As we have seen earlier, TensorFlow is a project of substantial size both in terms of codebase as well as the community surrounding it. With so many people working on such a large application it becomes very hard for anyone to carry a complete view of the entire system in their mind. Developers working on certain semi-isolated parts of the software might introduce modifications that unknowingly impact functionalities elsewhere in the system leading to bugs or even failures. Maintaining a high level of quality becomes an undeniable challenge itself, especially for an open-source project involving countless different contributors. This article will provide you with some insight as to which maintenance methods and tools are being employed by the TensorFlow team to keep their project healthy.
Overview of software quality management: What is it like to be a contributor in Tensorflow?
Assuming you have gained some insights of what Tensorflow is and how Tensorflow works, now it’s time to contribute! Tensorflow follows a Github-centered software quality management and asks for the involvement of all contributors, developers, and maintainers.1 If you are a code contributor, before your contribution, you are required to have a Github account, sign in certain agreements and communicate actively with other developers to avoid duplicating efforts. Next, A high-quality unit test for checking the validity of the code and adequate testing are required. You can always find a detailed test procedure in the documentation of each subproject. Then, when your codes and tests are ready, you are asked to open a Pull Request (PR), and maintainers and other contributors will review this PR and your code. Finally, if your PR was proved, you might get a medal for your contribution!
As a contributor, you must learn and think before your actions! Sections below will offer you more details of testing and also provide some ideas of what you could dig into and avoid when you start a new contribution. Have fun!
Compulsive Tests: CI and Sanity Check
All pull requests (PR) must pass the sanity check and TensorFlow unit tests. 2A sanity check is to catch potential issues of license, coding style, and BUILD files, while unit tests are to guarantee that your PR does not destroy TensorFlow (too much). Unit tests can be done locally, but usually, new changes will be asked to go through TensorFlow Continuous Integration (CI), in which you can trigger builds and tests of your PR performed on either Jenkins or a CI system internal to Google.
To be more specific, CI test is a fixed processed testing for each new contribution of Tensorflow. It contains the test and checks as following3:
- Build TensorFlow (GPU version)
- Run TensorFlow tests:
- TF CNN benchmarks (TensorFlow 1.13 and less)
- TF models
- (TensorFlow 2.0): ResNet, synthetic data, NCCL, multi_worker_mirrored distributed strategy
In addition, the configuration test is not exactly mentioned in the documents. This is probably caused by too many platforms used for Tensorflow and the configuration test is also partly included in the CI test. Thus we will not discuss it in this essay.
Test Coverage
As previously said, tests are an important part when contributing to the Tensorflow repository, and are mainly necessary in two cases4. The first case is when a new feature is added, proving that the feature will not lead to future breakdown. The second case is when fixing bugs, since the existence of the bug most likely means that the testing was insufficient in the first place. This process likely assures good test coverage, and in combination with above mentioned CI processes and sanity checks, this is how TensorFlow continues to be stable despite the size of the project and the many contributors. According to Sigrid, the test code ratio is 24.3%.
Looking around in the repository of TensorFlow 5, test files are usually placed in the same folder as the files they are supposed to test. A common pattern, for example in the case of C++ files, is to have a file for testing named X_test.cc if there is a file named X.cc in that folder. For files written in Python, doctests are used.
Coding Hotspots
With a project of this size, it is interesting to see where developers are actually making contributions. Does the TensorFlow repository have any “hotspots”? A hotspot could be defined as a part of your code base that is more complicated than the rest. Therefore, it requires more attention and results in a lot of time spent at that particular part6. To find any hotspots in the TensorFlow repository, we used CodeScene7, which generated the hotspot map over code activity seen in the figure below.
