This is the third essay on the Solidity project. This essay is about the code quality of Solidity. It will give an answer to the important question: Is the code of Solidity of solid quality or not, and how it this quality maintained?
Defining software quality
What does writing quality code mean? Without centering on a specific domain, the main meaning it registers with developers pertains to change. Grady Booch defines software architecture as the “significant design decisions that shape a system, where significant is measured by cost of change”. But resistance to change can be generated at any level of abstraction, down to the implementation details themselves. This is the so-called technical debt, which causes you to pay interest on it in the form of extra work when you add new features.
This is but one of the quality properties that code might have. Indeed, there are other quality properties desirable for a system, such as speed or security.
Determining software quality
Now that we have defined two different types of software quality, we are going to look at how Solidity tests these types of qualities.
Most of the packages in solidity have unit tests in the test folder. These tests can be ran by running a shell script: scripts/tests.sh. These are however a lot of tests so it might be faster to only run specific tests during implementation.
Non-functional requirements are not as easy to test, but luckily the repository contains a number of scripts in the scripts and the test directories used to automate non-functional requirement testing.
These tests are important as having a good universal coding style, documentation etcetera improve the readability of the code a lot.
test/buglistTests.jstests if known bugs are not correctly avoided in the code.test/docsCodeStyle.shtests if documentation is styled correctly.scripts/checkStyle.shperforms a C++ style check on all C++ code files.scripts/test_antlr_grammar.shtests if all sol files are parsable and thus grammatically correct.scripts/pylint_all.pyperforms syntax testing on all python scripts.
Continuous integration
Like most repositories, Solidity uses Continuous Integration to ensure lasting code quality standards. The CI performs most tests mentioned above, and some additional tests to ensure functionality on different platforms.
The first category of tests performed by CircleCI are simply builds.
Here the CI tries to build the system on different platforms with a standard Release target.
The second category performs all defined unit tests on the platforms mentioned above. Being able to build the system on a platform is one thing, but knowing that the system behaves the same is crucial in a program such as this one.
Lastly style, syntax and bug checks are performed. These are not platform specific as they run in bash and python, or use third-party software to rely on, such as antlr, Z3, Asan etc. Following is a list of checks that are performed by CircleCI.
- check spelling
- check documentation examples
- check C++ coding style
- run operating systems checks
- run buglist test
- run pylint (pylint: checker/code analysis)
- check antlr grammar (antlr: tool for processing structured text)
- run z3 proofs (z3: theorem prover)
- ASan build and tests (Asan: tool that detects memory corruption bugs)
- Emscripten build and run selected tests (Emscripten: toolchain for compiling C/C++ to asm.js and WebAssembly)
- OSSFUZZ builds and (regression) tests (fuzzing: test correctness by generating program inputs to reach certain execution states)
Next to these CircleCI tests, there are also Appveyor and Travis tests. Appveyor is used exclusively for Microsoft Windows tests (Presumably because CircleCI doesn’t work well with Windows). The same build and tests as mentioned above are performed here. Travis is used for deploying code and services to, for example, docker and other repositories.
Test quality
Defining tests and implementing continuous integration is one thing, but those tests also need to be of high quality to make any difference. How can we determine if tests are of high quality?
To do this, we will first look at the functional tests, the unit tests. The easiest and dirtiest way to look at unit test quality is to look at the line coverage and the branch coverage of those tests. Unfortunately the maintainers of Solidity decided that code coverage is too misleading to use, so they did not implement it in their continuous integration.
However Solidity does use Codecov for coverage analysis. This application can be launched by continuous integration, but the maintainers of Solidity decided to only run it for certain pull requests and commits. The newest coverage report we could find is presented here, but nevertheless it is unfortunately pretty outdated.
