No programming language is the same. Different syntaxes, static/dynamic typing, and varying build processes are just a few examples of differences that make it difficult to write a single piece of code that can report errors back to Sentry for all runtimes. Previously we have introduced Sentry, discussed it’s architecture, and its development process. Now we broaden our scope to the ecosystem of SDKs supported by Sentry. We will show how Sentry is able to support many different runtimes and we will take a look at these SDKs that report back to Sentry to see how they work.
Sentry currently actively supports SDKs (Software Development Kits) for more than 12 languages. Moreover, they support a wide variety of frameworks for these languages, ranging from front-end frameworks to game engines1. Next to the SDKs maintained by Sentry itself, there are also various community supported SDKs available thanks to Sentry being open about how SDKs can and should be developed. Everyone can write or customize an SDK for their own software, as long as it is compatible with Sentry’s specifications (which we will discuss soon).

How Sentry’s SDKs are being developed
The SDKs developed by Sentry are not included in Sentry’s repository itself. Instead, SDKs have their own repositories under Sentry’s GitHub organisation. The SDK repositories are mostly made per language, although there are a few exceptions. For example, there is a sentry-laravel repository that makes use of the SDK from sentry-php. However, the Node.js SDK is simply a package within the sentry-javascript repository. It is unclear why Sentry decided to take these different approaches.
Since the SDK repositories maintained by Sentry are separate from the main repository, they also have their own development practices. These practices include code quality assessment and Continuous Integration (CI) – topics that we have discussed about Sentry as well in other essays. Since these topics are not well-documented and vary from repository to repository, we cannot take an in-depth look. We can make some general observations though.
First of all, most if not all of the repositories seem to have automated tests and at least one CI pipeline (mostly Travis CI). The CI builds are often configured to test the SDKs in a variety of ways such as for different versions of the language it is written in. However, some repositories seem to care more about test coverage or code quality in general than others (or Sentry itself for that matter). We have seen some repositories boasting a Codecov badge with a high coverage percentage like sentry-javascript and sentry-dotnet, while other repositories have not even added Codecov analysis like sentry-python or sentry-java. It remains unclear why this is the case. We assume this is related to the difference in core contributors of these repositories. Another interesting observation was that the licenses between the different SDKs vary from the BSD (v2 or v3) clause to the MIT license, although this might have to do with compatibility with dependency licenses.
The Sentry forum is an important place for the (initial) development of the SDKs. If people are looking for an SDK of a specific language or framework that does not exist yet, they can indicate this on the forum or decide to make the SDK themselves and ask the Sentry team or the other community members for help.
The Sentry team uses the forum to ask the community for feedback. For example when they released a new version of the Python SDK.
How Sentry’s SDKs work
Sentry’s SDKs are a crucial part of Sentry as without them no error events would be captured and sent. In this section we take a general look at the working of such an SDK. Our findings are based on analysing a set of the SDKs and public information on the Sentry forums and their blog.
At the end of 2018 the Sentry team made the decision to revamp all existing SDKs to support a single unified API2. This decision was made to provide a unified experience across all SDKs, the basic construct being a simple initialisation step that should be similar everywhere:
init({dsn});
We want a unified language/wording of all SDK APIs to aid support and documentation as well as making it easier for users to use Sentry in different environments.3
One of the reasons is in line with the roadmap we talked about in “Putting Sentry into Context”: To move into the APM (application monitoring) domain.
Design the SDK in a way where we can trivially add new features later that go past pure event reporting (transactions, APM etc.)3
Due to this revamp a lot of the different SDKs are now more similar and we can define the general workings of them:
- Each SDK will have an init method (in the syntax of the runtime) that supports a configuration, at minimum this should include a DSN code (to have working event reporting). This code is used by Sentry itself to identify the related project.
- Every SDK will have one or multiple “Hub”s which are objects that store state3.
- The initialisation of the SDK should be done at the start of the application.
- Now behaviour starts to differ between different SDK’s as for each runtime the situation is different. However from our findings we can conclude that the SDK will try to capture errors being reported and send them with their context to Sentry with minimal (sometimes no) code added by the developer.
The unified API also makes it possible to manually capture events or add context data like breadcrumbs (used as a trail of events, leading up to an event). Due to the unified API this can be done in similar fashions for all SDKs using the likes of: capture_event and add_breadcrumb.
