux/store pattern to control the data flow and manage state throughout the application.
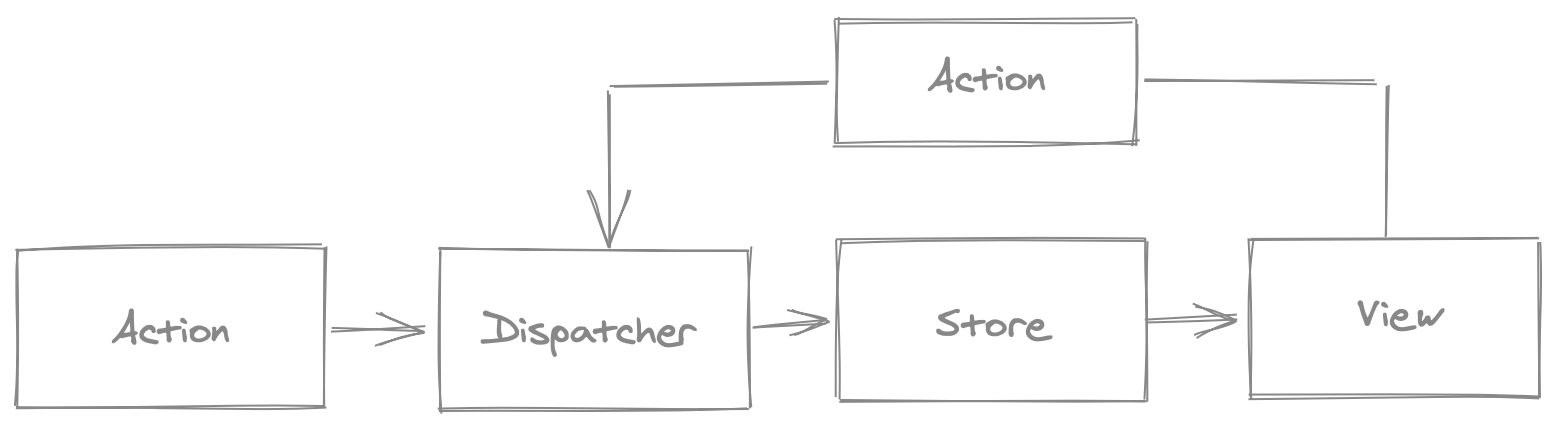
Figure: Flux Pattern Action->Dispatch->Store->View.
This pattern provides a clear definition on how state is stored. As shown in the diagram above it allows updates to the state using predefined actions and then updates this state across all components that are subscribed it, therefore updating the view. In the view new actions can be triggered by user behavior.
The Sentry front-end application uses these stores to manage different parts of the application like global configuration to projects.
Decomposing Sentry
Sentry is a very large system. According to Sigrid, a static code analysis tool by SIG, the Sentry codebase contains around 25 man-years worth of code. Furthermore, we have used SonarQube for analysis, which reported about 437k lines of code. Due to this size, it is hard to gain an immediate understanding of how Sentry works as a system. In order to get more insight into how components interact in a large system like Sentry, we will need to decompose its structure. Since we have already discussed the System Context of Sentry in the last essay, we will start with decomposing the system according to Level 2 of the C4 Model for visualizing software architecture4. The result of this can be seen in the figure below.
