Hi folks! we are back again with some more insights on your friendly neighborhood Spyder. In our first blog, we talked about the product vision of Spyder which focused on the core elements of the system along with the end-user mental model and analysis of the stakeholders. This essay explores how these elements are realized through its architecture and relationships, and the principles of its design and evolution.
Architectural Views
We start with architectural views in context of Spyder . The fundamental features of a complex system cannot be explained using a single model. Even if one tries to do so, it may happen that the model either becomes too difficult to comprehend or fail to identify the important features of the architecture. It is therefore advisable to break down the system in terms of separate but interrelated views which aim to explain different aspects of the architecture.
There are a number of views that can be used to describe the architecture of a system. Philippe Kruchten1 designed the “4+1 architectural view model” based on multiple and concurrent views. Furthermore, Rozanski and Woods2 have also proposed some additional views viz. Context, Functional, Information, Concurrency, Development, Deployment, and Operational views.
We now define the views that are relevant in the context of Spyder :
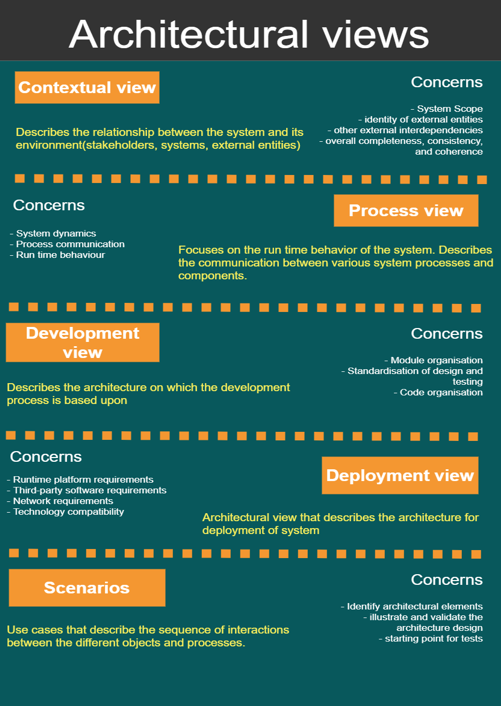
Figure: Architectural views of Spyder
Now let’s see why these views are relevant in the context of Spyder :
- Contextual view : As we’ve seen in essay 1, there are a lot of stakeholders involved in Spyder and therefore it becomes important to define what the system does and does not do, and how the system interacts with other systems, organizations, and the people involved.
- Process view : Spyder interacts a lot with other dependencies at run time(e.g. PyQt5, Pyflakes etc.). Moreover, Spyder makes use of various plugins(e.g. profiler, IPython console etc.) to build on the main components in the system. Hence, a process view showing all the system processes and how they communicate between each other becomes very important.
- Development view : There are a lot of modules in Spyder. One of the most important stakeholders in Spyder are the developers and the open source community. Therefore it becomes highly essential to have a development view to provide a programmer’s perspective on the system components.
- Deployment view : Spyder is available on various platforms. It comes bundled with Anaconda Python distribution and is also available to run and install individually. Hence Spyder is a system with complex runtime dependencies and complex runtime environment. It is therefore very crucial to address these concerns in the context of Spyder.
- Scenarios : Spyder has many types of users and stakeholders. It thus becomes important to visualise how these people interact with the system and how the system reacts to the actions performed by these people.
Architectural Styles and Patterns
Spyder employs an architecture where “plugins” are used to compartmentalize the main components of the whole system which resembles a microservice architecture. Some examples of plugins, as mentioned in the first essay; the editor component, profiler, IPython console, and variable explorer to name a few. Essentially, Spyder is completely comprised of these plugins. Plugins consist of QT widgets (GUI elements) with some extra code to embed the widget into the Spyder application3. The architecture of which can be seen in the image below. All these plugins are then called back in the main Spyder library. The manner in which these plugins communicate resemble a microservice system.
Additionally to the built-in plugins, third party plugins are a large part of Spyder’s functionality. Therefore Spyder offers an API that allows the user to create their own or extend the built-in editor, panel, manager etc. 3. And as seen, in the image below, the API makes calls to all the plugins.