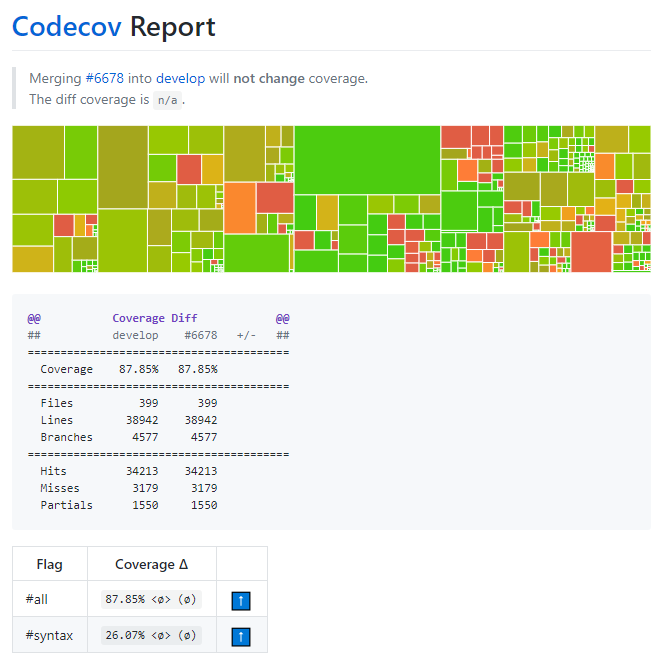
Figure: Solidity code coverage
Another indication of test quality is ratio of test code. According to SIG the test code ratio of Solidity is 111.9%. This means for each line of code there are 1.119 lines of test code on average, and that 52.8% of the repository is test code. As the repository contains more test code than functional source code, this is a pretty good ratio. However this still doesn’t mean those tests are of high quality, and there is no good way to determine this without looking at each and every test, and the code.
Determining the quality of non-functional tests is a whole different story compared to unit tests. The best way we can do this is by looking at what the tests check, and testing if they break when deliberately introducing styling flaws.
We will look at some of these tests to analyse what they do and if we think that adds something to the repository.
An important readability tool is the code style checker, scripts/checkStyle.sh.
This checker simply performs a bunch of greps on all .cpp and .h files. It checks if whitespace is used correctly and at the right places, and if certain keywords are in the right order.
Most other checkers make use of existing software to check for example if files can be parsed. These parsers and linters are used a lot and thus we can trust that these do what they should do. Because python and solidity files are not built or tested by the build targets, these files have to be tested separately on syntax errors. These are important tests as broken scripts or even solidity example scripts might slip through the tests if these aren’t performed.
Activity
One of the interesting things to look at is the recent code activity and how that activity relates to the architectural components. We looked at the number of code changes in the last month of the development branch to get an idea of this.
| module | number of changes |
|---|---|
| circleci | 151 |
| code generator | 778 |
| model checker | 576 |
| contract interface | 109 |
| abstract syntax tree | 105 |
| analyser | 349 |
| yul phaser | 2760 |
| docs | 797 |
| scripts | 603 |
| EVM optimizer | 474 |
| yul library | 75 |
| commandline compiler | 67 |
| language utilities | 3 |
| utility library | 156 |
| test module | number of changes |
|---|---|
| smt checker tests | 709 |
| semantic tests | 6454 |
| syntax tests | 543 |
| abstract syntax tree JSON tests | 473 |
| yul phaser tests | 3096 |
| yul library / object compiler tests | 15 |
| yul library / yul optimizer tests | 1561 |
| yul library tests | 285 |
| command line tests | 77 |
| utility library tests | 53 |
We can see some hotspots in the coding activity. The majority of the changes have been made in the yul phaser, the yul library, the yul phaser tests and the semantic tests. This observation matches with the open projects in Solidity (https://github.com/ethereum/solidity/projects), here we see a big Yul project that is 70% done. Another big project is called ‘SMT Checker MVP’ where the authors aim to develop the semantics checker towards a minimum viable product. The checker proves if the written code is correct or not and aims to catch bugs at compile time. This most likely relates to the majority of the changes made in the code generator, model checker, contract interface, smt checker tests, semantics tests and syntax tests modules. We can also see other projects that match with the observed changes, such as: wasm, documentation translation, ect.