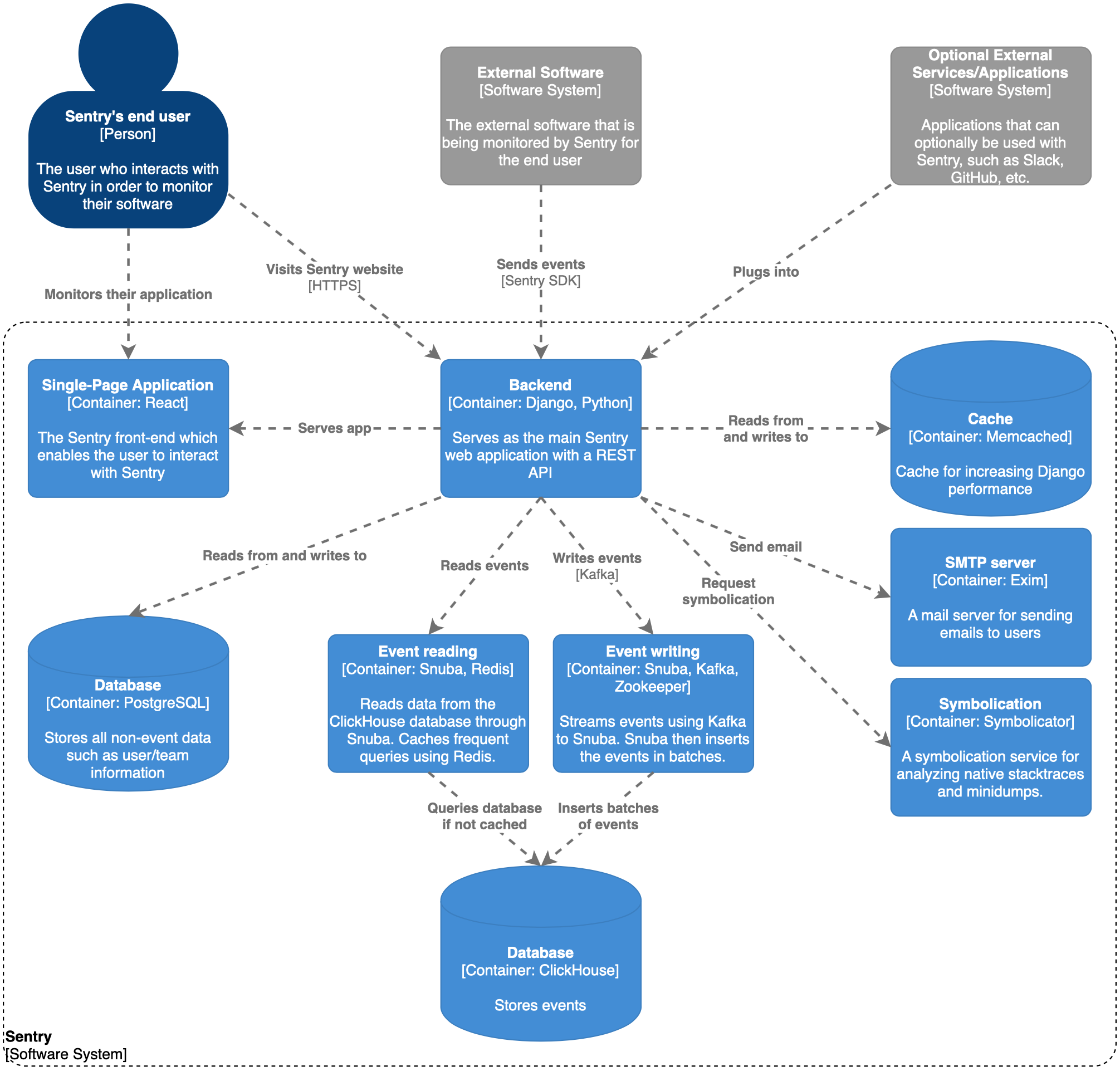
Figure: C4 Model for Sentry, Level 2 decomposition
Although this diagram contains some explanation, we will clarify a few details. The Django and Python back-end is the most important component in the system. Not only does it serve the React front-end to the user, it also receives and processes events from the Sentry SDK in the software it monitors and stores it for later use. The events are stored in a ClickHouse column-oriented database. For reading and writing to this database, the makers of Sentry made a tool that acts as an abstraction layer for ClickHouse called Snuba in order to hide underlying complexity5. Snuba works together with Kafka (which in turn depends on Zookeeper) in order to stream any new events and insert them in batches in the database. Besides also using Snuba for querying, Sentry uses a Redis instance for caching query results in order to remove some load from the ClickHouse cluster. The Sentry back-end uses a PostgreSQL database for storing ‘regular’ non-event data and it uses Memcached which enables Django to cache expensive calculations. Sentry has also built their own Symbolication service called Symbolicator, which analyzes native stacktraces and minidumps6. Furthermore, the back-end can use Exim for sending emails and lastly, Sentry supports various integrations and plugins (which are modeled as an external component) such as Slack for notifications or GitHub for linking events to commits and issues78.
In order to understand the source code structure, from the Level 2 diagram we can now derive a Level 3 diagram, by decomposing the back-end container4. The result of this can be seen in the figure below.
