During the previous chapter we discussed what TensorFlow aims to achieve as a product both in its present and future context. As we have seen, this ambitious project tries to suit different use cases with a high degree of flexibility and efficiency making for a not so trivial objective. To realize such a vision, TensorFlow just like any other major project requires a solid foundation supporting all of the smaller building blocks. In this chapter we will focus on how these goals are made possible through means of proper architectural components and the interconnections between them. First, let’s see what kind of different perspectives there are on architecture and how they relate to TensorFlow.
The different Viewpoints of TensorFlow
In their book1 and on their website2 Rozanski and Woods define a set of architectural viewpoints which encompass the different perspectives. Architectural viewpoints provide a framework which captures reusable knowledge to guide architects when designing their application. Essentially, it provides designers with a starting point that suggests from which directions they should approach their project. Now that we have an idea of what these viewpoints entail we can assess how they are applied in the context of TensorFlow and see which viewpoints are more relevant than others. Viewpoints for information systems(IR) will not be discussed, as TensorFlow functions mainly as ML algorithm training and testing platform rather than a data manipulating software.
Context viewpoint
TensorFlow is used by many and developed by many. The context viewpoint provides useful information about where and how the application is used. This certainly is an important viewpoint, but for a developer, other viewpoints might be more important. Many details a developer would need are more likely to featured in the development viewpoint or deployment viewpoint. For users however, this is likely a critical viewpoint as the number of agents involved in TensorFlow demonstrates it’s capabilities.
Functional/Runtime viewpoint
According to 3, the functional viewpoint defines the key components which carry out the main functions of a system and their interactions. This is very similar to how the runtime view is defined in 4. It is usually easily understood by stakeholders and regarded as a cornerstone of an architectural description. Thus, the functional/runtime viewpoint is suitable to give people insights into TensorFlow.
Development viewpoint
TensorFlow is an complex application with many functionalities including several APIs and compatible third-party applications. The application is constantly in motion and under development with many competitors in the field. The development viewpoint is perhaps most crucial to TensorFlow and its developers.
Deployment viewpoint
Being a complex application, TensorFlow deployment also becomes an involved process. The many different options of how and where to deploy the application add to the complexity of this viewpoint and necessitate a clear deployment strategy.
Operational viewpoint
Since TensorFlow is a popular open source library it is constantly undergoing changes and updates. Therefore, it is important to systematically handle the constant flow of contributions and deployment of updates.
Architectural Style: The different Layers of TensorFlow
After having discussed the architectural viewpoints we now turn to the architectural style which expresses a structural organization schema for software systems. TensorFlow makes use of a layered architecture. It consists of many layers which built on top of each other and request and provide services to and from other layers5. The following diagram presents a high level overview of the layer structure for TensorFlow.
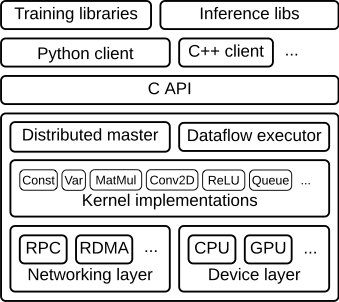
As can be seen from the image, TensorFlow’s top most layer consists of multiple libraries for using the software which is built on top of the clients, like those for Python and C++, which define the computation as a dataflow graph and initiate graph execution using a session.
Next is the API layer which contains the C API. This is built on the Distributed master layer, as well as the dataflow executer. The Distributed master layer prunes a specific subgraph from the graph, partitions the subgraph into multiple pieces that run in different processes and devices, distributes the graph pieces to worker services and initiates graph piece execution by worker services.
Next are the Kernel Implementations, which perform the computation for individual graph operations.
Lastly, there are the Networking and Device layers, at the lowest level of the architecture.