Integrations
Manually capturing errors and collecting useful information for these errors can be a lot of work, but fortunately the Sentry SDKs help us out with integrations for many popular frameworks.
It is common to use frameworks on top of a runtime/language to help development. Take for example Flask, which is a lightweight web backend framework for Python. Sentry has a integration for the Python SDK that works specifically for Flask4. When specifying this integration in the Sentry Python SDK it provides the SDK with more knowledge about your application, which in turn means that you as developer will be provided better insights into the events presented by Sentry. In this example this would (among others) include:
- request data like: HTTP method, URL, headers, form data, JSON payloads
- if using authentication through ‘flask-login’, user data could be attached to events like an id, email, or username.
Sentry has similar integrations for the popular frontend frameworks (React, Vue, Angular, and more) that automatically detect relevant contextual information such as UI interactions, HTTP requests, etc.
Integrations are therefore a powerful aspect of these SDK’s as they remove setup required to retrieve the extra context around events sent to Sentry. At least for the more popular frameworks.
How SDKs communicate with Sentry
Every one of the different SDKs wants to report events (whether they are errors or something else) to the Sentry backend to be analysed and to eventually be shown to the developer. The SDKs do this by sending their events to the /api/{PROJECT_ID}/store/ endpoint5.
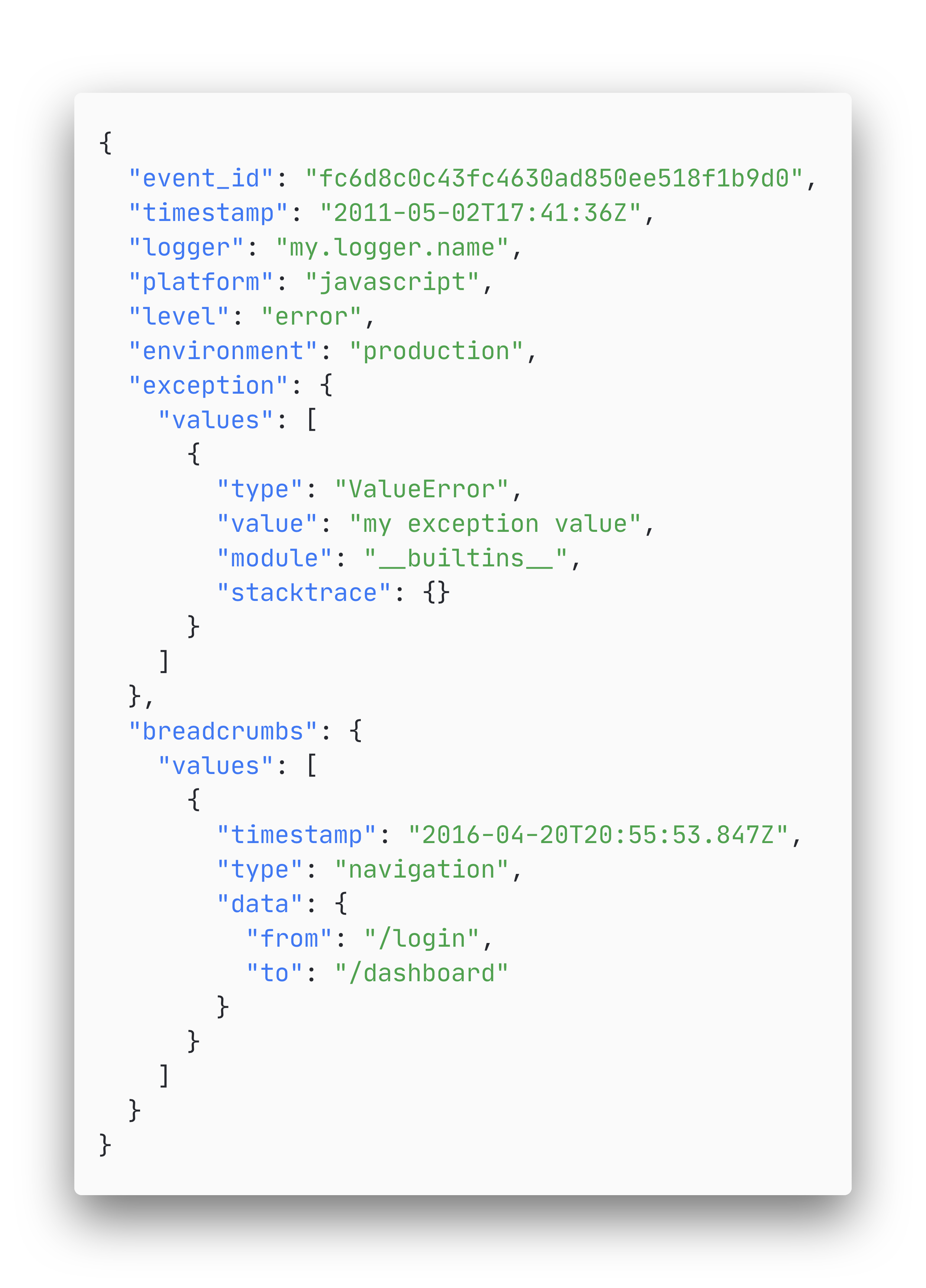
The event object
Events should contain some required attributes, such as an event_id, which identifies the event5. This identifier is automatically added by most SDKs as a UUID4.
