In this blog post, we take a sneak-peek into a leading-edge Natural Language Processing (NLP) library for Python, its stakeholders and its journey up until now. Hence we decided to get some words together (pun intented) to describe the insipiration behind ExplosionAI’s NLP project: spaCy
The Vision
spaCy is a free, open-source library for advanced Natural Language Processing or NLP (written in Python and Cython), developed by Matthew Honnibal. To quote Matthew, “I wrote spaCy because I think small companies are terrible at natural language processing (NLP). Or rather: small companies are using terrible NLP technology.” 1
What spaCy tries to achieve
spaCy strives to provide a production level Natural Language Processing pipeline that is fast and efficient. It aims to bridge the gap in cutting-edge NLP between production and academia. Libraries like NLTK provide the necessary tools but are intended to support research and teaching rather than focus on production-level functionalities. This is where spaCy earns its coin, by making production level NLP accessible and deployable. It is a very popular NLP library owing partly to its regular, cutting-edge updates (especially with implementations of state-of-the-art models of Big Transformers like BERT, GPT-2) and constant improvements in performance.
What spaCy is:
-
It can be used to build information extraction systems
-
Or Natural Language understanding systems.
-
It can be used to pre-process text for deep learning.
What spaCy is NOT:
-
It is not an API or an NLP platform of sorts.
-
It is also not an out-of-the-box chat-bot or a conversation-engine.
-
It is not a research software. (as mentioned earlier)
-
Finally, it is NOT a company. ExplosionAI is the company responsible for publishing spaCy.
Importantly and admittedly spaCy is for production-use and hence involves fairly different design decisions than NLTK or CoreNLP; which we will deep-dive in the later essays2.
Code: Python, Cython
Platforms: Linux, Windows, Mac
End User Mental Model
Academic improvements in quality of models in the NLP domain hasn’t been concurrent with commercial NLP. This is largely attributed to the fact that reaching production-level with NLP models requires a huge training effort, an intricate pipeline and not to mention complicated model implementations. This has generally deterred individuals and companies alike in terms of developing real and applied NLP products.
Matthew Honnibal (founder ExplosionAI) developed spaCy as a tool particularly for this purpose: bringing advanced and applied NLP into real products. It is designed to be an ‘Industrial Strength NLP’ library with efficiency, state-of-the-art implementations, fast deployment (in production) and easy model integrations as its core characteristics. The intention behind spaCy was to provide production level NLP tools for the applied data scientist and/or relatively smaller companies/teams, where NLP was stuck in a limbo due to esoteric implementation of algorithms and exorbitantly expensive training required for language data.
spaCy is hence built for simplicity in production and deployment, performs incredibly fast (Implemented in Cython and admittedly one of the fastest syntactic parsers available) and does away with a lot of the complexity of liguistic models; thus earning it high praise as the ‘Numpy’ of NLP! 3
Key Capabilities and Properties
spaCy aims to be one-stop-shop for all tasks NLP. Providing production-level code while being easy to apply are two pillars at the forefront of its development. To this end spaCy’s features and key capabilities are as follows:
(Some of them refer to linguistic concepts, while others are related to more general machine learning functionality)
- Tokenisation
- Part-of-speech (POS) Tagging
- Dependency Parsing
- Lemmatization
- Named Entity Recognition (NER)
- Entity Linking
- Similarity
- Text Classification
- Sentence Boundary Detection
- Word-to-vector transformations
- Out-of-the-box methods for cleaning and normalization of textual data
- Cutting-Edge pre-trained models for SOTA-NLP
Stakeholders
Stakeholders of the spaCy Project:
Matthew Honnibal
spaCy is Matthew’s brainchild, forged with a vision to create an production-level library of utility functions for NLP. After spaCy’s release in 2016 and its eventual success, ExplosionAI was founded as a software company specializing in developer tools for AI and Natural Language Processing with spaCy as their showcase product.
ExplosionAI
Known as “The makers of spaCy”, ExplosionAI is a company founded by Matthew Honnibal along with co-founder Ines Montani4. They now maintian spaCy as an open source repository under the MIT license with regular feature development.
End-Users
Based on the use-case requirements we can broadly categorize the end-users as,
- Commercial NLP: These are the companies/teams that are actively using spaCy in production for their NLP based applications. They represent the main target audience of spaCy given that it allows them to leverage cutting-edge NLP for real-world products. Example: Uber, Airbnb, Quora 5
- Data Scientists and Enthusiasts (NLP): Both professional Data Scientists and hobbyist developers have a similar use-case with spaCy for their NLP based requirements. spaCy is widely used for both personal/professional projects as well as for academic research.
The end-users mentioned above are the main consumers and stakeholders of the product and drive the development roadmap for spaCy as per Matthew.
