SpaCy is the brainchild of Matthew Hannibal, who has a background in both Linguistics and Computer Science. After finishing his PhD and further 5 years of research in state-of-the art NLP systems, he decided to leave academia, created SpaCy and started interacting with a wider development community. 1
Being a NLP library for processing text, spaCy’s core is it’s processing pipeline, into which not only core NLP functions like tokenizer, lemmatizer and tagger integrate: spaCy supports custom pipeline components, allowing a big ecosystem of plugins and extensions to grow. 1
Architectural Views: A Discussion
In this article we examine the architecture of spaCy through the lens of architectural views as described by Kruchten 2. The four views are as follows:
- Logical View is a description of the design model that captures the functional requirements of the application. This is usually done through a clear decomposition of structural elements or abstractions. UML class diagrams or ER(Entity-Relationship) diagrams are often used as representations of the logical view.
- Process View describes the process i.e. the behaviour, concurrency and information-flow of a system. It usually deals with the non-functional aspects for example using Data Flow Diagrams or DFDs.
- Physical View is often seen from a system engineer’s point of view and is concerned with the software topology as well as its hardware mappings.
- Development View addresses the software management aspect with its development environment usually as seen from a programmers perspective.
Examining a library instead of a full bodied software program, we try to fit aspects of Kruchten’s view model to spaCy’s architecture and use-case. To this end, in terms of the logical view, the processing pipeline of spaCy seems to be the central element. All of spaCy’s multitude of modules like the tokenizer, NER-module etc. are built around it. This allows spaCy to have a single source of truth by avoiding multiple channels of data flow and saves memory as well. Since spaCy does not directly deal with database I/O or distributed-system functionalities, the process view seems to be an unimportant aspect for analysis. The physical view of a library (like spaCy) is also not of utmost importance to the developers as libraries are inherently built towards being platform/hardware agnostic. That being said, the physical resources of a system do affect the processing capabilities of spaCy’s various NLP models (especially deep neural models).
Addtionally, since the spaCy project is open-source, it attaches great importance to a high standard of development and collaboration which seems to form a part of the development view. This is evidenced from its nuanced and clear documentation on its code repository 3.
Furthermore, we also present two other architectural views (imporant to spaCy) that do not have an overlap with Kruchten’s theory namely, deployment and operational view. The deployment view describes the environment in which the system will be deployed. By doing most of the heavy-lifting i.e. by abstracting the code-complexities (of complicated transformer models, dependency-parsers etc.), spaCy projects itself as a developer-friendly library. This is an important consideration for its packaging (of spaCy’s various modules) and eventual deployment.The operational view, which describes system-operation post deployment, doesn’t seem relevant to spaCy as it is deployed as a package that can be updated (for eg: using imports). It’s not a service which needs regular monitoring.
Finally, the arc42 template 4 gives us food for thought about its runtime view and its application to spaCy. Since spaCy has quite a few dependencies (explicit as well as underlying) it is critical to consider the relevance of performance-variations that are well captured in the runtime view.
Development View
Chapter 20 of the Software Systems Architecture book 5 describes the Development Viewpoint. According to this chapter, this particular viewpoint describes the architecture which supports the software development process. It describes 6 main concerns.
- Module Organization: This concerns the organizational part of the code. Arranging code structurally logical will help dependency management.
- Common Processing: Identifying and isolating common processing into seperate coding modules.
- Standardization of Design: Using design patterns and off-the-shelf software elements in order to benefit team-work.
- Standardization of Testing: Creating a consisting approach to speed up the testing process.
- Instrumentation: Practice of using special logging information code.
- Codeline Organization: Used to ensure that the system’s code can be managed, build and tested.
In terms of a development view for spaCy:
There are some coding conventions6 which need to be followed whenever a contribution is made. This includes, but is not limited to; loosely following pep87, following a regular line length of 80 characters, with tolerance up to 90 characters. Also, they state that all code needs to be written in an intersection of Python 2 and python 3.
