Hi folks! We are back again with more insights on your friendly neighborhood Spyder. This time, we are going to focus on how Spyder safeguards the quality and architectural integrity of the underlying system.
Continuous Integration of Spyder
Spyder has employed three Continuous Integration (CI) pipelines namely CircleCI, TravisCI and Azure pipelines which run test scripts to monitor the code functionality. Moreover, Spyder also uses Codecov and Coveralls to monitor the coverage of test scripts.
Now that we have seen the CI pipelines used by Spyder, you might be thinking : What do the test scripts associated with these CI pipelines check/cover?
Since Spyder is almost 100% developed in Python, it uses Pytest and unittest frameworks which enables writing small test scripts for each component. The Spyder team follows a very simple convention, each component has a test folder which contains all the test scripts concerning that component. In general, almost every component has a test script which cover scenarios that the user might encounter while interacting with that component. For example, the Spyder editor 1 component has tests to check : auto save errors, auto-indentation feature, breakpoint feature etc. Similarly, other components have test scripts to check their functionality respectively. We won’t be talking about tests concerning other components because they are quite monotonous and can be easily understood by reading them.
Moreover, there are some checks that are conducted on all the components working integrated. For example, Spyder has tests script for dependency checks to check if all the dependencies required for Spyder are installed in the environment. Similarly, there are tests for Python compatibility checks for Python 2 and Python 3.
However, there still remains a question : Why does Spyder have three different CI pipelines?
Well, according to the Spyder team (we explicitly asked them on Gitter), the reason behind this are issues with Operating Systems (OS) and Python distribution. Spyder distribution is available on Windows, Linux and macOS. So, for each of the following combinations there is a different CI pipeline :
- Azure pipelines -> macOS, Windows
- CircleCI -> Linux with Python 2, Python 3.6
- Travis -> Linux with Python 3.7
However, Spyder team acknowledges the effort to maintain three different CI pipelines and have started migration to Github Actions 2 , which is a CI pipeline provided by Github.
By now you must be thinking : What about software quality checks?
Surprisingly, Spyder does not employ any sort of continuous inspection of code quality. In our opinion this is something Spyder needs to adopt. Hence, we are poised to recommend and set-up a pipeline for continuous inspection of code quality with SonarQube or Codacy for Spyder repository.
Lastly, in this section, we discuss the quality of the software quality processes we mentioned above. We already saw Spyder lacks a pipeline for continuous inspection of code quality. On top of this, according to Sigrid 3 analysis it has a low test-code ratio of 25.8%. Moreover, the code coverage 4 of Spyder is currently 69%, which is just about a reasonable goal to have 5. Discussions on test quality and new test scripts clearly lack in the issues of Spyder repository. However, the architecture and protocols followed by Spyder for adding test scripts make it easier to add new tests. Generally, the protocol is to create an issue for the bug and then create pull request with correction and a test in the test folder of the component to fix the bug.
Overall, Spyder is already following most of the contemporary practices (CI pipelines, code coverage) for automatic tests which implies they are concerned about code quality to some extent. In our opinion, they just need to increase the performance with respect to code quality metrics after setting up a proper pipeline for continuous inspection of code quality.
Code Quality Assessment
Different measures can be used to measure code quality qualitatively and quantitatively. Some of the qualitative measures can be Extensibility, Maintainability, Readability of the code and quantitative measures can be such as Complexity or LOC (Lines of Code).
In this post we are going to evaluate the code quality and maintainability of Spyder according Sigrid 3 analysis. The analysis will be done for the most maintained modules in the repository and according to the developers roadmap 6.
According to Sigrid 3 Spyder has overall maintainability score of 2.7. This measure is an average of different metrics used by Sigrid (Duplication, Unit Complexity, Component Independence, etc.). Spyder scores well in Volume, Duplication and Component Balance. This is expected as the developers properly distributed the architecture of the software into different modules and they are evenly developed. Since the code is also properly commented it makes the development cycle for the new developers easier.
However, Spyder is not well designed architecturally considering component independence and component entanglement as it scores less than 1.5 in Sigrid analysis. The main reason is there are lots of cyclic dependencies between the main modules of the architecture such as Editor, Code Completion and other modules which can be seen in the Figure below.