In this way, the overarching architecture style/pattern seen in Spyder is the microservice architecture and can be visualized as the figure below 4.
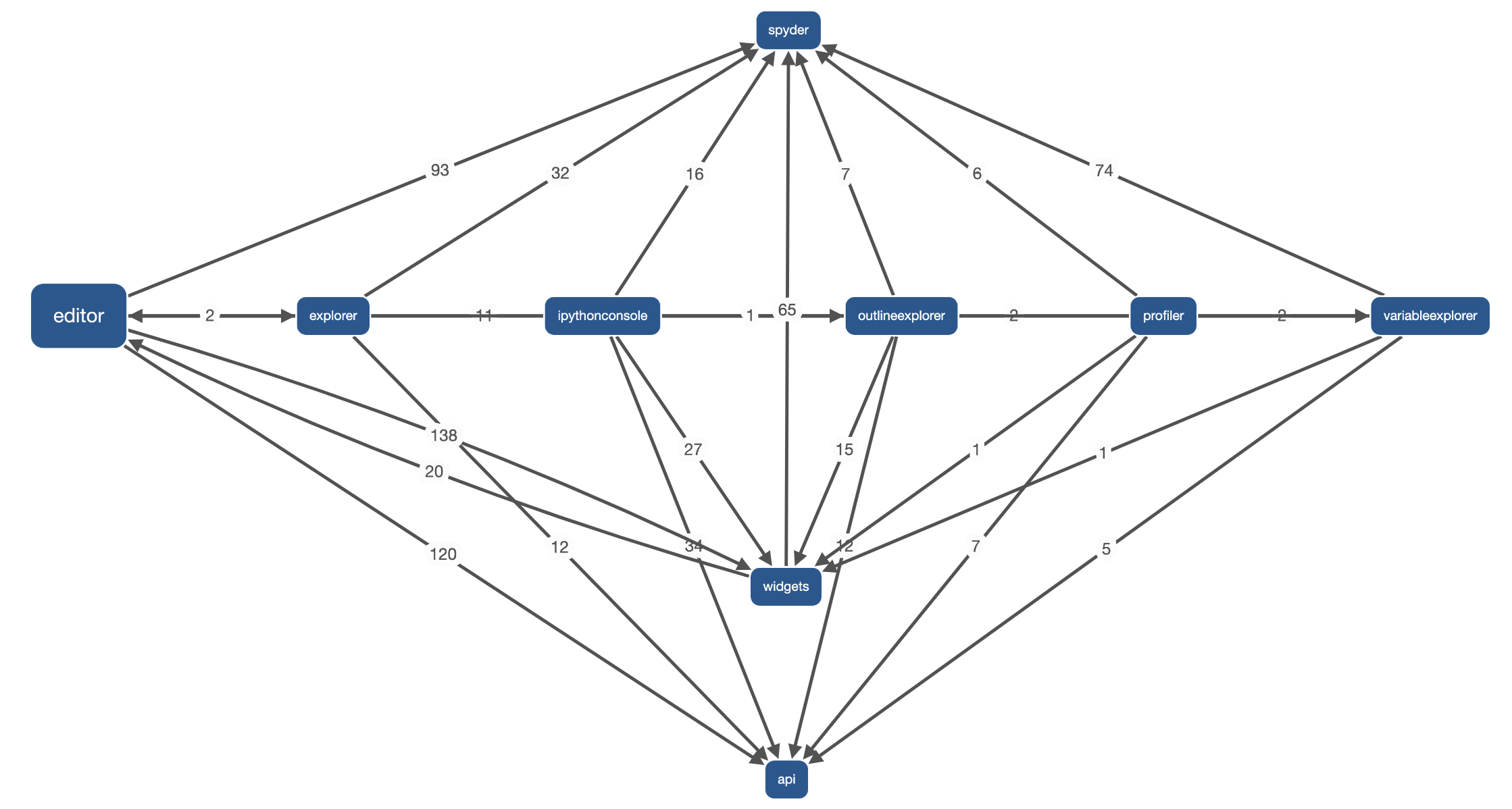
Figure: Architecture of Spyder
Development view
The main goal of the development view is to describe the architecture that the software is based on and analyze how it is developed. In the following sections we dive deeper into the system decomposition of Spyder and how they perform test for their codebase.