They have some information regarding the module organization as well. When someone wants to fix a bug, they first have to create an issue ( and check if there is none yet), then create a test file ( test_issue[ISSUE_NUMBER].py) in the spacy/tests/regression folder. This also includes the standardization of testing, the tests all have to be put in a certain file and have to be given a certain name. 8
System Decomposition
For analyzing dependencies between different modules in spaCy, we defined the main modules as: cli, data, displacy, lang, matcher, ml, pipeline, Remainder, spacy, syntax, tokens, website.
Using the tool Sigrid, we analyzed the dependencies between the components:
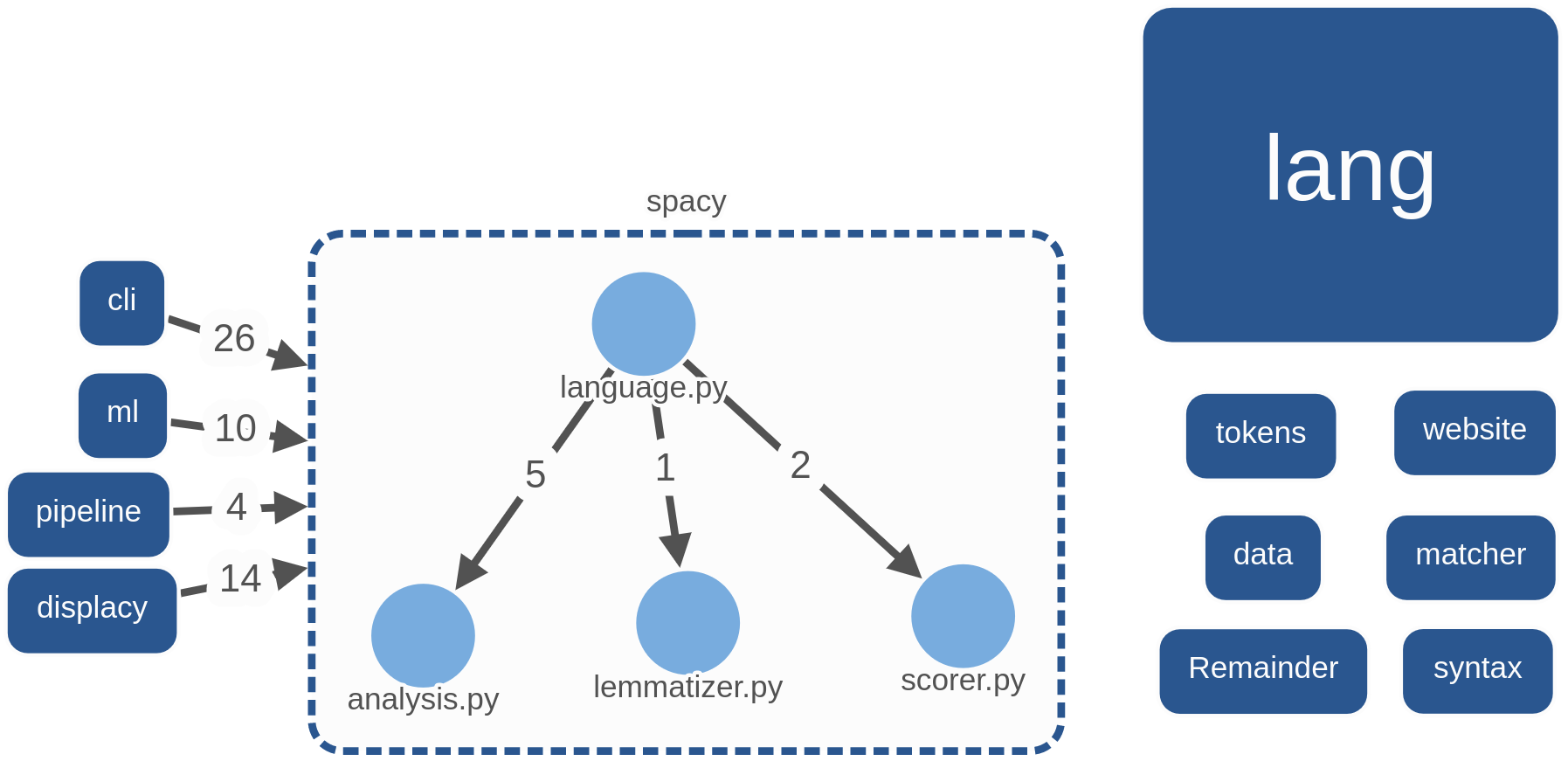
Figure: System Decomposition
Considering that spaCy is a tool that supports multiple languages the lang module is the biggest in code size by far. It contains rules and exceptions for all languages, which inevitably leads to code duplication. Different languages contain different (sub)modules, which makes it difficult to split it up further.