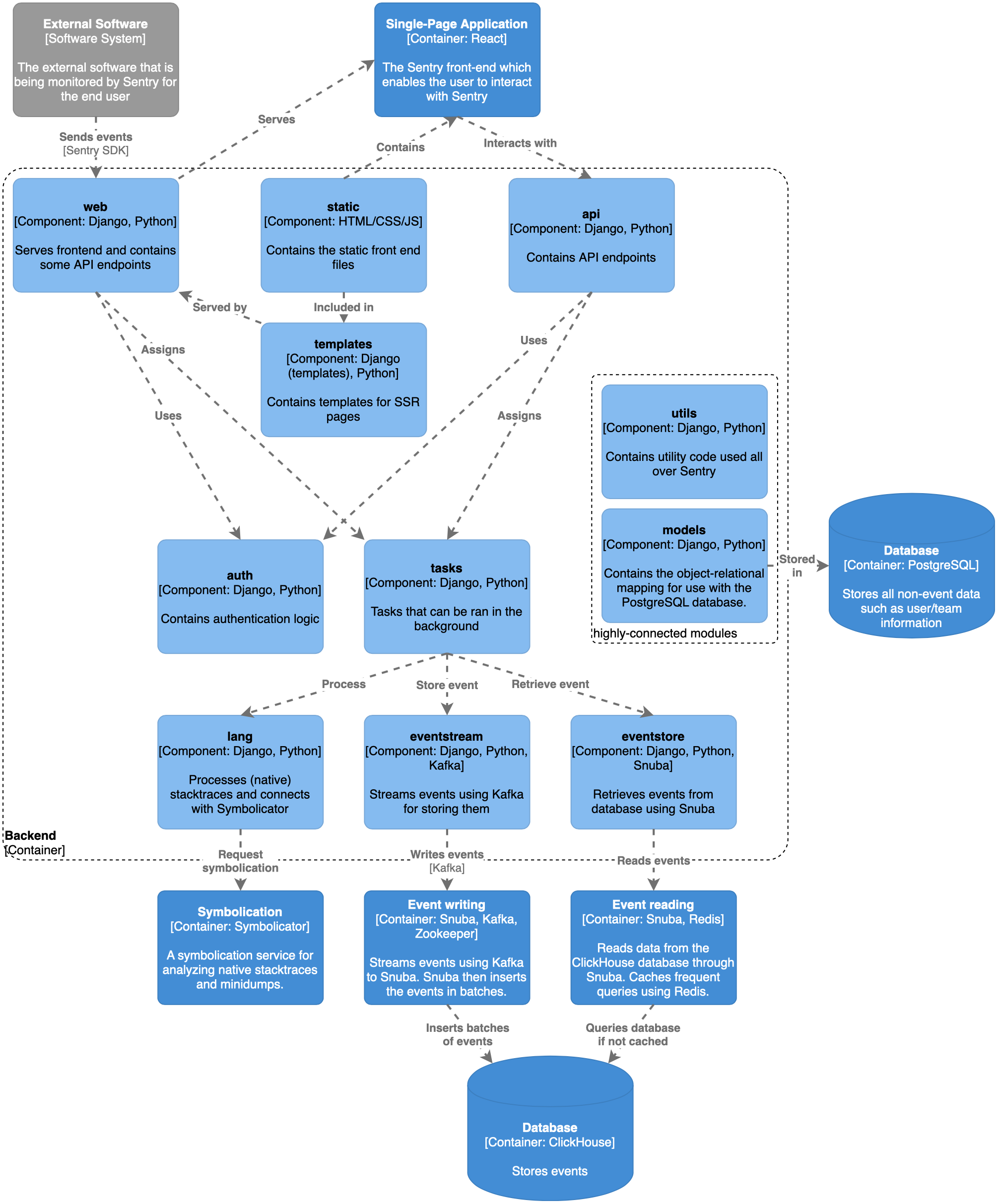
Figure: C4 Model for Sentry, Level 3 decomposition of back-end (simplified)
Due to Sentry’s size, Sentry has a lot of interconnected modules.
For the sake of simplicity and readability, we have left out a number of modules that in our opinion are less important to the overall representation of the source code structure.
This includes various smaller modules, as well as modules that contain setup and configuration code, and plugins and database migrations.
As can be seen, the whole React front-end is contained in the static module of which the files are included in server-side rendered templates in the templates module, which are in turn served by code in the web module.
The two modules that have API endpoints also make use of the auth module for authentication.
The web module has API endpoints for pushing events to Sentry, which in turn spawns tasks for processing them using the tasks module.
This module contains tasks that can be used to write and query events, but also for example for requesting symbolication.