System Decomposition
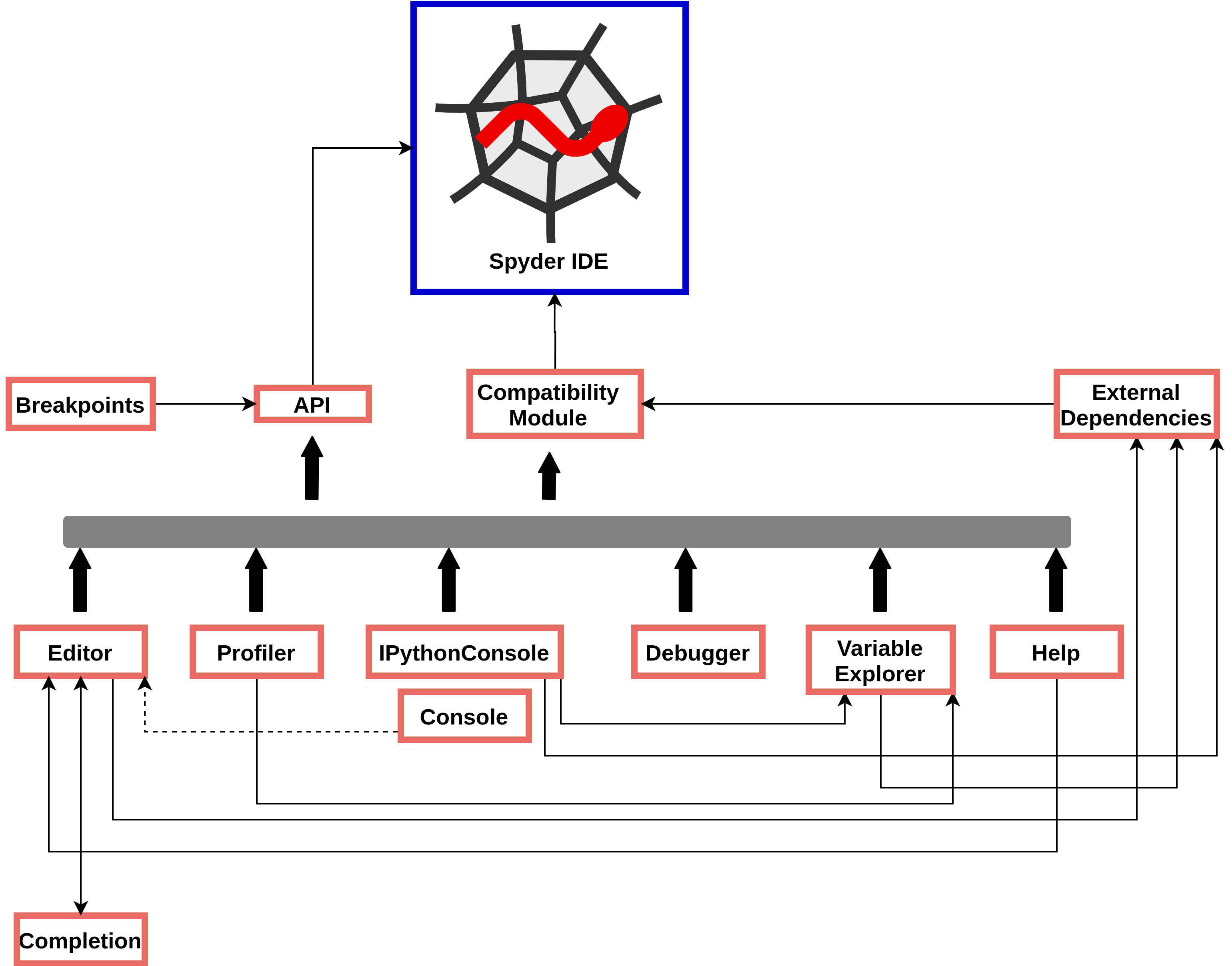
Figure: Main modules of Spyder
In the figure above the main modules of Spyder and their and their relations can be seen. The codebase analysis has been inspired by Sigrid. In the following section a more detailed description of the main modules are given.