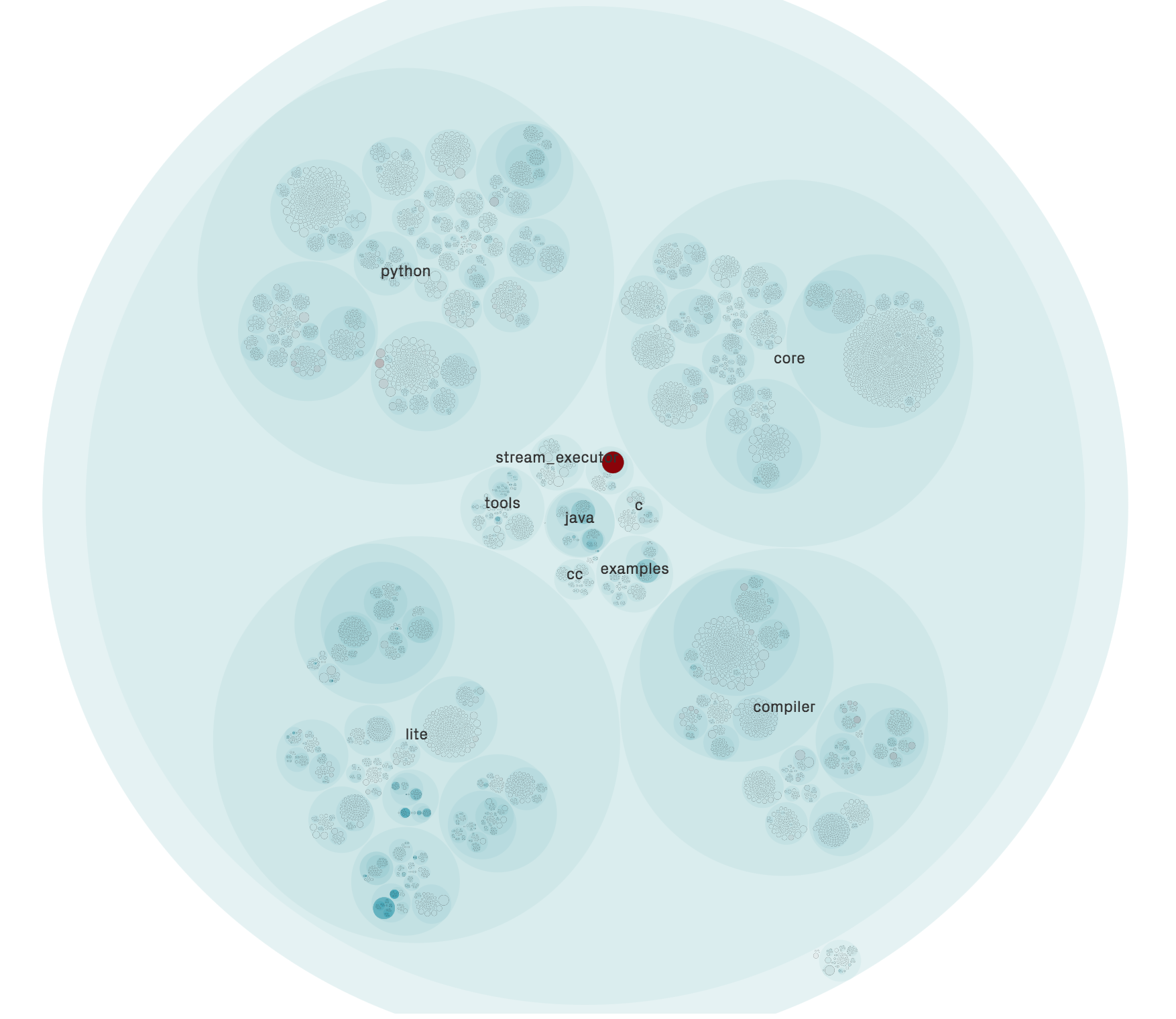
Figure: Hotspot map for TensorFlow
The figure shows the contents of the folder “tensorflow” in the TensorFlow repository (see Embedding Vision into Architecture for more details on the folder structure). The lack of red dots in the image is an indication of that Tensorflow almost completely lacks hotspots. One file, wrappers.go in the folder for the Go API, is clearly marked red by CodeScene. Looking into the history of that file, we can see that this file has received several updates per day by the tensorflow-gardener bot, see image below.