Lastly, the model also shows some separate modules listed as highly-connected modules, utils and models, which are connected with most if not all of the modules in the diagram and thus shown without any arrows for clarity.
The complexity of Sentry really shows in the dependency graph generated by Sigrid, even when only selecting the modules used in the figure above. Sigrid clearly does not even recognize all of the dependencies and connections between modules. That is why we made the simplified version. The dependency graph generated by Sigrid (only with the modules used in the figure above) can be seen below.
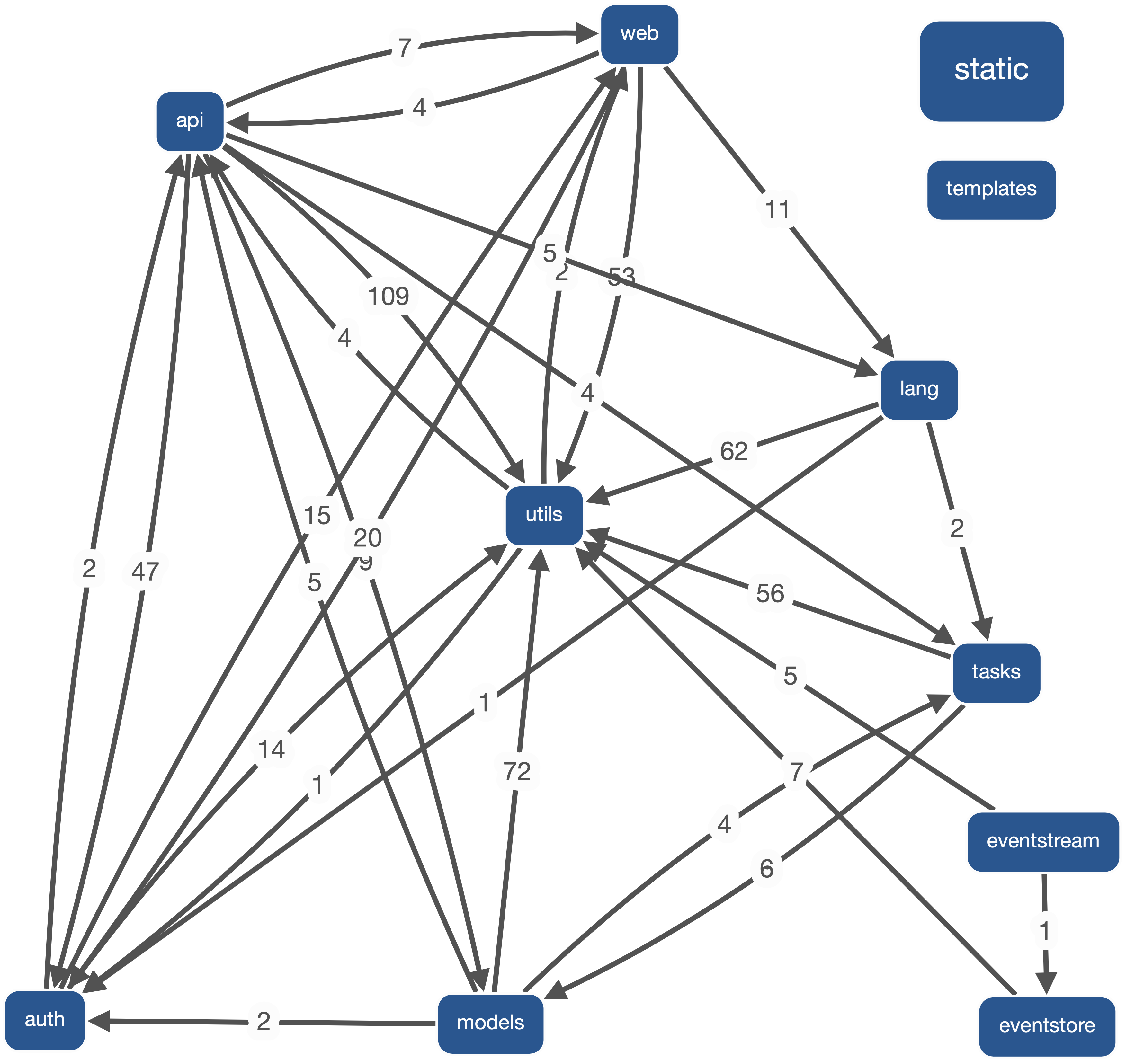
Figure: Dependency graph for Sentry generated by Sigrid (with only modules selected from figure above)
A run time view
A basic understanding of the run time view can be derived from the C4 figures above, as key interactions between the components are already shown in these diagrams. To further highlight how these components interact, we will analyze how one of the most important processes of Sentry is realized at runtime.