- Compatibility Module
This module makes sure that all the developed code in different modules are compatible between Python 2 and Python 3. This module is dependent on other built-in modules from Python such as os, sys and operator.
- Editor
This module is the editor in the IDE. As can be seen in the figure above it is in middle layer between the IDE and the sub modules it inherits. Not all the submodules (e.g. code completion) are mentioned here to avoid clutter. This module is mainly based on PyQt module which is mainly for GUI design.
- Profiler
This module is responsible for analyzing the code performance and finding the bottlenecks. This module also uses QVBoxLayout routine from the PyQt widgets as a 3rd party module.
- IPythonConsole
This is a third party module imported for running the Python code. It is used as a plugin inside the Spyder. It has 3rd party dependencies such as jupyter_core, jupyter_client, qtconsole and zmq for ssh connection from the application to the IPythonConsole.
- Console
This is the internal console in the Spyder which can be used instead of the 3rd party IPythonConsole. It is dependent on PyQt, os, sys, logging libraries which the last three are built in in Python.
- Debugger
This is the Spyder debugger which can be used to debug the code or execute it line by line. This module calls the breakpoints from the API manager and it passes them to the Python built in debugger pdb.
- Variable Explorer
The variable explorer enables inspecting the normal and nested code variables on the fly. It used some remote settings from 3rd party libraries and it gets called from the consoles as can be seen in the figure above.
- Help
The help plugin is implemented and shown in the Spyder using a web view. For this it is using WebEngineWidget from PyQt among some other features from this library.
- API
This package includes some of classes which can be used to create 3rd party plugins and extend Spyder. It is still considered pre-released until the developers release Spyder 4.0 officially.
Testing
For testing Spyder the developers designed test file separately for each plugin in their specified folder. According to the Sigrid also the test to code ratio for Spyder is 25%. Also for every pull request some test are run automatically. There is also a runtest.py file provided by the developers for open source community. The goal is to pass the test after making changes to the code and before submitting it. This script will run some test automatically on the CI server. One can also use the pytest module and write their own test code which provide more flexibility for the developer. There is also a debug flag argument to run the code for the main IDE in case one wants to debug and see the debug prints with different Verbose.
Deployment view and Run-time view
After development of Spyder, we need to deploy it and run it. So, let’s have look at Deployment view and Run-time view. Rozanski and Woods 2 defined deployment view as “aspects of the system that are important after the system has been built and needs to be validation tested and transitioned to live operation”. A Deployment view is useful for any information system with a required deployment environment that is not immediately obvious to all of the interested stakeholders.
Deployment of Spyder
For using and installing Spyder, the Spyder development team recommends to use Anaconda Python distribution, which comes with everything Spyder needs to get started in an all-in-one package. However, it is also possible to install and run Spyder individually on popular operating system such as Windows, Linux and macOS. As an alternative to Anaconda one can also use miniConda, which just a lighter version of Anaconda. For the sake of simplicity and to avoid specificity of different OS and distributions, we consider the recommended Anaconda distribution as a run-time Software requirement for Spyder.

Figure: Deployment view of Spyder
The above figure gives a concise overview of Spyder’s deployment view. The Anaconda distribution is available on Windows, Linux and macOS, which makes Spyder available on these platforms too. Since most of systems today have the required configuration for installing a Python distribution, the hardware requirements pretty much depends on the task an individual wants to accomplish using Spyder. As far as network requirement is concerned, Spyder requires a network connection to check and download updates for improved experience.
Run-time view of Spyder
The Spyder IDE depends on numerous third party dependencies. The Anaconda distribution takes care of managing these dependencies for Spyder. These dependencies constantly interact with each other at run-time. The dependencies include 5 :

Figure: Dependency list of Spyder
The runtime view shows an overview of all systems and nodes that are involved when Spyder is running. It is a schematic overview of the aforementioned runtime requirements, third party dependencies and network requirements. The figure below shows the run-time view of Spyder. Parts of the diagram are based on an overview of the components and layers in the scientific computing environment for Python explained by Robert Johansson 6.