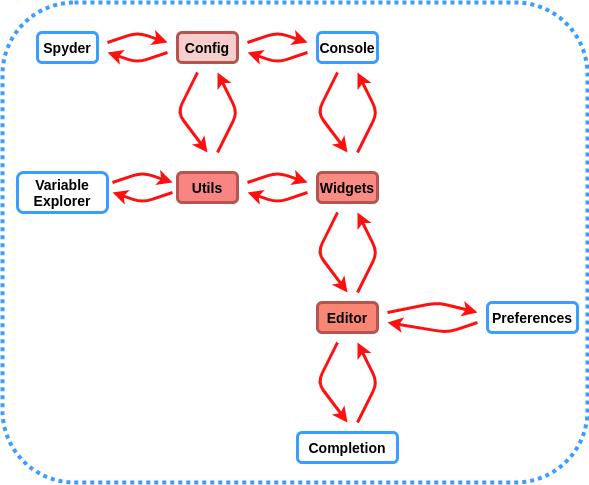
In this Figure the red modules with more red opacity (Editor, Widgets, Utils) has more cyclic dependency and they are harder to maintain. Therefore it will be a good improvement point for team Spyder to decouple these modules. These modules are described more in details in the previous posts.
Recent coding activity
The last major release of Spyder was Version 4.0.0 which was released on 06/12/2019. It includes changes like dark theme for entire interface, a new plots pane to browse all inline figures of IPython console etc.(See full list). The main architectural elements that were modified were : Editor, Main window, IPython console, Debugger, Variable explorer, Files, and Preferences.
Spyder released three more versions (v4.0.1, v4.1.0, v4.1.1), with the most recent version being released on 18/03/2020. If we take a look at the CHANGELOG.md file, it becomes clear that the major changes have been made to the Editor, Main window, Plots, and IPython console. The code for these components can be considered as “hotspots” because they’ve had much more activity in the previous releases. To obtain a more concrete claim on hotspots, we list the files based on the number of commits they have based on git commit logs (since 4.0.0)1 :
1
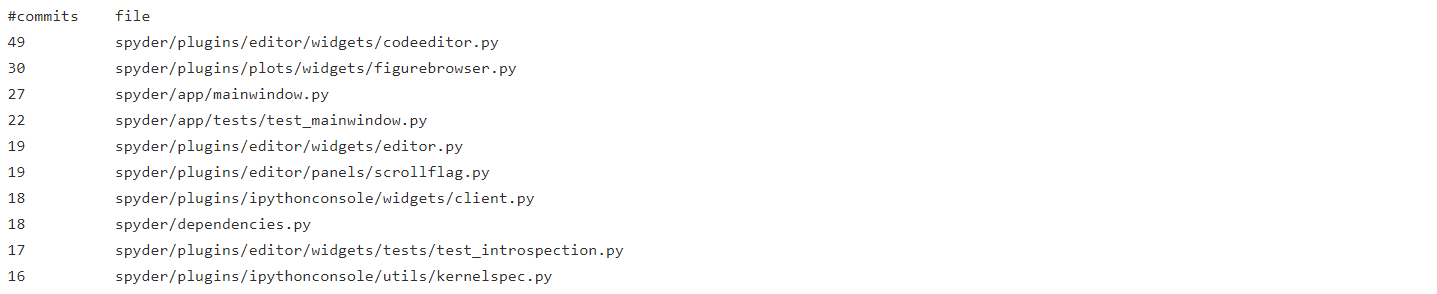
It is evident that the highest number of commits(87 excluding tests) have been made in spyder/plugins/editor folder, followed by
spyder/plugins/ipythonconsole (34), spyder/plugins/plots(30) and spyder/app/mainwindow.py(27).
Architectural roadmap
In this section we discuss if the current architecture is indeed ready for this roadmap. We’ve already seen in essay 1 the future roadmap of Spyder. The main focus for the Spyder team is to work on Spyder 5 and the tentative features that would be worked on are:
- Python 3 only support
- New “Viewer” pane to display HTML content
- docrepr integration
- A Problems pane
We saw the development and deployment views in detail in essay 2. In the development view, we looked into the system decomposition of Spyder. The components in the system are defined independently in itself and still connect together into forming a coherent application (namely Spyder). This is why these components are quite modular and changes can be made individually to them. For example, a new viewer pane and the problems pane can be implemented into the Editor plugin without worrying to much about its dependencies with other plugins. Similarly docrepr can be integrated as a third party plugin to Spyder. For Python 3 support, Spyder can make use of Anaconda distribution that now ships with Python 3.
All in all, we can say that the current architecture of Spyder can very well support the inclusion of the tentative features that the Spyder team are currently working on.
Technical Debt and Code Quality Analysis
We think team Spyder did a pretty good job regarding technical debt and how they designed the architecture of the system. The reason why adding new features are easy is due to the use of API based system and the widgets that the user can just write and add it to the editor.