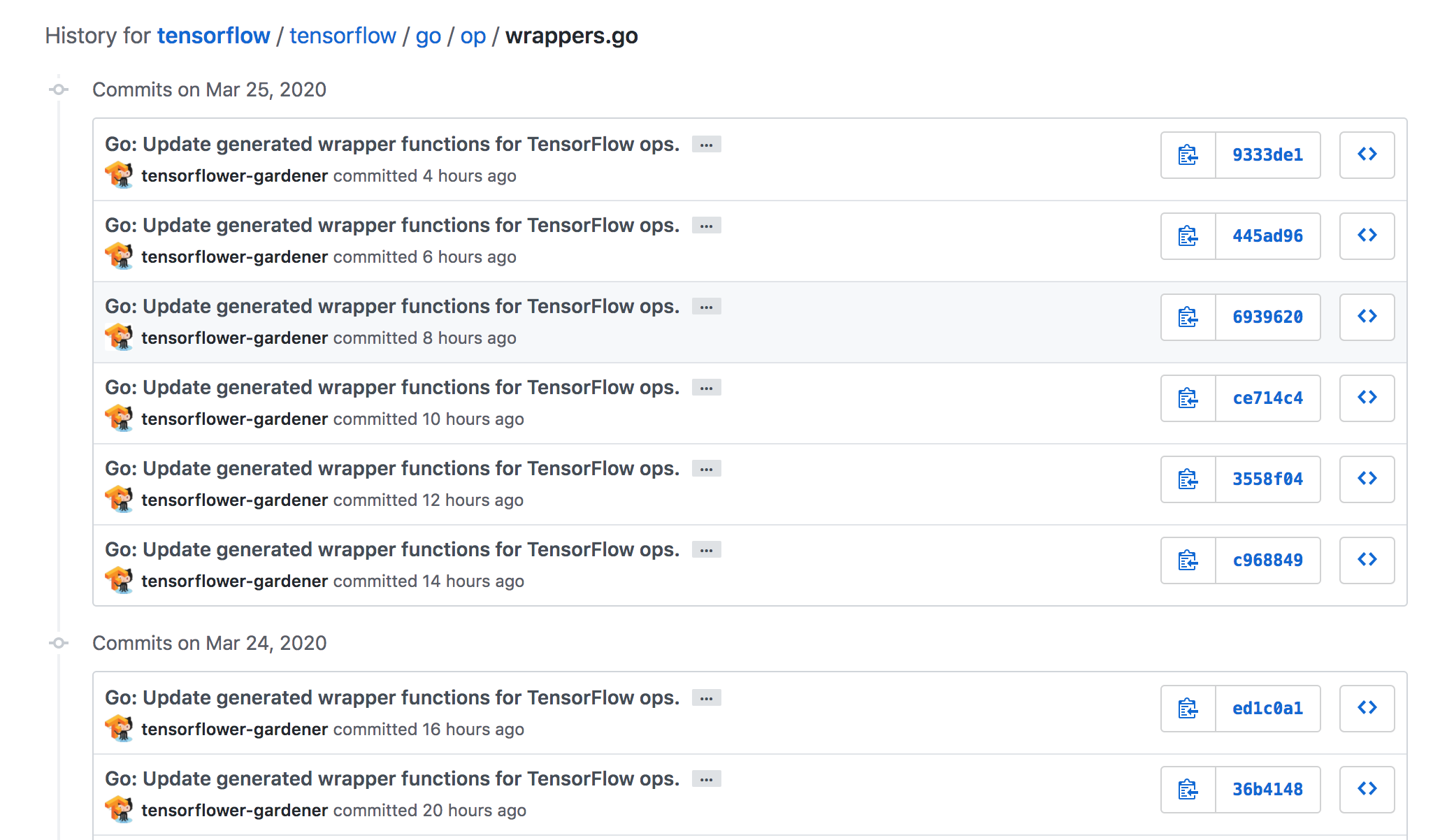
Figure: History for the file `wrappers.go`
The updates the bot is making seem to only be to remove and add spaces in comments at the same places over and over again. It is definitely questionable if this behavior is really intended.
