Thousands of customers use Sentry for creating better software, but how is the software quality of Sentry itself? In this essay, we will analyze how the quality of Sentry’s underlying code and architecture is safeguarded. The architecture powering Sentry has already been discussed in the last essay (“The Architecture Powering Sentry”), so we recommend you to read that first. Having an understanding of Sentry’s core software architecture, we can take a look at the architecture from yet another perspective by addressing topics like software quality assessment, code quality, and technical debt. This perspective is inspired by the Quality Scenarios and Risks & Technical Debt aspects from the arc42 framework1.
Sentry’s Software Quality Process
We will start this analysis by discussing the overall software quality process that the Sentry project uses. Sentry does not have a lot of explicit documentation on its overall quality assessment process. Hence, Sentry’s overall software quality process and the importance of it will be discussed in three parts by looking at Continuous Integration pipelines, automated checks, and GitHub usage.
Continuous Integration
Both Continuous Integration (CI) and Continuous Deployment (CD) are used in their development process2. They use short release cycles to maintain high code and product quality, to make sure that release issues are resolved quickly and to be able to resolve customer complaints faster3. Whenever a pull request is made, the following checks and pipelines are being run2 3 4:
| Check | Description |
|---|---|
| Travis CI | Travis runs jobs for various tasks such as linting and various test suites for the frontend, backend, integrations, etcetera. They also test parts of their code against Python 3 in order to proactively support the porting process since Sentry still uses Python 2.7. The complete list of jobs can be seen in the screenshot below. |