The Azure CI pipeline as discussed in the first section is used to run checks on the PR to see if there is any error. If it passes all the checks, then for the new features and bug fixes the head maintainer of the project Carlos Cordoba is responsible for the first look into the pull request and assigning it to a reviewer. Afterwards, if it passes the requirements it will be merged to the master branch. Which means they take into account the quality of the code written and how well it is documented. Also some of the developers always take time to comment on the issues and help contributers with better quality solutions as can be seen here.
The maintainers also now use the Crowdin platform which makes adding new languages to Spyder easier through crowd sourcing. A chart of activity for adding new languages can be seen below.
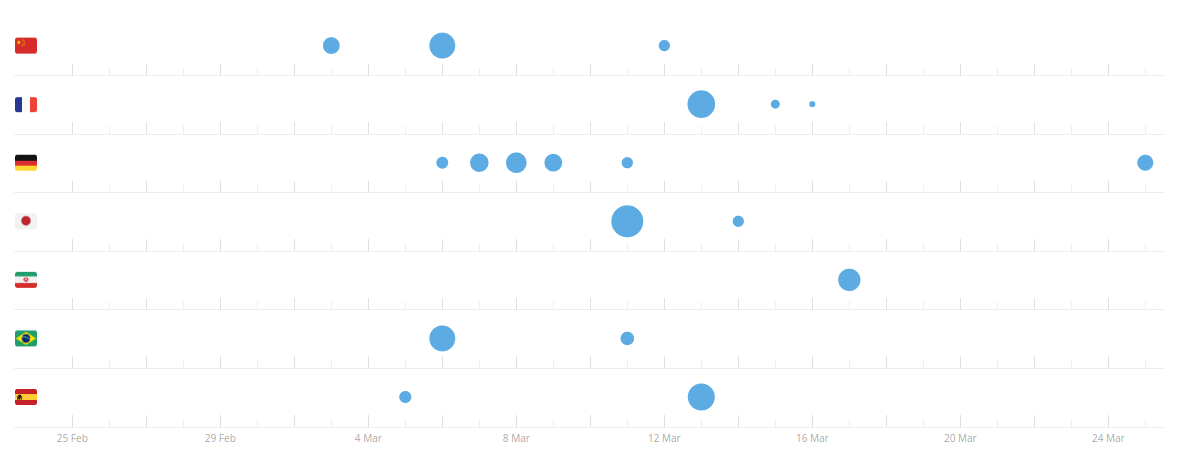
As explained by the maintainers they will add the language once it reaches 98% completion. If there are enough contributers, a vote is taken to see how good the translation is. As can be seen in this link, this is the case for French that has proofreading activity.
Refactoring Candidates
