Previously, we introduced Archie’s vision for Solidity. This time, let’s dive deeper into Solidity’s architecture with our ever-curious software architect apprentice!

Figure: Image of Archie
Relevant Architectural Views

Figure: Image of Archie
In 1995, Philippe Kruchten published an article called: “Architectural Blueprints - The “4 + 1” View Model of Software Architecture”1. It introduced a model for describing the architecture of a software-intensive system using so-called viewpoints. To get a grasp on Solidity’s architecture, we can use an extended version of this model introduced by Nick Rozanski and Eoin Woods 2 3:
| Viewpoint | Description |
|---|---|
| Functional | Describes the system’s runtime functional elements, their responsibilities, interfaces and primary interactions. |
| Informational | Describes the way that the architecture stores, manipulates, manages, and distributes information (including content, structure, ownership, latency, references, and data migration). |
| Concurrency | Describes the concurrency structure of the system, and maps functional elements to concurrency units to clearly identify the parts of the system that can execute concurrently and how this is coordinated and controlled. |
| Development | Describes the constraints that the architecture places on the software development process. |
| Deployment | Describes the environment into which the system will be deployed, capturing the hardware environment, the technical environment requirements for each element and the mapping of the software elements to the runtime environment that will execute them. |
| Operational | Describes how the system will be operated, administered and supported when it is running in its production environment. For all but the smallest simplest systems, installing, managing and operating the system is a significant task that must be considered and planned at design time. |
Are all of these viewpoints relevant? As it turns out, not exactly. As a programming language, certain viewpoints are more applicable to Solidity than others. Based on the industrial experience report of Woods4 we can select three of them:
| Viewpoint | Consideration |
|---|---|
| Functional | A compiler is essentially a multi-step translator, where each step has a well-defined responsibility |
| Development | As a multi-stage process, dependencies between a compiler’s components often constrain the development process. |
| Operational | The Solidity compiler is not, as we’ll see, merely a one-trick pony; it is capable of much more than rote code generation |
We will lay out the Development view and the Functional view, but we can’t ignore the elephant in the room forever: Solidity’s architectural style and patterns.

Figure: Image of Archie
Architectural style and patterns
One of the central parts of software architecture is choosing a style and applying design patterns to obtain elegant and robust software. As it is a compiler, it goes through several stages: lexing, syntax checking, type checking, static analysis and code generation. The pipe and filter pattern is thus a natural style for Solidity.