| Percy | Visual changes in the UI are automatically monitored using Percy, which are then put up for review. |
| Codecov | The Travis CI pipeline sends test coverage reports to Codecov, which visualizes and reports the code coverage of the system and whether it has been negatively affected. |
| Snyk | Sentry uses Snyk to detect vulnerabilities in packages that they are using and to check for license issues. |
| ZEIT Now | ZEIT Now is being used to deploy a preview version of the front end for a pull request. |
| Google Cloud Build | Cloud Build is used to run the complete Sentry system using the on-premise repository and to perform some smoke tests. Then, for commits on master, it pushes a new Sentry Docker image to Docker Hub as a release. |
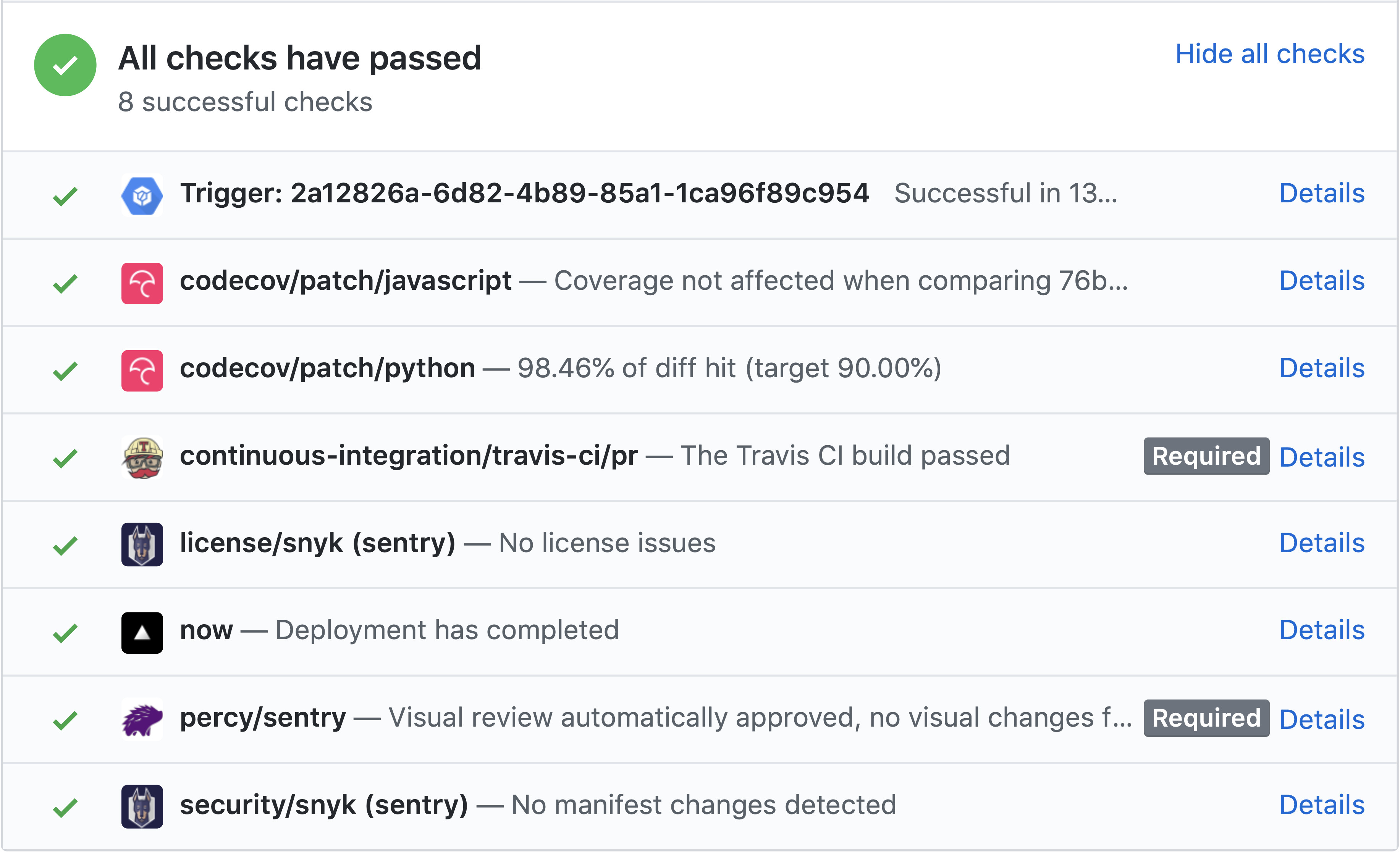
Figure: Checks on a GitHub Pull Request
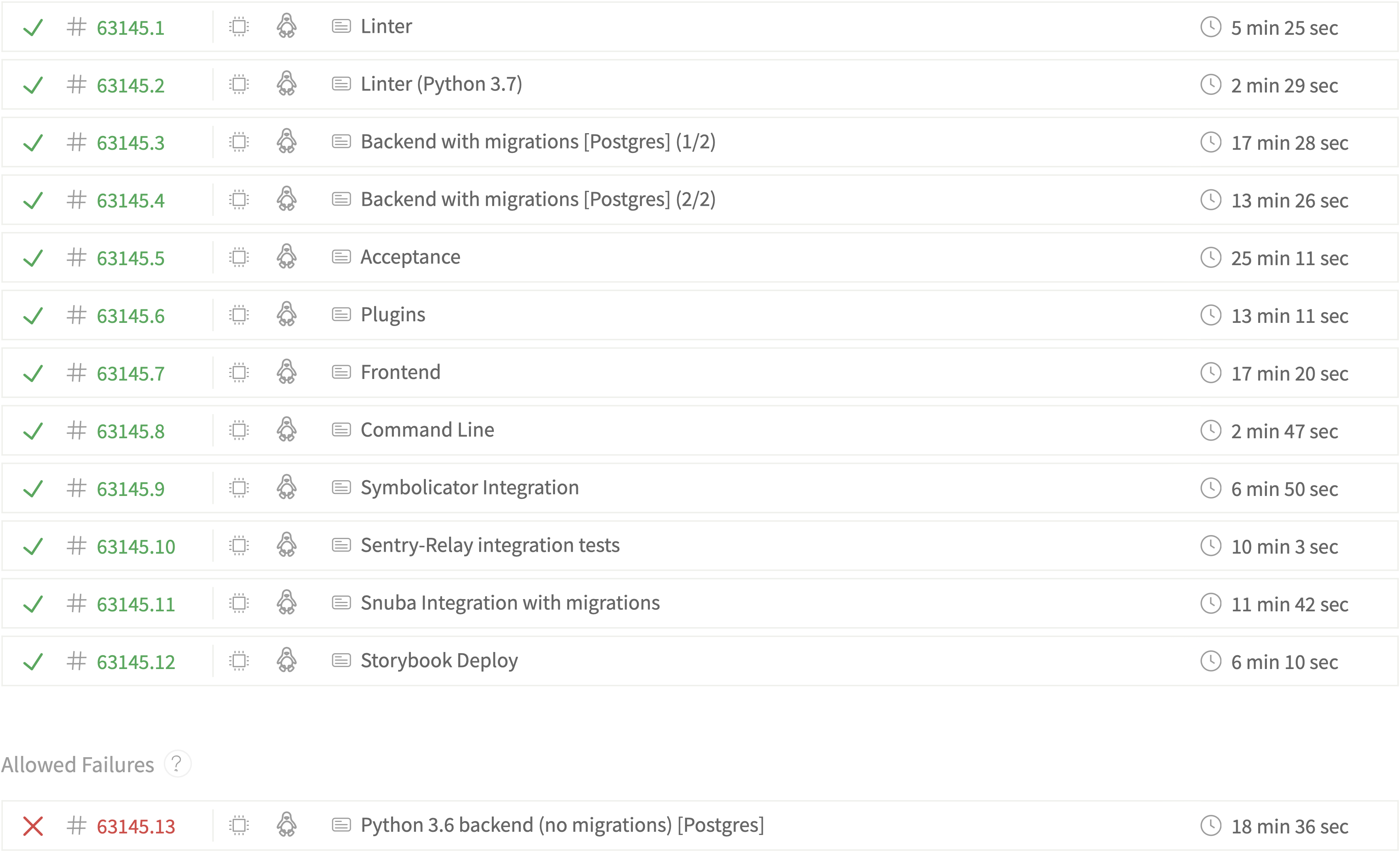
Figure: Screenshot from Travis showing a variety of jobs and configurations on master
Automated Testing
We found by analyzing the codebase that Sentry has a broad range of tests, including unit tests, regression tests, integration tests, and acceptance tests. They emphasize in their blogs on the importance of automated regression testing not to verify whether the current code works, but to prevent that future changes to the code might result in issues4. They use tools like Jest for JavaScript, pytest for Python, Selenium WebDriver for acceptance testing and the mock library to create mock objects in Python tests. Even though there are quite a lot of tests, they do not seem to have any rules for (external) contributors regarding tests, e.g. every new feature should be tested. Later in this essay, we will discuss some coverage results reported by Codecov.
Other automated measures