Overall, Spyder does not receive good scores from the Sigrid assessment system. Spyder lacks in 6 of the 7 criteria; unit size (2.0), unit complexity (2.2), unit interfacing (2.0), module coupling (2.2), component independence (1.3), component entanglement (1.4). The one criteria Spyder does well in is code duplication. Below we discuss the main 2 refactoring candidates we feel are more realistic to be able to change.
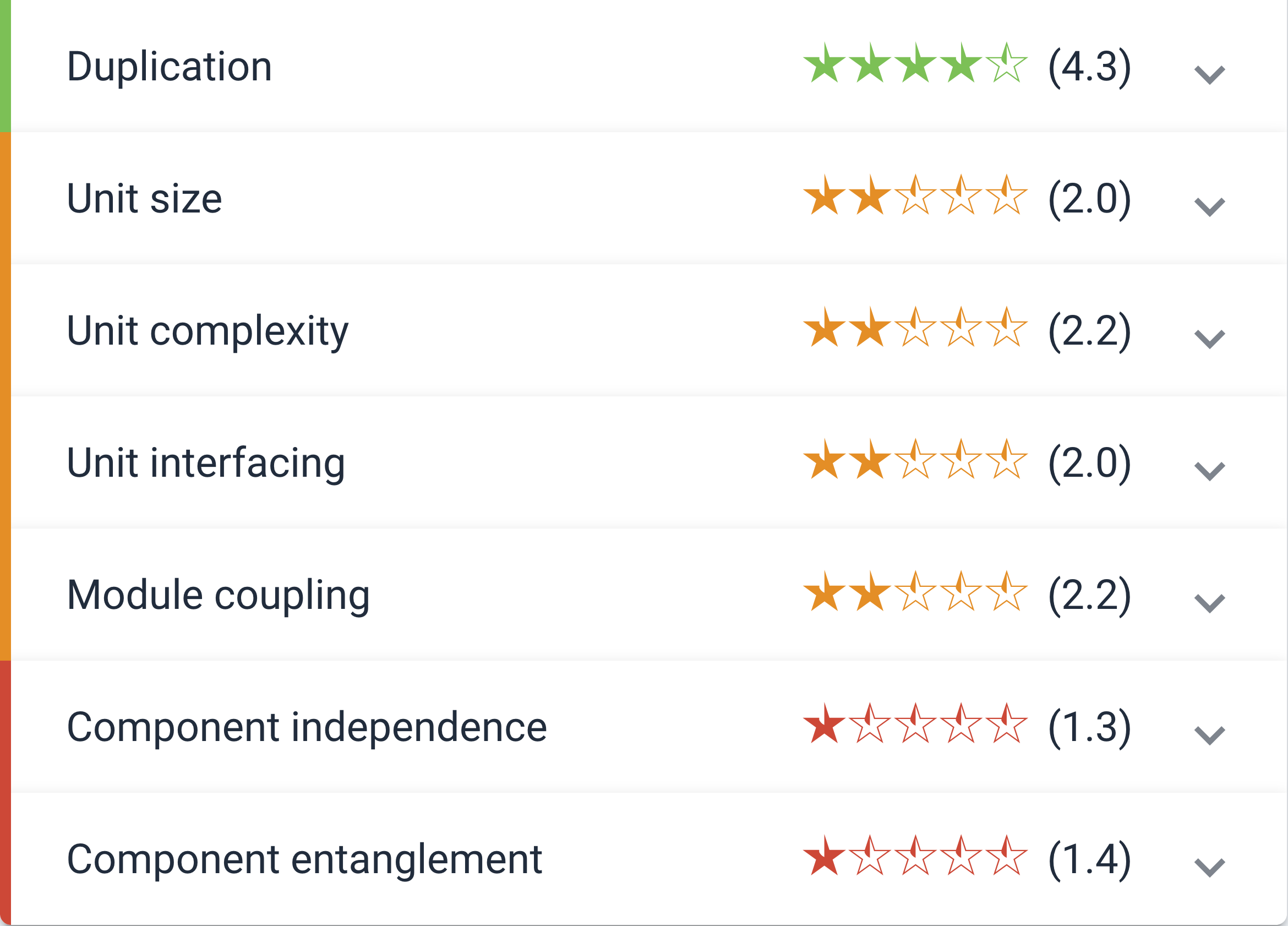
Unit Size
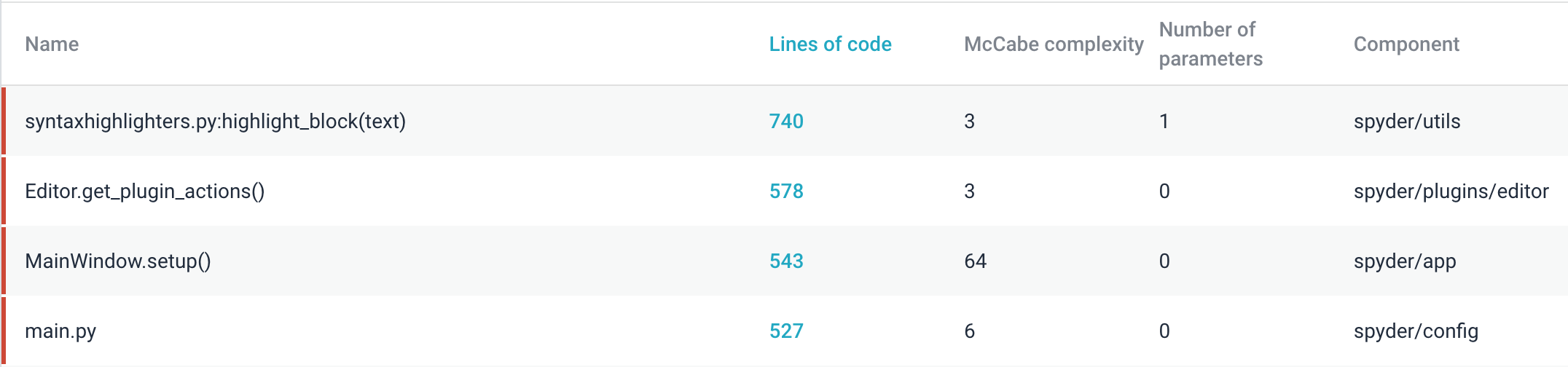
Unit size is a measure of the software’s maintainability. More specifically, the unit size is the size of single functions or methods. Having a low unit size score means that there are functions that have many lines of code 3. The worst offending function discovered by Sigrid is “highlight_block” within spyder/utils with 740 lines of code as seen below. This function highlights the different coding languages, e.g. Cython, C/C++, Fortran just to name the first 3. There are 11 totally different languages highlighted in this function which is why this function is so large. To minimize the unit size of this function, each language could be split into its own function. Other functions like main.py which has 527 lines of code are large because it contains the configuration of the program.