There are a few files in the python/ops folder that have been given a slight hint of red. Taking an example, one of these files is maps_ops.py. It contains mathematical functions, many of them simple and probably well used, for example abs() and argmax(). Looking into the history of this file, about 40 commits have been made since the beginning of 2020. Most of these are just updates to comments and docstrings. This does not look like a severe issue and should probably not be considered a hotspot.
Where will the code for the Roadmap 2020 be written?
As seen in our post TensorFlow: making machine learning manageable, much of the future development of TensorFlow is centered around usability. As we can see several APIs mentioned here, we can assume that these additions will happen in the respective module for that API. The roadmap also mentions updates to performance. These additions can be assumed to happen in both the compiler module and the core module.
Quantity and, hopefully, quality
Even if testing and continious integration processes are good, contributing would be very difficult if the code didn’t live up to a certain quality. However, maintaining quality code in a system such as TensorFlow is doubtless a Sisyphean task. Simply looking at the dependency graph provided by SIG shows an enormous, tangled web of hundreds of components with thousands of dependencies and interconnections, each with up to tens of thousands of lines of code.8 Given this, it is no surprise that the code quality can tend to suffer at times.
Firstly, there are so many dependencies that one can hardly begin to understand the effect that one small change to a component will have, and as such, there are many components with very low scores for modularity. The issue with this, at this scale when you make a change to code, not only will you be affecting countless other components, but it will also mean that you now must test many component interactions along with the component itself. This all contributes to the hundreds of man-months put into TensorFlow. Finally we question the quality of those components most likely affected by future change.
As we have mentioned previously, size and dependency are massive burdens to quality, especially in how they link so many components. Many core features, for example the core framework, have low quality scores and will be largely affected by future change. However, the interconnectedness of the component, and of all of the central components of TensorFlow mean that even if these components had better technical quality, it will still be impacted by those components upon which they rely. Therefore it is inevitable that as architectural changes are made to TensorFlow in the future, the ripple effects this will have mean that it will be necessary to redesign or refactor huge amounts of the codebase.
Sigrid attributes to TensorFlow thousands of maintainability violations, especially those pertaining to duplication. This is because with a technology as big and with as many contributors as TensorFlow, it can be difficult to coordinate everyone’s knowledge and prior work on the software, so oftentimes the code is written somewhat inefficiently. The nature of these violations are closely tied to the properties which SIG suggests be refactored, and in doing so, the maintainability will be much improved.
Refactoring suggestions, the bad and the less bad
SIG also offered some ways that TensorFlow could be refactored8. They describe several areas in which the system could be refactored to provide clarity to the code, make it easier to read, and to improve certain qualities of the code.
| Refactorable System Property | Reason | SIG Code Quality |
|---|---|---|
| Duplication | Writing code once makes it easier to edit and reuse. | 2.4 |
| Unit size | Smaller units typically have a single responsibility and are easier to change without affecting other components. | 1.7 |
| Unit complexity | Simple units are easier to understand and test. | 2.3 |
| Unit interfacing | Smaller, simpler interfaces are easier to modify and easier to make error free. | 0.9 |
| Module coupling | Modules that are loosely coupled are easier to analyze, test, and modify. | 2.4 |
| Component independence | Independent components make for easier system maintenance. | 2.3 |
| Component entanglement | Minimal component communication means less complex architecture. | 1.4 |
TensorFlow does not seem to score particularly high for any of the investigated factors. Moreover, it scores particularly bad with respect to Unit interfacing, Unit size and Component entanglement. In the following section we try to analyze one of the aspects which might be one of the causes for the system’s poor performance on the mentioned categories.