Other required fields include a timestamp, the name of the logger that reported the event, and the platform from which the event was submitted.
Furthermore, Sentry recommends to add some other attributes with general information to the error object, such as the event level (e.g. error, info, etc.), the software release version, the environment (e.g. production or development) and more.
Additionally, more detailed information can be attached to the events via the core and scope interfaces5. The core interfaces include the exception interface, the stacktrace interface, the message interface and the template interface. These data objects contain the specific error or message event that is captured. Furthermore, the scope interfaces give more contextual information about the captured events. These include the breadcrumbs, request and UI interfaces that can contain events that happened prior to the captured event, but also a contexts interface that typically contains relevant information about the user or the environment.
An example of an event body can be seen below:
Backend processing
Upon receiving events (with identification of the dsn code) the Sentry backend processes the event by:
- Extracting the projectId from the url, and
- Scrubbing sensative data according to project settings, and
- Storing the event in the event database
This will then trigger other components of Sentry to further process the event if needed. This is described in more detail in “The Architecture Powering Sentry”.
How you can build your own SDK
Now that we know a little about the existing SDKs, the general working of them and the communication they have with Sentry itself, how do we build an SDK?
Sentry provides a detailed guide explaining what is expected behaviour for our SDK. This includes adhering to the unified API as explained before.
According to this guide the base of our SDK should to be able to automatically capture errors and at least contain the following set of features6:
- DSN configuration (Data Source Name: represents the configuration of the Sentry SDK, for example including an auth token and project id.)
- Graceful failures (catching failures such as an unreachable Sentry server)
- Setting attributes (such as a list of tags for the event containing context or versioning information)
- Support for Linux, Windows, and OS X (depending on the type SDK you are building)
Further development should target the full list of expected features described in the documentation. Such as the asynchronous transmission of events (in the background) or the automatic collection of stack traces on an error event. Depending on the target language or framework, this can be difficult. For example, for compiled applications the retrieval of the stack trace can be really hard. As debug information (like a stack trace) can be really large (a couple of gigabytes in some cases for a single crash), Sentry encourages contributors to use gzip for encoding the event body to decrease the event message size.
-
Sentry. (n.d.). Platforms - Docs. Retrieved April 8, 2020, from https://docs.sentry.io/platforms/ ↩
-
Sentry. (2018, August 8). Join the Discussion on Sentry’s Streamlined SDKs. Retrieved April 9, 2020, from https://blog.sentry.io/2018/08/08/new-sdk-unified-api-feedback-requested/ ↩
-
Sentry. (n.d.). Unified API. Retrieved April 9, 2020, from https://docs.sentry.io/development/sdk-dev/unified-api/ ↩ ↩2 ↩3
-
Sentry. (n.d.). Flask - Docs. Retrieved April 8, 2020, from https://docs.sentry.io/platforms/python/flask/ ↩
-
Sentry. (n.d.). Event Payloads. Retrieved April 8, 2020, from https://docs.sentry.io/development/sdk-dev/event-payloads/ ↩ ↩2 ↩3
-
Sentry. (n.d.). SDK Development Overview. Retrieved April 8, 2020, from https://docs.sentry.io/development/sdk-dev/ ↩