Development View
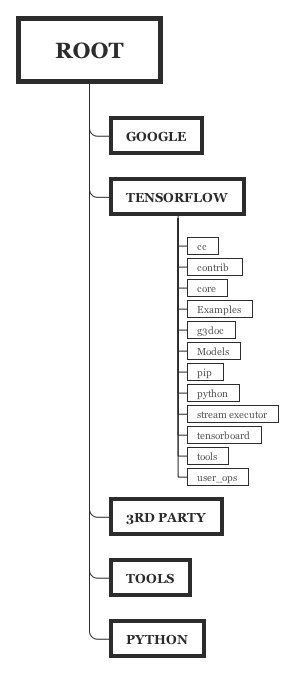
Now diving more into the actual architectural viewpoints themselves we start with the development view. The code of TensorFlow is decomposed into multiple modules contained within the TensorFlow directory. The following section will provide a brief analysis of the source code organization and the module dependencies with the help of the presented diagram.
Which folder does what?
For comparison, we have included the source code organization diagram of TensorFlow as visualized during the 2016 edition of Desosa6. While the two diagrams are quite similar, there are a few notable differences as can be seen from the image below.
| TensorFlow 2016 | TensorFlow 2020 |
|---|---|
 |
 |
The following subsections will give a very brief explanation of the contents of each sub-folder in the 2020 source code organization.
.github/ISSUE_TEMPLATE
Contains template files for different kinds of issues for submitting to GitHub. This folder was not yet present in 2016.
third_party\
Contains many different instances of third-party libraries used for TensorFlow. This folder has remained since 2016 and still serves the same purpose.
tools
Contains a script file which generates a file with system information details used to populate GitHub issue templates. This folder was also present in 2016, but the purpose of the script file seems to have changed.
tensorflow
Contains the components for the main application. The documentation for some of these folders is unclear, but the contents can be summed up roughly in the following way:
- c: Contains files for the C API for TensorFlow.
- cc: Contains files for the C++ API for TensorFlow.
- compiler: Contains several modules for compiling.
- core: Contains code making up much of the main functionality of the TensorFlow application.
- docs_src: Formerly used to contain documentation, but documentation has since been moved to its own dedicated repository.
- examples: Contains demos and examples for different platforms and tasks of how to write TensorFlow code.
- g3docs: Was also used for documentation, but is now empty.
- go: Contains files for the Go API for TensorFlow
- java: Contains files for the Java API for TensorFlow
- js: Contains files for JavaScript code generation.
- lite: Contains modules for TensorFlow Lite, the lightweight version of TensorFlow aimed for android and embedded devices.
- python: Contains files for the Python API for TensorFlow.
- security: Contains security advisories for using TensorFlow.
- stream_executor: Contains the GPU executor library.
- tools: Contains various tools, such as a benchmarking tool and a tool for running all important builds and tests.
Module dependencies
In order to find the module dependencies, we looked in the document ion and used the architecture visualization provided by Sigrid. A high level overview of the dependencies are shown in the diagram below.

Run Time View: How do TensorFlow components work together?
In this runtime view, we made a brief description of runtime between the components of TensorFlow, including compiler, stream executor, core engine and API for other languages.
Tensoflow uses a data flow programming model. Specifically, to run a machine learning task, users need to first build a graph whose nodes indicate TensorFlow operations and edges indicate tensors. An example graph is shown in figure below. 7 Users can construct and execute a graph by APIs available in 6 languages. Noted that they are all running based on the core engine. Then, a typical work loop is running in which TensorFlow finds a node ready to execute in the graph, run it and repeat these two steps until the nodes are all executed.

The interaction of TensorFlow components in this workflow is shown in figure below8. When users hand in a graph, based on whether it is required to run in a distributed way, the compiler will assemble the codes into cpu/gpu/tpu expression and then send them into stream executor.