Runtime View
The runtime view describes the behaviour and interactions of system building blocks in the form of scenarios. 9 In this section, only some of the architecturally relevant scenarios are discussed.
Pipeline
In order to process a given text with the nlp, spaCy uses a basic pipeline. 10 To this pipeline, custom components can be added in order to make the eventual Doc object more suitable to your needs. In the following section, this basic pipeline is explained.

Figure: spaCy Pipeline
Tokenizer: Tokenization is one of the most used functions of spaCy, whenever spaCy processes a text, it uses tokenization first. Since this is the most used used function, we will take a look at how this tokenization works. Tokenization first segments the texts into words, punctuation and other characters. This segmentation is carried out by specific language rules. One example they give is that “U.K.” should remain as one token, whereas a “.” to close off the sentence should be split off.
In order to do this segmentation, first the text is split on whitespace characters. Then the program goes through the splitted from left to right, performing two checks on every substring. First it checks if the substring matches a tokenizer rule (U.K. should remain as one, but don’t should be split in do and n’t). Then it checks if a prefix, suffix or infix can be split off. If there is a match, the rule is applied and the tokenizer continues the loop untill the whole text is done. 11
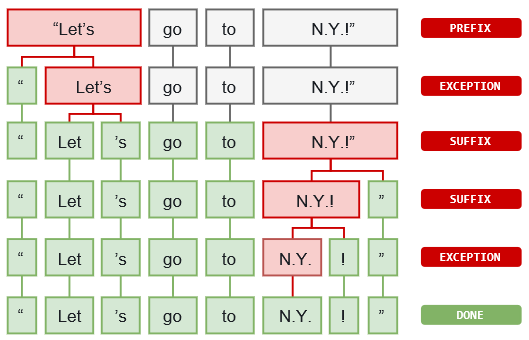
Figure: spaCy Tokenization
Tagger: After the tokenization, spaCy also makes it possible to parse and tag the newly found tokens with the specific contents. It assigns part-of-speech tags such as verb or noun to the tokens. Additionally it checks for dependencies between the tokens based on existing models. 11
Named Entity Recognizer (NER): After this tagging and parsing, the pipeline detects and labels named real-world entities. Examples of these entities are “Apple” (Organisation) , “U.K.”( Geopolitical entity) or “$1 Billion”(Monetary value). 11
Components: From spaCy v2.x, the statistical components, like the tagger or parser do not depend on each other, which means they can be switched around, or even removed from the pipeline. However, some of the custom components might need annotations from other components. 12
Compatibility: spaCy is compatible with the 64-bit CPython 2.7/3.5+ and it runs on Unix/Linux, macOS/OS X and Windows. 13
Deployment View
The section will describe the deployment process from the time a new major version is developed to the end-user receiving it on their local computer. It also describes SpaCy’s runtime requirements.
The maintainers of SpaCy have setup a Continuous Deployment pipeline that that pushes a new version to PyPI (python package index) everytime a new release is made. The infrastructure for making the packaged application available at a single location is maintained by The Python Packaging Authority(PyPA). Once deployed to PyPI, it is available for downloaded through standard Python package managers like pip and conda.
The decision to make SpaCy available through already existing infrastructre for Python package deployment has two main advantages. First, it allows the maintainers to focus improving the core features of the project and second, it reduces cognitive load on the end-user to build the package on their own, including building all related dependencies(of which there could be hundreds!). Most python packages distributed through PyPI have very similar workflow of installation.