GitHub
As the spaCy project is maintained publicly on GitHub and encourages active contribution from the community, we hence consider GitHub to be an integral stakeholder in the successful development of the project.
spaCy Community
-
Contributors: spaCy has a vibrant community of developers and contributors as espoused from the 408 direct contibutors and 24,574 contributors in its dependency graph (at the time of writing). It maintains a thorough issue tracker and actively monitors Gitter chat and the reddit/stackoverflow support groups.
-
Users (Current and Past): We consider that users play an active role in the spaCy community by participating in its development through reporting of bugs, recommending new and relevant features and suggesting certain improvements. Since spaCy is constantly under development, these users are an important source of feedback.
-
Ecosystem: There are several projects (or extensions) that primarily use or even build on spaCy and hence are considered as stakeholders. Example: sense2vec, neuralcoref, displaCy etc.
Current & future context
In order to provide a clear understanding of the operation context of the spaCy project, we have an illustration that depicts various dependencies, relationships and intersections of spaCy as a product.
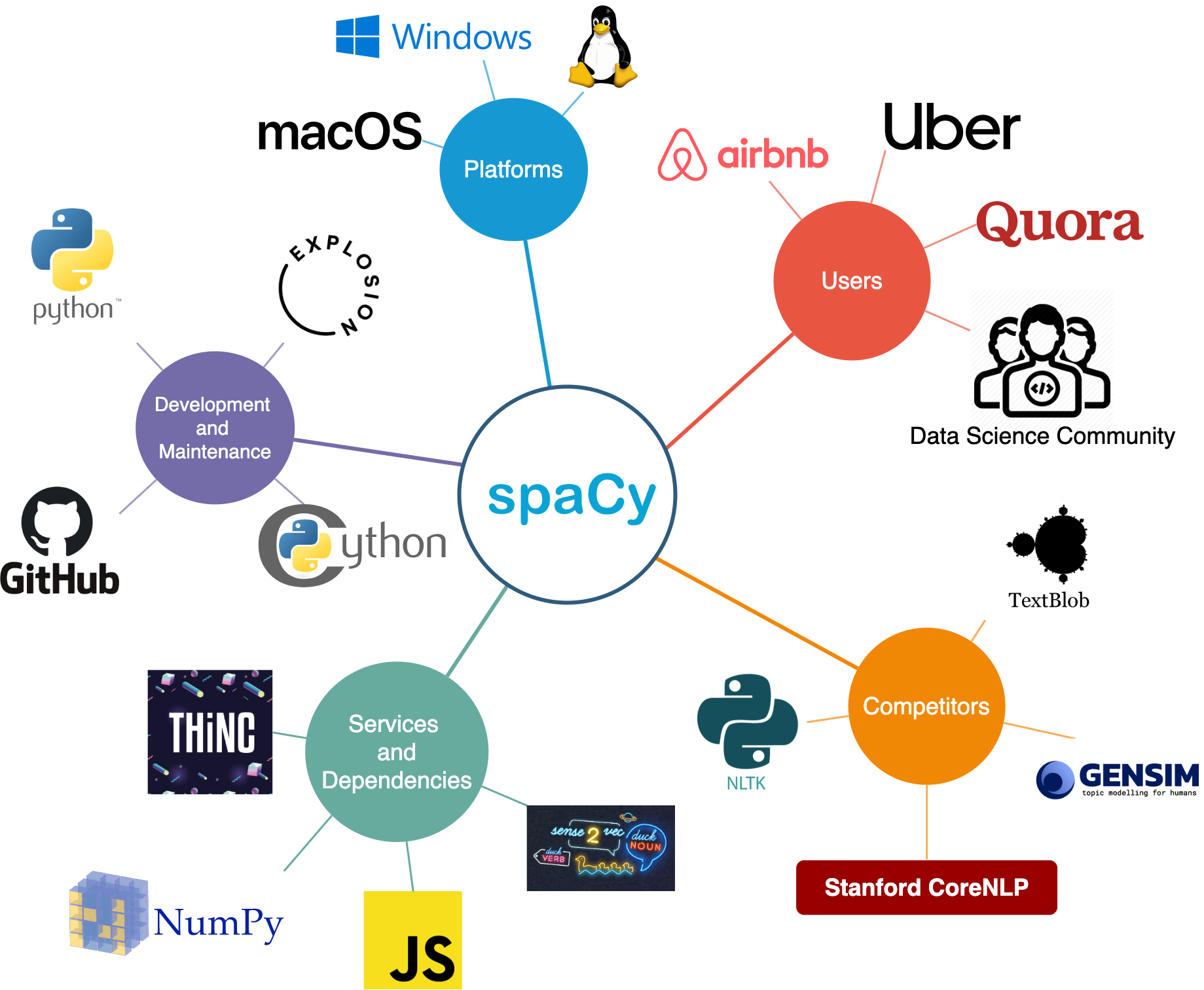
Figure: Context view
The spaCy project is written majorly in Python (Cython) and is actively maintained by the team at ExplosionAI with an open source MIT license on Github where it encourages contributions from the dev-community with an exhaustive list of code conventions and how-tos.
spaCy has dependencies in terms of libraries from which it derives some functionality like numpy, pandas and also certain libraries/softwares that are dependent on spaCy i.e. THiNC and sense2vec; these are typically products rolled out by ExplosionAI to build upon spaCy. For instance, sense2vec is a twist on traditional word2vec (word embeddings) based on spaCy.