We can also conduct a high-level analysis based on the roadmap projects. We assume that projects most likely to be worked on are those with at least one issue in progress and rank them by a combination of the number of issues in progress and issues to do. We consider issues in progress as a multiplier for issues to do: likely_amount_of_work = #_issues_in_progress * #_issues_to_do. The tie between Consolidate inheritance rules and Natspec, which have no issues in progress, is broken by the total number of issues.
The ranking is:
- Yul
- SMT Checker MVP (not taken into account)
- Zeppelin Audit (not taken into account)
- Sol -> Yul codegen
- Wasm/Ewasm
- Consolidate inheritance rules
- NatSpec
We can assign a partial score from 0 to 6 to each component identified by Sigrid Says everytime it is a part of one of these projects (except the SMT checker and Zeppelin audit): score = 7 - project_rank. We can then sum the partial scores to yield a total score for expected change magnitude:
- libsolidity (12)
- codegen (9)
- libyul; solc; interface (8)
- libevmasm (6)
- analysis; ast (1)
Architectural roadmap
The roadmap for Solidity features is a list of GitHub projects.
-
Natspec: NatSpec (Natural Specification) is a rich documentation format for functions, return variables and other constructs.
- liblangutil
- ErrorReporter.cpp: it reports errors when parsing docstrings
- Scanner.cpp: the lexer must scan comments
- libsolidity
- analysis
- DocStringAnalyser.cpp: does static analysis on docstrings
- analysis
- liblangutil
-
Wasm/Ewasm: Ewasm (Ethereum WebAssembly) will replace the EVM (Ethereum Virtual Machine) as the state execution engine of the Ethereum network as part of Eth 2.0.
- libyul
- backends/wasm
- EVMToEwasmTranslator.cpp: a translator facilitates passage from EVM to Ewasm
- BinaryTransform.cpp: transforms internal wasm to binary
- AssemblyStack.cpp: handles Ewasm assembly
- backends/wasm
- libsolidity
- interface
- CompilerStack.cpp: the compiler stack generates Ewasm
- StandardCompiler.cpp: as the standard compiler, it can take requests for Ewasm code
- interface
- solc
- CommandLineInterface.cpp: the CLI accepts Ewasm command line parameters
- libyul
-
Reducing technical debt: Accumulated technical debt is to be reduced through refactoring.
-
Sol -> Yul CodeGen: The project concerns the code generation step for compiling from Solidity to Yul, an intermediate representation language.
- libsolidity
- codegen
- YulUtilFunctions.cpp: utility functions for Yul
- codegen/ir
- IRGeneratorForStatements.cpp: this generates Yul for statement tokens
- IRGenerationContext.cpp: an expression token is situated in a context, taken into account during Yul generation
- codegen
- libsolidity
-
Emscripten: The project concerns the configuration of Emscripten, which is used to compile to WebAssembly.
-
Documentation translation: As the name states, this is about translating documentation to various languages.
-
Yul: The project concerns the Yul format, optimizations that can be done to the code in Yul format as well as compilation from Yul to other targets.
- libevmasm
- AssemblyItem.cpp
- libsolidity/interface
- CompilerStack.cpp: the compiler stack handles the source mapping
- StandardCompiler.cpp: the standard compiler interacts with the source mapping
- libsolidity/codegen
- ir
- IRGenerate.cpp
- ir
- libyul
- AssemblyStack.cpp: the source mapping’s is from assembly to source
- AsmAnalysis.cpp: this analyzes the assembly code
- libyul/backends
- evm
- EVMDialect.cpp
- AsmCodeGen.cpp
- EVMCodeTransform.cpp
- wasm
- EVMToEwasmTranslator.cpp
- WasmDialect.cpp
- optimiser
- ConditionalSimplifier.cpp
- ControlFlowSimplifier.cpp
- evm
- solc
- CommandLineInterface.cpp
- libevmasm
-
Zeppelin Audit: The project aims to fix security issues found during the audit conducted by Zeppelin.
-
Backlog (breaking): All breaking changes (non-backward compatible) are here.
-
Consolidate inheritance rules: As a contract-oriented programming language, contracts in Solidity can inherit from one another. This project aims to make the inheritance rules more comprehensive.