SpaCy uses the SemVer policy of versioning14 with additional labels for pre-release/alpha features. Since SpaCy is quite an old project now (first commit back in 2015), it does not have a regular release cycle15. Instead, it keeps end-users engaged by publishing bleeding edge alpha releases through a separate channel, spacy-nightly. These are features that are not fully baked and may not make it to the next major version of the project.
Although there are some system requirements to able to deploy SpaCy, any system that can run Python with enough space to install SpaCy and all of its dependencies should be sufficient. Practically speaking, language modelling and Natural Language Processing is a highly compute heavy task which involves complex operations on large datasets. This could require high-end hardware which are specifically designed for performing such operations.
Trade-Offs and Non-Functional Properties
The modularity of the architecture allows for clear distinctions between functionality and provides centralized data retrieval check-point (single source of truth)
All the C-level functions (written in Cython) are designed for speed over reliability (safety) which is a clear trade-off made for internal code only. This means a program-crash due to an array-out-of-bounds error, although rare, is a bearable consequence for not having strict code-checking that could lead to a higher overhead i.e. slower pipeline.
A lot of the basic data-structures like arrays/vectors are purpose-typed in pure C/C++, which allows for a more elaborate error-checking by the compiler than in python.
Using Cython allows the developers to skip all the extravagant python optimization which usually requires a lot of experimentation to debug and eventually get right. This is an interesting but brave development choice as Cython isn’t as ubiquitous and has a fairly steep learning curve.
Matthew believes in iterative development based on active-learning and good tooling that makes experimentation faster; this is essential beacause a lot of the modelling and pipelining in spaCy is quite state-of-the art and often untested in theory. He worries about being able to scale down (rather than up) in order to facillitate faster and easier iterative development.
The developers use A/B evaluation to get quick feedback over small changes.
The people behing spaCy designs around (avoids) using crowdsourced annotations like mechanical turk for improving it’s language model due to multiple intermediate problems with this approach. Using it is said to generate low-quality data and makes it difficult tod inspect/interpret results in terms of distinguishing the actual pain-points. I would be unclear whether the wrong data, a poor annotation schema or the model is the limitation. ExplosionAI took the following measures:
- moved annotation in-house
- complex annotation tasks are broken up into simpler/smaller pieces
- usage of semi-automatic workflows
Conclusion
SpaCy is relatively mature library with an extensible architecture that has allowed a rich ecosystem16 to grow around it.
-
Matthew Honnibal & Ines Montani: spaCy and Explosion: past, present & future (spaCy IRL 2019), https://www.youtube.com/watch?v=Jk9y17lvltY&list=PLBmcuObd5An4UC6jvK_-eSl6jCvP1gwXc&index=13 ↩ ↩2
-
4+1 Architectural Views, https://en.wikipedia.org/wiki/4%2B1_architectural_view_model ↩
-
Github: SpaCy, https://github.com/explosion/spaCy ↩
-
Arc42 Template Overview, https://arc42.org/overview/ ↩
-
Nick Rozanski and Eoin Woods. Software Systems Architecture: Working with Stakeholders Using Viewpoints and Perspectives. Addison-Wesley, 2012, 2nd edition. ↩
-
Contributions Code conventions,https://gitlab.com/connectio/spaCy/-/blob/master/CONTRIBUTING.md#code-conventions ↩
-
Style Quide for Python, https://www.python.org/dev/peps/pep-0008/ ↩
-
Contributions Adding Tests,https://gitlab.com/connectio/spaCy/-/blob/master/CONTRIBUTING.md#code-conventions ↩
-
arc42 Documentation 6 Runtime View, https://docs.arc42.org/section-6/ ↩
-
Language Processing Pipelines, https://spacy.io/usage/processing-pipelines ↩
-
spaCy 101: Linquistic features, https://spacy.io/usage/spacy-101 ↩ ↩2 ↩3
-
Pipelines, https://spacy.io/usage/spacy-101#pipelines ↩
-
Install spaCy, https://spacy.io/usage/ ↩
-
SpaCy Versioning. https://github.com/explosion/spaCy/issues/3845 ↩
-
SpaCy Releases. https://github.com/explosion/spaCy/releases ↩
-
SpaCy Universe, https://spacy.io/universe ↩