Another important measure that Sentry has taken is implementing linters and formatters to create clean, readable and consistent code4. This helps with writing code with fewer errors, and also allows reviewers to find real issues instead of getting distracted by style issues. Linters include ESLint and flake8 and formatters include prettier and autopep8.
Another very valuable tool for Sentry is… Sentry! Since they continuously deploy and ship new versions of their software, there is a risk that something might go wrong. Sentry allows them to quickly find and resolve these issues and then deploy within a very short time.
GitHub usage
Sentry considers code review to be very important, and they have strict commit guidelines5.
We analyzed a (relatively small) sample of pull requests and issues, either by randomly picking or by strategically searching using GitHub’s querying system, such as: is:pr is:closed complexity in:comments.
It can be seen that indeed code review is taken pretty seriously by the core Sentry team.
Comments vary from warning about specific issues to nitpicks to comments about writing better tests.

Figure: Comment on GitHub reviewing added tests
However, when taking another look at the automated checks for pull requests, it can be seen that only the Travis CI and Percy checks are required to pass.
This could indicate that they do not consider things like test coverage so important to block a pull request by default.
Moreover, we have not noticed any discussion about failing Codecov checks and PRs have been merged regardless of the Codecov status.
Also, few discussions could be found about code quality metrics like complexity, module coupling or unit size and Sentry does not make use of any code quality tools like SonarQube.
Lastly, they also do not have a clear reviewing strategy (e.g. by using a CODEOWNERS file).