- libsolidity/analysis
- TypeChecker.cpp: the type checker needs to take into account inheritance rules
- OverrideChecker.cpp
- libsolidity/ast
- AST.cpp: the AST needs to conform to the inheritance rules
- ASTJsonConverter.cpp
- libsolidity/analysis
-
SMT Checker MVP: The project aims to reach a minimum viable product (MVP) for a satisfiability modulo theories (SMT) automated checker. It is unrelated to Solidity releases and is fairly independent.
-
Backlog (non-breaking): All non-breaking (backward compatible) changes are here.
Code quality assesment
Let’s look at the Sigrid Says measurements. They’re given on a scale from 0 to 5.5, which we split into five categories:
- 0-0.9: worrying
- 1-1.9: poor
- 2-2.9: average
- 3-3.9: good
- 4-5.5: excellent
Sigrid can only do so much, so meaning should only be assigned to these values in context.
| Component | Overall maintainability | Volume | Duplication | Unit size | Unit complexity | Unit interfacing | Module coupling | Component independence |
|---|---|---|---|---|---|---|---|---|
| all | average | excellent | excellent | poor | poor | average | average | average |
| libsolidity | good | excellent | good | average | average | average | excellent | excellent |
| codegen | average | excellent | excellent | worrying | poor | average | average | good |
| libyul | good | excellent | excellent | average | average | average | excellent | good |
| solc | good | excellent | excellent | worrying | worrying | excellent | excellent | excellent |
| interface | average | excellent | excellent | poor | poor | good | poor | poor |
| libevmasm | average | excellent | excellent | poor | poor | poor | good | average |
| analysis | average | excellent | excellent | poor | worrying | good | average | worrying |
| ast | average | excellent | excellent | good | average | good | worrying | worrying |
On average, Solidity is ranked as an average project. Its strong suits on average seem to be volume and duplication, and it additionally ranks very well in terms of component balance, scoring a 4,6. Three components register two metrics in the worrying category, namely solc, analysis and ast. Luckily, these are rather unlikely to register major changes, so according to Ward Cunningham’s technical debt allegory, it is probable that not a lot of interest in terms of work will be spent changing these components.
Importance of code quality
A central considerent for Solidity in terms of code quality is security, as Solidity is used to write contracts handling actual financial assets. In fact, there’s an entire chapter in the documentation pertaining to it. The contributing guide gives insight regarding what is considered essential for code quality. A Git flow is enforced, and it is recommended that each contribution come with its own tests. For larger changes, it is recommended to consult the development team on the development Gitter. The coding style is well defined and tested for in the CI process. American Fuzzy Lop (AFL) is used for fuzz testing.
The testing label
The GitHub issue tracker for solidity has a dedicated testing label to be added to all issues related to testing. At the time of writing, there are 55 open issues and 84 closed. Out of 680 open issues, 8% are testing issues. As issues 7860 and 7861 show, alternatives for current code coverage reporting, which is limited, are being considered.
Refactoring suggestions
When we look at the refactoring candidates resulting from the Sig analysis, we see that the code generator module pops out. The code generator module has a lot of long functions and methods. It also contains a lot of complex functions (measured with McCabe complexity1). This is probably where most of the improvements are possible. Long and complex functions are difficult to understand and require more test cases, and even then it is much more difficult to cover all possible cases. Aside from this we can conclude the following from the analysis:
- Duplication is not a problem in the Solidity code base, there is actually very little duplication.
- Unit interfacing: The analysis shows there are some functions and methods with many parameters that are good candidates for refactoring but that this number is fairly small.
- Separation of concerns: The abstract syntax tree module and the language utilities module have a strong coupling between their files. Specifically, the AST files are very strongly coupled, making them difficult to analyse, test and modify.
- Component independence is a point of attention throughout the codebase especially in the analysis and code generator modules, which makes system maintenance more difficult.
-
McCabe, T. J. (1976). A complexity measure. IEEE Transactions on software Engineering, (4), 308-320. ↩