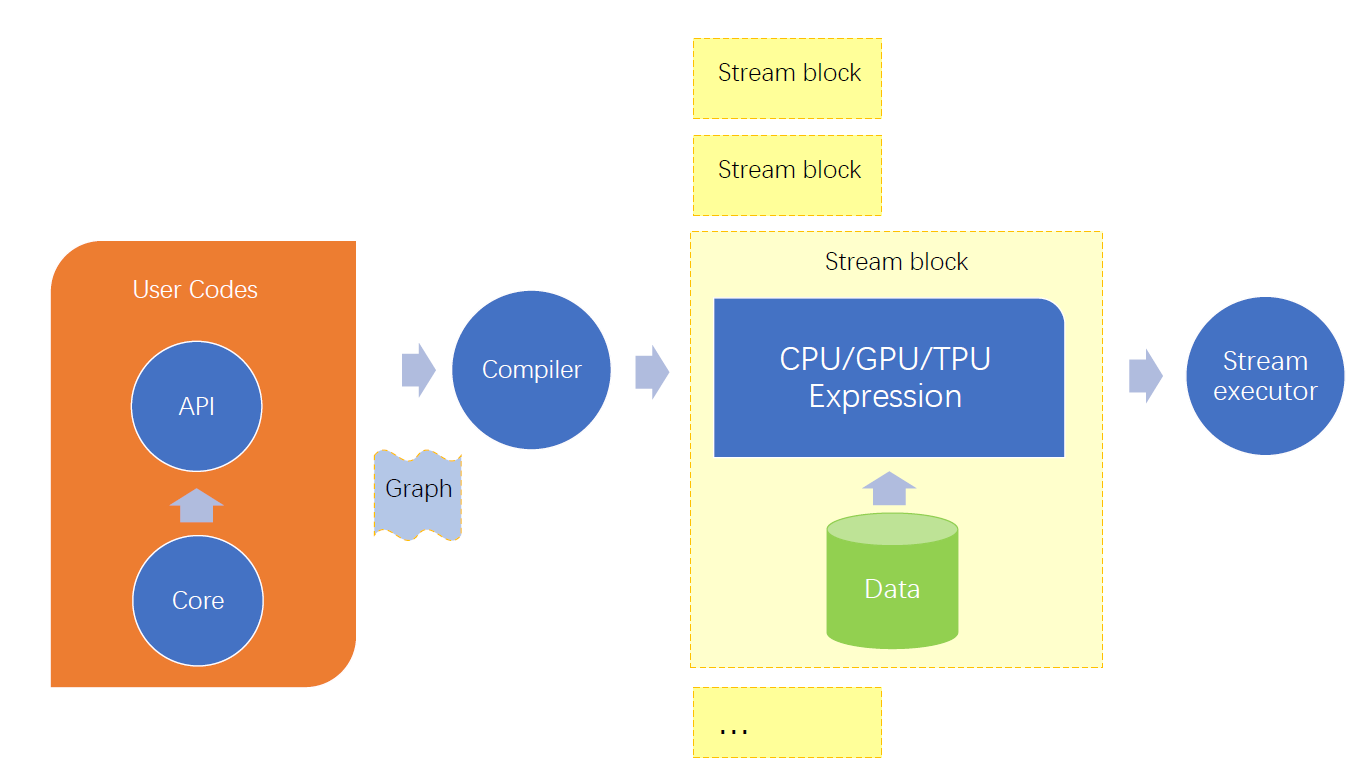
Deployment View: How to get up and running
After software has been developed and tested the next step is for it to be deployed onto the end user machines. TensorFlow provides several ways for deployment to end users as mentioned in section 3.1 of the Desosa 2016 edition.6 Installing through pip is the easiest method and allow users to deploy the TensorFlow on their computer with a single command. Alternatively, the docker container method can be useful for GPU support as it provides an image with all the required GPU libraries pre-installed. The third option is to clone the repository and build the system from source using the build tool Bazel. While this approach takes more work, it is the only way to gain access to the C++ API and gives the user more control over the final software configuration. TensorFlow offers both a ‘stable’ distribution as well as a ‘nightly’ build. The nightly build is created daily from the master branch and includes the latest changes including the latest new features. The stable version is released far less often making it more reliable.
Hardware requirements
According to Rozanski and Woods1, the deployment view also defines which hardware components are required for the system to run. TensorFlow requires either a CPU, GPU or TPU in order to perform its main functionalities in addition to standard general-purpose hardware. However, in the case of GPU it only supports NVIDIA® GPU cards with CUDA Compute Capability 3.5 or higher. Additionally, operating TensorFlow with the help of GPUs requires some additional software packages:
- NVIDIA® GPU drivers - CUDA 10.1
- CUDA® Toolkit 10.1
- cuDNN SDK 7.6 or higher.