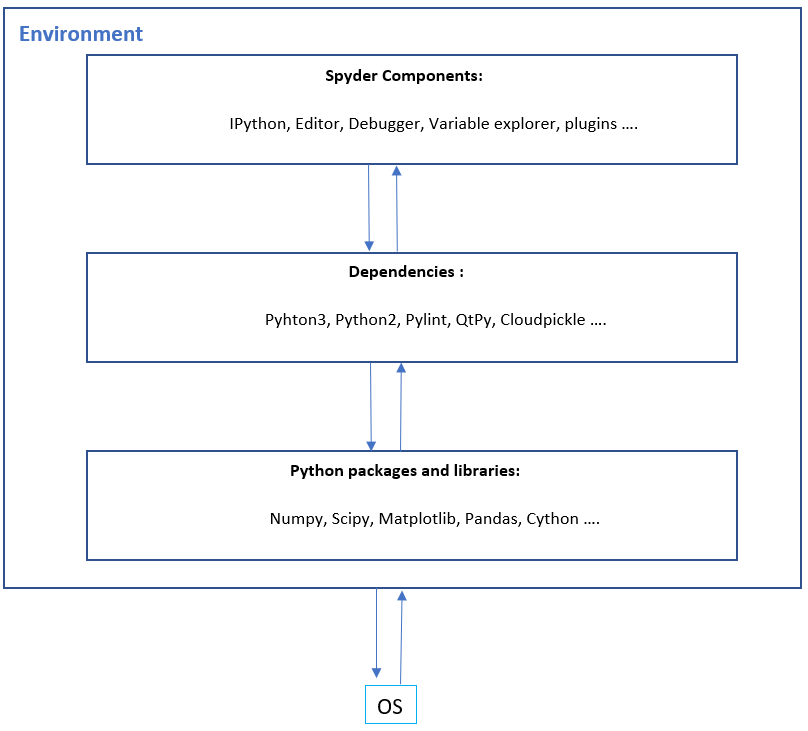
Figure: Run-time view of Spyder
Spyder adapting to improve non-functional properties
In the first blog we discussed the product vision of Spyder and the functionality it provides to meet the goals. In this blog up till now we discussed the architectural style, development view, run-time view and deployment in context of Spyder to support it’s functionality. However, design choices and trade-off have to be made to satisfy non-functional properties of software. A non-functional property (NFP) of a software system can be defined as a constraint on the manner in which the system implements and delivers its functionality 7. Some of the several NFP’s are efficiency, complexity, scalability, adaptability and dependability.
Over the years Spyder team has made some design choices and trade-off’s to satisfy the non-functional properties. Despite the desire to serve the end-users with Spyder distribution themselves, to increase the adaptability and maintainability, the Spyder team released the stable version 4.0.1 as an anaconda distribution and recommends it rather than different distributions for different platforms. Moreover, to improve the efficiency and decrease the software complexity, the Spyder team implemented api gateways in version 4.0.1 for separating the components and manage the interaction between them. Like most of the softwares, Spyder has it’s continuous integration (CI) pipeline. The CI pipeline is supported by CircleCI, Azzure pipelines and Codecov which run test scripts to monitor the code quality.
-
Kruchten, Philippe B. “The 4+ 1 view model of architecture.” IEEE software 12.6 (1995): 42-50. ↩
-
Nick Rozanski and Eoin Woods. Software Systems Architecture: Working with Stakeholders Using Viewpoints and Perspectives. Addison-Wesley, 2012, 2nd edition. website. Retrieved March 10, 2020. ↩ ↩2
-
Robert Johansson. Numerical Python, chapter 1, Introduction to Computing with Python pp 1-24. website. Retrieved March 10, 2020. ↩
-
Nick Eric M. Dashofy, Nenad Medvidovic, Richard N. Taylor. Software Architecture: Foundations, Theory, and Practice. Wiley, 2009. website. Retrieved March 16, 2020. ↩