Investigating Hotspots
In order to find parts of the codebase that are particularly interesting to analyze, we will try to find parts of the Sentry codebase that are worked on a lot. Using a simple self-written tool we were able to analyze the commits between two given dates. This tool finds the min/avg/max amount of commits for a folder by aggregating the number of commits that ‘touch’ files within that folder (for the average only the changed files are taken into account). The code for this script can be found here and the full results here.
We ran two experiments, one to act as a baseline for our method and the second to find the current hotspots:
- Between release
v9andv10(Jun 25, 2018 until Jan 7, 2020) as a baseline (results & conclusions), and - Since the latest release
v10.0.0(Jan 7, 2020 until Mar 23, 2020).
The baseline experiment is seen as out of scope for this essay but can be found here.
The second experiment focuses on the parts of essay that are currently being worked on, we find the following hotspots since the latest release (v10):
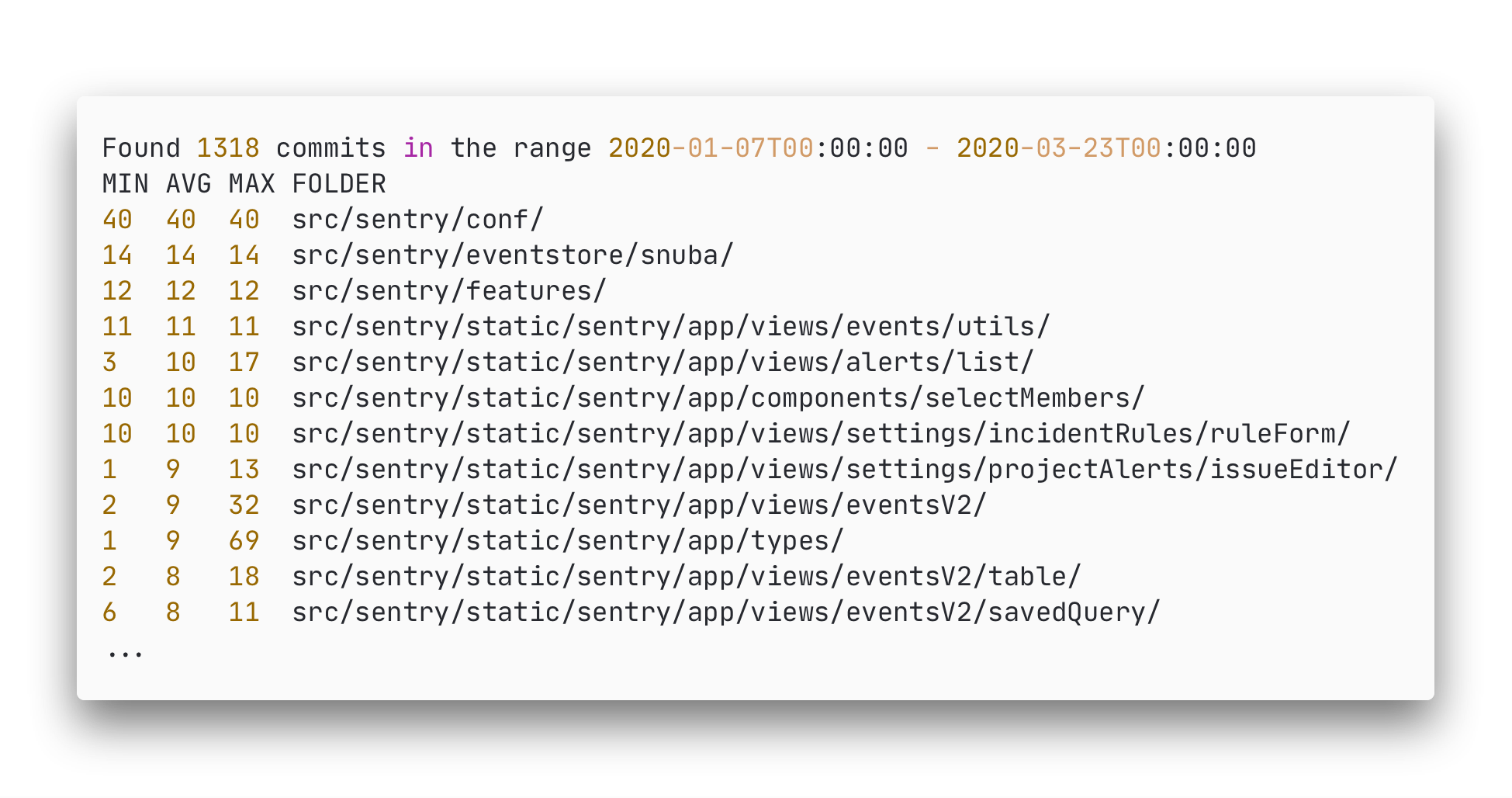
Figure: Results Analysis Sentry v10
We find that compared with our baseline, even after v10 Snuba is still a hotspot, next we see a huge focus on the src/sentry/static/sentry/app/ folder which is where the code for the frontend of Sentry is located. This seems to be one of the hotspots for the last two months since the release of v10, specifically the types and views seem to touch the most.