Pipes-and-filter pattern 5
Check out Solidity’s particular compilation pipeline summarized below with a flow chart to get clear view on the data’s flow throughout the compilation process:
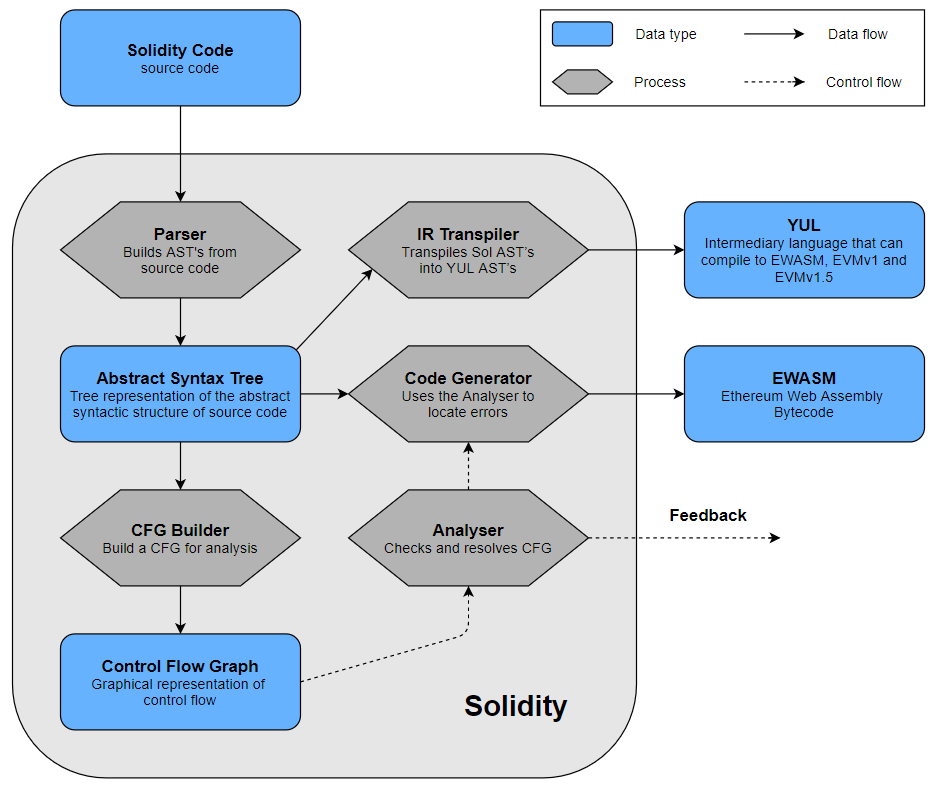
Source code to bytecode flow chart
The input of the pipeline is the smart contract’s source code, written in Solidity. First, a lexer converts the character stream into a stream of tokens. This stream is then parsed into an Abstract Syntax Tree (ASTs), a tree representation of the code’s abstract syntactic structure. The ASTs are then used to build Control Flow Graphs (CFGs), which are used further down the line by the static analyser. The analyser first checks the syntax, then annotates the AST with the types and does type checking and finally analyses the contract levels. It also resolves references and names. If the analysis finds an error, feedback is provided to the user. Otherwise, the code generator generates the target code from the ASTs. The default target is EVM bytecode. Apart from this, Solidity also contains a transpiler that can compile Solidity to Yul, an intermediate representation (IR).
Now back to the viewpoints!
Functional view

Figure: Image of Archie
Let’s take a look at the flow of the program. The code is first parsed by the, well, parser, resulting in an AST, which is then statically analysed.
- First, the syntax is checked, for instance for absent end of statement (eos) tokens.
- Next, the NatSpec documentation is parsed and added as annotations to the AST.
- Names and types are checked, and the AST is annotated with the types. This happens in several steps: first, declarations and imports are registered. Next, names and types are resolved, after which inheritance and interface implementations are processed. Then, type requirements are checked, and finally types themselves are verified.
- The control flow is analyzed. It is here that for instance dead code and uninitialized variables are detected.
- A static analysis is performed to flag potential code smells.
- Lastly, a state check is performed to verify whether state transitions are clean, and a model check verifies if the program actually does what it’s supposed to do according to its specification.
After this the code generator (what most people consider the compiler’s core) is ran. Only targeted files are compiled. First dependencies of the target files are compiled, then the AST is optimized and compiled. Finally, a check whether the gas limitations are honoured is performed (never forget the gas!).
After compilation, the EVM bytecode is ready. However, the user may choose to compile to Yul code instead of EWASM bytecode. This happens in the same way as the EVM bytecode compilation; only targeted files are compiled and dependencies are compiled first.