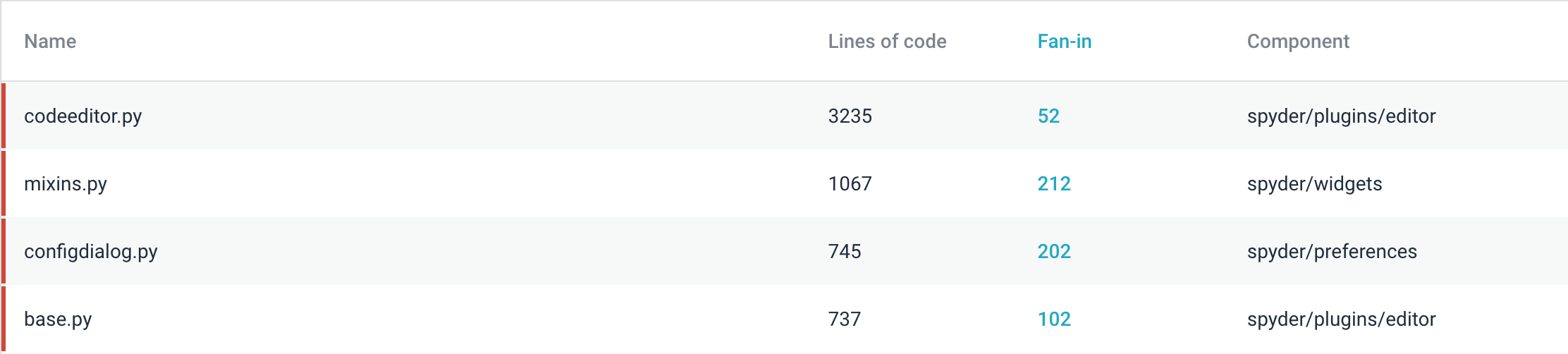
Module Coupling
Module coupling is the measure of the interdependence of one module to another. Modules should have low coupling to minimize the “ripple effect” where changes in one module create errors in other modules 7. Additionally, modules with low coupling are easier to test, change and evaluate. As seen in the image below, most of these modules that are highly coupled are a consequence of the architecture of Spyder. As discussed in the second essay, Spyder is built on a “plugin” architecture where all the main components such as the editor, variable explorer, and profiler to name a few are separate plugins. These plugins are built from “widgets”. As seen in the image below, the top refactoring candidates are from these modules.
Spyder also faces issues with component entanglement of modules, unit interfacing and component independence and entanglement. These issues as mentioned in module coupling are a consquence of the architecture and therefore we believe they are not realistic refactoring candidates.
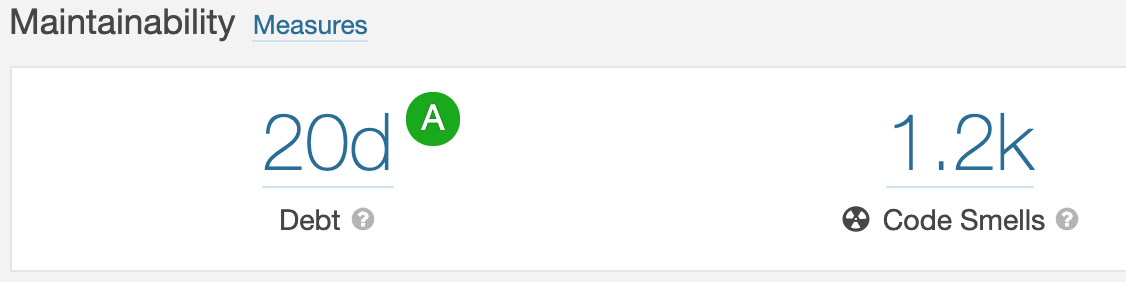
Assessment of Technical Debt
Technical debt refers to the extra development costs for rewriting code that is confusing or difficult to maintain, i.e. code smells. As seen in the image below, Spyder receives a score of “A” for maintainability. It would take approximately 20 days according to Sonarqube to re-factor the code smells. A score of “A” translates to a technical debt ratio of less that 5%. A majority of these code smells comes from one math extension that contains all the syntax rules (339 lines of confusing code) which makes sense as its all symbols.
-
https://github.com/spyder-ide/spyder/wiki/Roadmap ↩