There are notable alternatives to spaCy in the NLP for python domain namely NLTK and TextBlob. While these alternatives like NLTK, which is easy to use and possibly great for NLP research, certainly deserve the credit, spaCy is extremely optimized and understandably preferred in production environments. The main differences between spaCy and other alternatives is explained in the following table from their website6.
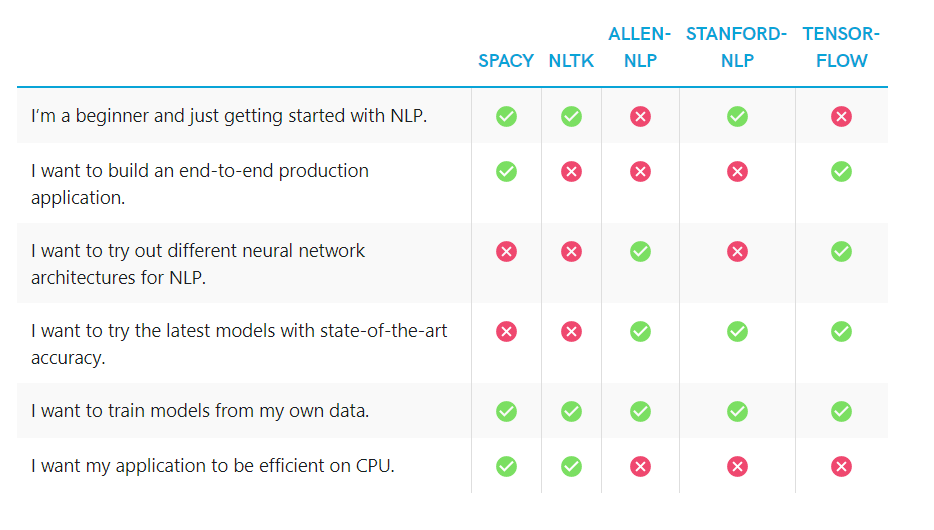
Figure: Alternative Comparison
Additionally, spaCy runs on windows, linux and macOS distributions alike.
RoadMap
SpaCy does not maintain an explicit future roadmap, neither on its repository nor its website, but it does have a list of pinned issues. This pinned issue list can be seen as a proxy for the actual roadmap, since these issues are the most important features/problems being tackled at any time.
Firstly, they want to add more pre-trained models for even more already supported languages. As of now, spaCy supports over 50 languages, but has pre-trained models for only 10 of them. The untrained languages are in “Alpha support”, which only includes tokenization and other rule-based methods7.
Example sentences for multiple languages are yet to be included. This would come in handy while testing in unfamiliar languages. They are gradually filling these in, but the issue is open since 20178.
Furthermore, ExplosionAI keeps a close contact with its stakeholders through regular blog posts3. Based on a recent post (regarding spaCy), a new data augmentation system is under development. This system should eventually translate to having a higher accuracy on texts with inconsistent casing and punctuation. 9
There are still more issues in their repository and as technical debt. Most of them are as an improvment on existing features, but some make suggestions for new features.
Stay Tuned!
spaCy strives to be a one-stop-shop for all things NLP. It truly merits its spot as the most popular and domain-leading NLP library. We intend to deep dive into how and why spaCy serves a core purpose in any NLP pipeline. Next, we pen down our research on how spaCy’s vision influenced its architectural decisions and the story behind its development!
To be continued…
-
Introducing SpaCy, https://explosion.ai/blog/introducing-spacy ↩
-
spaCy 101: Everything you need to know, https://spacy.io/usage/spacy-101 ↩
-
Explosion AI Blog, https://explosion.ai/blog/ ↩ ↩2
-
Introducing Explosion AI, https://explosion.ai/blog/introducing-explosion-ai ↩
-
Spacy main website, https://spacy.io/ ↩
-
Facts and Figures, https://spacy.io/usage/facts-figures ↩
-
Increased support for new languages, https://github.com/explosion/spaCy/issues/3056 ↩
-
Example sentences for testing languages, https://github.com/explosion/spaCy/issues/1107 ↩
-
Introducing spaCy v2.2, https://explosion.ai/blog/spacy-v2-2 ↩