Figure: Run-time view
Development view

Figure: Image of Archie
The development view describes the constraints that the architecture places on the software development process.
Let’s derive this by giving an overview of the system decomposition, the modules of the system and their dependencies. The system contains three libraries that are used by almost all the modules: Solidity Utilities, Abstract Syntax Tree, and Language Utilities (The white modules in the image). The three modules have been replicated to keep the image clear.
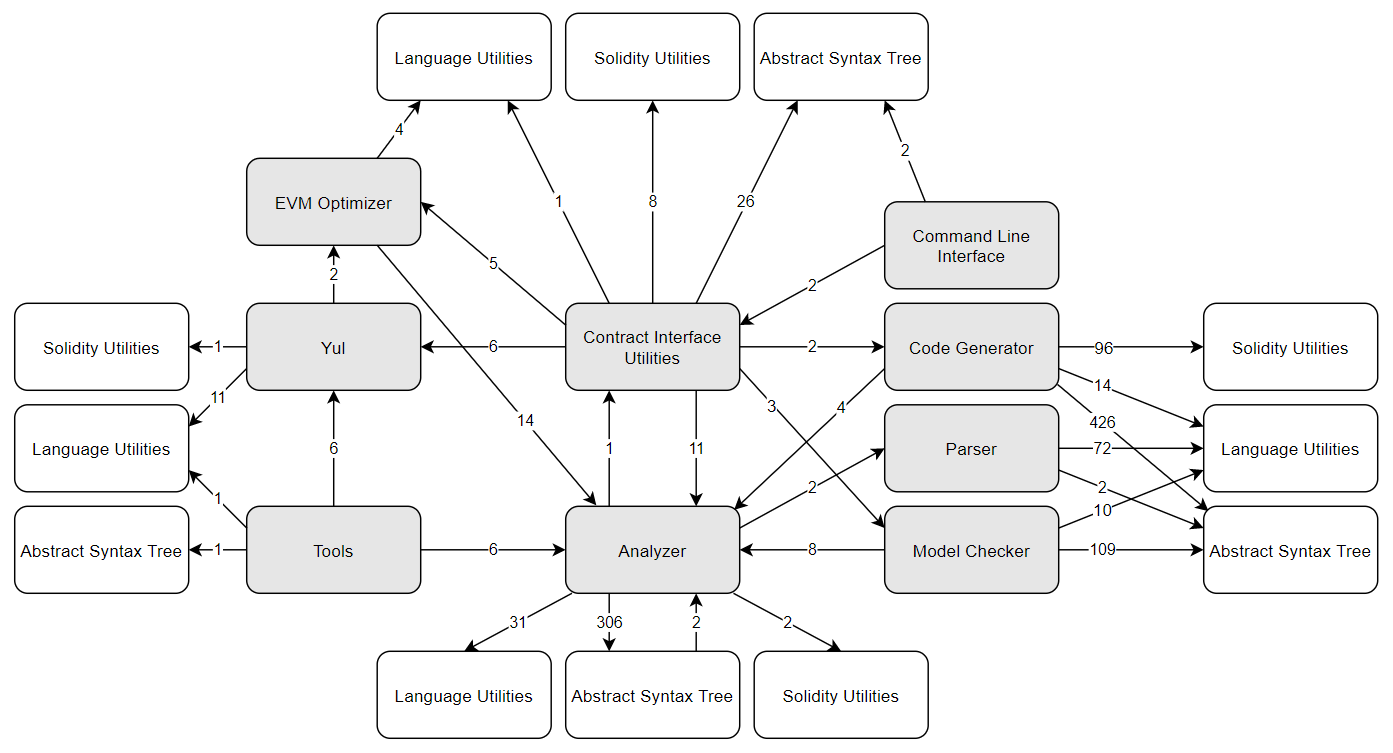
Figure: Modules
| Module | Description | Contents |
|---|---|---|
| Abstract Syntax Tree | ABT, Types, Type provider, ABT storage methods | |
| Analyzer | Control flow graph, Control flow graph builder, Name and type resolver, reference resolver, Syntax checker, Override and other checkers | |
| Command Line Interface | Program entry, Arguments & input parser, some basic application logic | |
| Code Generator | Expression compiler, Contract Compiler, Utility functions, Module with IR | |
| Contract Interface Utilities | Full compiler stack | |
| EVM Optimizer | Gas Meter, EVM state, EVM instructions, Control flow graph optimizer, Assembly functions | |
| Language Utilities | Lexer | |
| Model Checker | ||
| Parser | ||
| Solidity Utilities | ||
| Tools | Version Updater, Yul Phaser | |
| Yul | Yul intermediate language, multiple backend target language |
In general, changes can be freely made to the compiler’s internals for each module. However, a change to a module’s functionality must be propagated to all subsequent stages in the compilation pipeline. This restricts the developers’ freedom to independently work on different stages without coordinating, something that they achieve through the Scrum agile methodology6.
Operational view
There isn’t just one way to use solc, the Solidity compiler. In fact, in these early stages, both Solidity and the EVM still introduce breaking changes sometimes7.
solc can compile for different versions of the EVM, it can do dry-runs, and quite interestingly also transpile to Yul! Yul is an intermediate representation that can be used for high-level optimization.
A nice architectural feature of the command-line compiler is that in can also be fed the options as a JSON file for automated workflows by using te JSON-input-output interface.
Quality properties