Event processing and storage
The main feature of Sentry is the capturing, processing and storage of error events. In the figure below, the flow for this scenario is illustrated. This figure is simplified, since there are many more interactions between more modules than shown here.
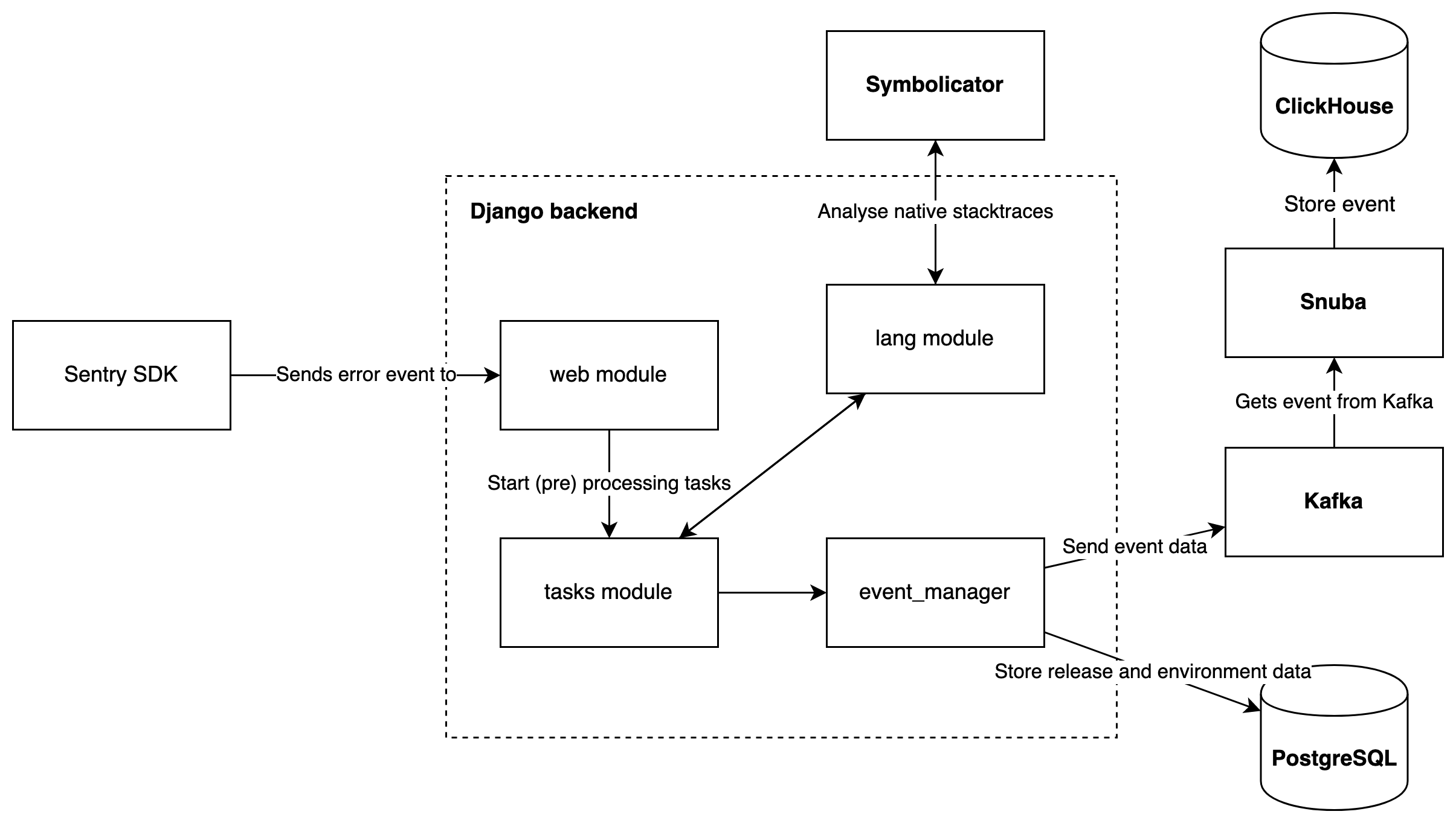
Figure: Event processing at runtime
In the monitored application, the error event is captured by the Sentry SDK and sent to the back-end using the /api/{project_id}/store endpoint which is handled by the web module.