This would provide three major hotspots:
src/sentry/static/sentry/app/views– Frontend Viewssrc/sentry/static/sentry/app/types– Frontend Types (related to all aspects of the frontend including the views)src/sentry/snubaandsrc/sentry/eventstore/snuba– Parts of Snuba
While not investigated further, these hotspots could be related to bugfixes after a new major release.
Architectural Roadmap
Given the roadmap in our first essay “Putting Sentry into Context” we know the future direction of Sentry:
- In the short term improve developer experience, specifically for developers that run their applications on devices not in their control like on mobile, in the browser, or on the desktop.
- In the long term, move into the application monitoring space (APM).
In this section, we discuss how the current architecture would be affected by this roadmap.We will be selecting components from the architectural decomposition (C4 model) from our second essay “The Architecture Powering Sentry” to demonstrate what components are relevant for the roadmap.
First improving the experience for developers, not in control of the hardware their applications run on, can be done by improving the integration, symbolication, and with respect to symbolication the visualization of the symbolication. Improvements in this area, with respect to the C4 model, would have to be seen in the single-page application, symbolication process, and the Sentry SDK’s for platforms like native desktop, mobile, and web.
The second part of the roadmap, to broaden the application scope from error monitoring to application monitoring, is a bigger change and therefore seen as a long term goal. Nonetheless, Sentry already contains some of the functionality required for application monitoring, specifically the functionality that overlaps with error monitoring, like cross-stack tracing of events and optimized searching through events using an eventstore. Further development towards this long term goal will affect the parts of Sentry related to handling events as not all events will be errors and there will be a higher amount of events coming in. The parts affected, with respect to the C4 model, will be the backend itself (due to changes in the API and higher load), event writing/reading, the event database and the single-page application.
Code Quality & Maintainability
Now that we have identified some interesting components in the codebase, let’s take a look at some code quality and maintainability metrics for Sentry. Technical debt is a metaphor that highlights the unnecessary complexity in an application that makes implementing new features more difficult 6. Estimations of the amount of technical debt are expressed in time and can be used to get an idea about the maintainability of a codebase. Technical debt can be analyzed by SonarQube, which uses the SQALE method to estimate this. Debt ratio is the ratio of technical debt to the total amount of development time 7.
We have applied this analysis to selected parts of the Sentry codebase, namely the main source code folders and the hotspots and roadmap modules outlined earlier based on the C4-model from the previous essay. The results from SonarQube are shown in the table below. According to SonarQube, Sentry scores an A for maintainability based on a low debt ratio (< 5%). The results indicate that the components are of high quality and the low debt ratio indicates that future changes should not result in issues.
The table below also contains test coverage results as reported by Codecov on the master branch.
Sentry has a fairly high test coverage and even the hotspots and roadmap components mostly have high coverage.