In the case of TPU things work a little different. Currently TensorFlow provides experimental support for Keras with Cloud TPUs owned by Google. The user uploads their model through the provided API after which it is executed on the specialized hardware and returns the results.
Third-Party software requirements
After having sorted out the hardware there are also many third-party software dependencies that TensorFlow relies on. Below we list the important dependencies for the current major version of TensorFlow (2.x):
First, with respect to the operating system TensorFlow requires one of the following options9:
| Operating System | Version |
|---|---|
| Ubuntu | >= 16.04 |
| Windows | >= 7 |
| macOS | >= 10.12.6 (Sierra)+ (no GPU support) |
| Raspbian | 9.0 |
In addition, the following software components are needed to cover certain aspects10:
| Software | Version | Description |
|---|---|---|
| Python | 3.5–3.7 | The fundamental base that supports all of the Python packages |
| NumPy | >= 1.16.0 - 2.0 | Provides support for large multi-dimensional arrays and associated operations |
| Six | >= 1.12.0 | Provides compatibility between the Python 2 and Python 3 library |
| Wheel | >= 0.26 | A built-package format for python to pack and unpack files |
| Mock | >= 2.0.0 | Provides support for testing parts of the system using ‘mock’ objects |
Non-Functional Properties and Trade-offs
So far in this chapter we have mostly observed TensorFlow from a very technical perspective where every element has a dedicated function. But TensorFlow is more than just a collection of functions to perform machine learning tasks. Other than the technical properties there exist non-functional properties which are more abstract yet still contribute significantly to the meaningfulness of the system. When it comes to TensorFlow, the following topics and their trade-offs come to mind:
- Open-source vs Supportability : TensorFlow is an open-source project giving public permission to codes and design documentation. Furthermore, it encourages the developer community to maintain and contribute to the project. This property boosts the development in project and application, but also brings trouble for management. Currently they have built several special groups in charge of contributions in total, this would increase the communication cost but lead to a systematic contribution and better supportability.
- Adaptability vs Stability: To adapt to a diverse programming language environment, TensorFlow is currently maintaining and building API for at least 12 programming languages. In this way, TensorFlow can take advantage of the variety of different languages. However, there are not enough developers so the stability of those APIs can not be guaranteed. Currently, the only API of python is promised stabilized. 11
- Extensibility vs Security : TensorFlow can build dependencies easily on third party libraries such as NumPy, PNG parsers, however, with the cost of several security issues. Extending more libraries also means more vulnerabilities from these included libraries which could trigger unexpected or dangerous behavior with specially crafted inputs.12
-
Nick Rozanski and Eoin Woods. Software Systems Architecture: Working with Stakeholders Using Viewpoints and Perspectives. Addison-Wesley, 2012, 2nd edition. ↩ ↩2
-
https://www.viewpoints-and-perspectives.info/home/viewpoints/ ↩
-
Software System Architecture, the functional viewpoint, last accessed 2020/3/17 https://www.viewpoints-and-perspectives.info/home/viewpoints/functional-viewpoint/ ↩
-
arc42 Runtime view, last accessed 2020/3/17 https://docs.arc42.org/section-6/ ↩
-
Lamberta, Billy. “Tensorflow/Docs.” GitHub, 8 Jan. 2020, github.com/tensorflow/docs/blob/master/site/en/r1/guide/extend/architecture.md. ↩
-
Carmen Chan-Zheng et al, Desosa 2016: TensorFlow, https://delftswa.gitbooks.io/desosa2016/content/tensorflow/chapter.html ↩ ↩2
-
TensorFlow example, last accessed 2020/3/15https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/tensorflow.html ↩
-
Runtime view of TensorFlow, Lingyun Gao ↩
-
TensorFlow official installation guide web page https://www.tensorflow.org/install ↩
-
TensorFlow pip setup file https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/pip_package/setup.py ↩
-
TensorFlow API, last accessed 2020/3/19 https://www.tensorflow.org/api_docs ↩
-
TensorFlow security https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md ↩