From this endpoint tasks are started in the tasks module that process the event.
One of these processing steps is analyzing the native stacktraces in the error event, which is done through the lang module by Symbolicator, an external service which is also developed by Sentry.
After processing, the events are stored through the event_manager.
Release and environment data linked to the event are stored in the PostgreSQL database, and the event itself is sent to the Kafka stream as a job.
This event is picked up by Snuba and stored into the ClickHouse database.
A deployment view
Sentry is being deployed in three ways: on-premise, SaaS and front-end preview. The on-premise version is orchestrated by Docker Compose and is available on Sentry’s onpremise repository. This starts containers for Sentry itself and all the services that Sentry relies on9. These services can be seen in the Level 2 decomposition above, and include:
- PostgreSQL
- Redis
- Memcached
- ClickHouse
- Snuba
- Symbolicator
- Kafka
- Zookeeper
- Exim
Deployment of Sentry itself is continuously done by a CI/CD pipeline task on the master branch, which builds and pushes an image of Sentry to Docker Hub. This image is then used in the on-premise setup.
Sentry also provides a paid SaaS version, but the deployment details for this version are not publicly visible. Lastly, the Sentry front-end is deployed to ZEIT Now for previewing purposes only (i.e. for pull requests).
Non-functional properties
-
Security: is one of the important nonfunctional aspects of Sentry as it is monitoring the errors and sometimes events made by the tools of the customer. These can include private tools (which deal with private information) or public tools which deal with customer data. Making sure the communication between these SDKs and Sentry itself is secure is therefore important. They use different industry-standard technologies and services to secure their customers’ data and provide mechanisms to filter out sensitive data in the SDKs10. As Sentry itself is open-source, it could be more vulnerable to attackers since adversaries can analyse the source code directly in order to find exploits. Hence, they urge developers to disclose vulnerabilities to the Sentry team directly11.
-
Own tools vs Existing tools: The Sentry team has opted to develop their own tools for event processing (Snuba) and a stack tracer parser (Symbolicator). For many years Sentry used existing tools to handle the storage of events using Search, Tagstore and TSDB5. However, as explained on their blog post from March 2019, this infrastructure was causing problems in scaling as well as for development5. This lead to an eventual choice to develop their own event storage solution based on the columnar store Scuba by Facebook (which is closed source). Initially, they used KSCrash for iOS platforms and Google Breakpad other platforms to catch crashes and compute stack traces. However, these tools were not targeted to support automated crash processing. Therefore, Sentry decided to create a standalone native symbolication service, Symbolicator6.
-
Rozanski, N., & Woods, E. (2012). Software systems architecture: working with stakeholders using viewpoints and perspectives. Addison-Wesley. ↩ ↩2
-
Starke, G. (n.d.). arc42 Documentation. Retrieved March 18, 2020, from https://docs.arc42.org/home/. ↩
-
Brown, S. (n.d.). The C4 model for visualising software architecture. Retrieved March 14, 2020, from https://c4model.com/ ↩ ↩2
-
Sentry. (2019, May 16). Introducing Snuba: Sentry’s New Search Infrastructure. Retrieved March 14, 2020, from https://blog.sentry.io/2019/05/16/introducing-snuba-sentrys-new-search-infrastructure/ ↩ ↩2 ↩3
-
Sentry. (2019, June 13). Building Sentry: Symbolicator. Retrieved March 14, 2020, from https://blog.sentry.io/2019/06/13/building-a-sentry-symbolicator ↩ ↩2
-
Sentry. (n.d.) Slack + Sentry Integration. Retrieved March 15, 2020, from https://sentry.io/integrations/slack/ ↩
-
Sentry. (n.d.) GitHub + Sentry Integration. Retrieved March 15, 2020, from https://sentry.io/integrations/github/ ↩
-
Sentry. (n.d.). Self-Hosted Installation. Retrieved March 15, 2020, from https://docs.sentry.io/server/installation/ ↩
-
Sentry. (n.d.). Security & Compliance. Retrieved March 18, 2020, from https://sentry.io/security/#data-into-system ↩
-
Sentry. (2018, August 15). Sentry Scouts: Security - A Recap. Retrieved March 18, 2020, from https://blog.sentry.io/2018/08/15/sentry-scouts-security-recap ↩