Sentry code measures
| Source | Related to | Line coverage (Codecov) | Technical Debt | Debt ratio |
|---|---|---|---|---|
| src | 75.20% | 25d | 0.1% | |
| src/sentry | 86.12% | 24d | 0.1% | |
| src/sentry_plugins | 65.92% | 6h 55m | 0.1% | |
| Hotspots | ||||
| src/sentry/static/sentry/app/views | Frontend views | 63.66% | 1d 1h | 0.0% |
| src/sentry/snuba | Snuba integration | 86.12% | 3h 52min | 0.5% |
| src/sentry/eventstore/snuba | Snuba integration | 97.5% | 6min | 0.1% |
| Roadmap components | ||||
| src/sentry/eventstore | Event reading | 93.86% | 31min | 0.2% |
| src/sentry/eventstream | Event writing | 70.66% | 3h 57min | 0.9% |
| src/sentry/lang | Symbolication | 88.64% | 2h 51min | 0.3% |
| src/sentry/api | API | 89.32% | 5d | 0.3% |
Refactoring Suggestions
SonarQube reports in total 2,729 issues when analyzing the Sentry codebase. These issues are violations of the rules that are defined by SonarQube. In the table below, the rules that are violated more than 50 times are shown.
| Language | Rule Violation | # of violations |
|---|---|---|
| Python | String literals duplicated three or more times | 1378 |
| Python | Cognitive Complexity of functions higher than 15 | 245 |
| Python | Functions with more than 7 parameters | 88 |
| JavaScript | Unused local variables or functions | 76 |
| Python | Collapsible if statements that are not merged |
75 |
| JavaScript | Default export names and file names that are not matched | 63 |
| Python | Empty functions or methods | 56 |
By far the most violated rule is the duplication of string literals in Python. When looking at the specific violations, we can see that this happens often with for example configuration strings and dictionary keys. These violations are understandable, but it is recommended to define constants for the strings in these cases, which will improve the maintainability.
Another issue that can be observed frequently in the Sentry codebase is functions with high complexity. SonarQube uses its own metric for this, called Cognitive Complexity, which measures how understandable a function is 8. This greatly influences maintainability, so it is recommended to split up functions with high complexity.
Sigrid performs some analyses that SonarQube does not perform, especially related to components and the interaction between components. Sigrid ranks these analyses for each codebase on a scale from 0.5 to 5.5. One analysis where Sentry has a pretty low score (1.7), is called component entanglement. This checks the communication between components. For this analysis, Sigrid gives 66 refactoring candidates, which are mostly cyclic dependencies between components. The presence of cyclic dependencies adds complexity to the architecture, which makes the code more difficult to extend and maintain.
-
Starke, G. (n.d.). arc42 Documentation. Retrieved March 24, 2020, from https://docs.arc42.org/home/. ↩
-
Sentry. (2018, August 6). Minimize Risk with Continuous Integration (CI) and Deployment (CD). Retrieved March 24, 2020, from https://blog.sentry.io/2018/08/06/minimize-risk-continuous-shipping-integration-deployment ↩ ↩2
-
Sentry. (2018, July 23). Modernizing Development with Continuous Shipping. Retrieved March 24, 2020, from https://blog.sentry.io/2018/07/23/modernizing-development-continuous-shipping ↩ ↩2
-
Sentry. (2018, October 11). Shipping Clean Code at Sentry with Linters, Travis CI, Percy, & More. Retrieved March 24, 2020, from https://blog.sentry.io/2018/10/11/shipping-clean-code-linters-travis-ci-percy ↩ ↩2 ↩3
-
Sentry. (n.d.). Contributing. Retrieved March 24, 2020, from https://docs.sentry.io/development/contribute/contributing/. ↩
-
Fowler, M. (2019, May 21). TechnicalDebt. Retrieved March 25, 2020, from https://www.martinfowler.com/bliki/TechnicalDebt.html ↩
-
SonarQube. (n.d.). Metric Definitions | SonarQube Docs. Retrieved March 25, 2020, from https://docs.sonarqube.org/latest/user-guide/metric-definitions/ ↩
-
Campbell, G. A. (2017). Cognitive Complexity - A new way of measuring understandability. Retrieved from https://www.sonarsource.com/docs/CognitiveComplexity.pdf ↩