Figure: Image of Archie
The Solidity compiler gets the job done: after all, it is the most popular language in use for smart contracts today, being responsible for the handling of millions in assets. But how well does it get the job done?
In the context of smart contracts, a realistic ranking of quality properties by importance would be:
- Security
- Gas cost
- Compilation speed (which we’ll skip for now)
Security
A smart contract can go wrong in three ways, as security issues can pop up in: the platform (EVM), the compiler (Solidity), or your own smart contract. The platform isn’t our concern here, but it’s important to note that the Solidity dev team must write a compiler which compiles source code correctly and thus securely while at the same time making it as easy as possible to write secure contracts. The second concern is in fact openly stated during the very first ETH DevCon 8. There’s also a bug bounty program for the code generator, and we can take a look at the list of security bugs 9 until now to convince ourselves that security bugs do happen at a non-negligible rate (Serpent, Solidity’s predecessor, was actually abandoned en masse after an OpenZeppelin security audit revealing gaping flaws in its security 10).
Fear not, Solidity has done a lot at the architectural level to reduce security risks: security is an ongoing concern throughout the compilation chain.
The syntax is checked by a separate module (SyntaxChecker.cpp). Furthermore, Solidity is not only statically typed (as types need to be known at compile time), but also strongly typed, and types are also checked by a separate module (TypeChecker.cpp).
As pointed out in the OpenZeppelin audit, Serpent’s utter lack of a type system was one of its most flagrant security shortcomings. Finally, during static analysis, warnings are emitted by the compiler, and following their advice is an easy way to make your contract more secure. Solidity also offers language features such as function modifiers (pure, view, payable), encapsulation, etc…
One of the very cool security-oriented features of Solidity is also its builtin formal verification capabilities: it offers a model checker allowing you to verify if your implementation follows the specification (mind you, this still leaves you open to insidious errors in the specification itself).
Gas cost
In Solidity, you pay ETH tokens in the form of gas to run your contract. The more you pay, the more incentive miners have to add your transaction to the blockchain, the faster it goes through. Solidity addresses this in three ways: it lets users get a gas estimate with a command-line option, it offers a range of types so as to allow efficient usage and it tries to optimize gas costs during compilation.

Figure: Image of Archie
-
Kruchten, P. (1995). Architectural Blueprints - The “4 + 1” View Model of Software Architecture. ↩
-
Rozanski, N., & Woods, E. (2005). Applying viewpoints and views to software architecture. Open University White Paper. ↩
-
Rozanski, N., & Woods, E. (2012). Software systems architecture: working with stakeholders using viewpoints and perspectives. Addison-Wesley. ↩
-
Woods, E. (2004, May). Experiences using viewpoints for information systems architecture: An industrial experience report. In European Workshop on Software Architecture (pp. 182-193). Springer, Berlin, Heidelberg. ↩
-
Mallawaarachchi, V. (2018, April 27). 10 Common Software Architectural Patterns in a nutshell. Retrieved from https://towardsdatascience.com/10-common-software-architectural-patterns-in-a-nutshell-a0b47a1e9013 ↩
-
Ehlert, S. (2015, January 9). Retrieved from https://www.youtube.com/watch?v=tOwhUkp38bI ↩
-
Retrieved from https://solidity.readthedocs.io/en/v0.6.2/060-breaking-changes.html ↩
-
Wood, G., & Reitwiessner, C. (2015, January 6). Ethereum DevCon-0: Solidity, Vision and Roadmap. Retrieved from https://www.youtube.com/watch?v=DIqGDNPO5YM ↩
-
Retrieved from https://solidity.readthedocs.io/en/v0.5.3/bugs.html#known-bugs ↩
-
OpenZeppelin. (2017, July 28). Retrieved from https://blog.openzeppelin.com/serpent-compiler-audit-3095d1257929/ ↩