Technical Debt: Shedding light on the dark side of TensorFlow
Up until this point, most of the topics we have discussed focus on the objective and positive properties of TensorFlow. However, as with almost any software project of this size, eventually decisions which might be sub-optimal from a design perspective will have to be made in favor of other objectives. It is important that we consider this ‘dark side’ of TensorFlow as it can bear significant implications for future development. In this section we will discuss several negative aspects of the framework and also analyze how the community takes the technical debt into account when discussing future development.
TensorFlow was influenced by the Theano, a library available since 2007 that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Like Theano, TensorFlow originally worked by first creating a graph statically specifying the types of operations and the order in which they will be executed. After having defined your graph, the real data is fed in through the tf.Session and tf.Placeholder objects at runtime. This lack of flexibility was a big concern for researchers exploring innovative techniques, one of the main target user groups of TensorFlow. In 2018 former Google scientist Liang Huang stated on a discussion board that the strategy of static graphs akin Theano was a major design mistake which might have serious consequences for the future of TensorFlow9. An alternative is to use a more imperative approach like dynamic graphs which allow you to change and execute computation nodes ‘on the go’ at the cost of some overhead. This strategy, employed by major competitors such as PyTorch10, greatly aids in debugging as intermediate results are returned immediately providing feedback to fix or improve individual nodes.
Another important aspect of dynamic graphs is that they facilitate the use of Recurrent Neural Networks (RNN). Essentially, RNNs are neural networks with feedback loops typically implemented in code as a for-loop. The input sequence length of dynamic neural networks can vary with each iteration which was inconvenient for the TensorFlow’s static graphs with fixed input lengths10.
However, The TensorFlow team was aware of these issues and not long ago in September 2019 TensorFlow 2.0 was officially released including the promising new feature of eager execution11. Eager execution is an interface enabling dynamic graph execution and essentially move TensorFlow into the direction of PyTorch. While the new feature is stable, users have reported significant slowdowns of the execution speed of their models when switching from static to dynamic models12. According to one of the team members13 currently the eager execution mode is mostly meant for debugging purposes. However, he does promise that updates will be coming in the future which will improve the running time of the eager execution method.
As of TensorFlow 2.0 eager execution is now the default context, but can be easily disabled by calling the tf.compat.v1.disable_eager_execution() function. Also, the official guide page14 states that performance of eager execution suffers for models which involve lots of small operations and more optimization work needs to be done. In conclusion, while the team has made good efforts to liquidate some of the technical debt through the addition of eager execution, some negative effects of legacy decisions still remain and will require more work in order to be amended. Hopefully the TensorFlow team will continue to light their (Py)torches through the darker districts of TensorFlow.
-
Contribution to Github Code , last accessed in 2020/3/26 https://www.tensorflow.org/community/contribute/code ↩
-
Contributing Guidelines, last accessed in 2020/3/26 https://github.com/tensorflow/tensorflow/blob/master/CONTRIBUTING.md ↩
-
Tensorflow Builds, last accessed in 2020/3/26 https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/ci_build ↩
-
TensorFlow Github repository, Contribution guidelines and standards, https://github.com/tensorflow/tensorflow/blob/master/CONTRIBUTING.md#contribution-guidelines-and-standards ↩
-
TensorFlow Github repository, https://github.com/tensorflow/tensorflow ↩
-
CodeScene definition of a hotspot, https://codescene.io/docs/guides/technical/hotspots.html#what-is-a-hotspot ↩
-
CodeScene tool for analysing repositories https://codescene.io/ ↩
-
“Sigrid TensorFlow Analysis.” Sigrid, Software Improvement Group, 2020, www.sigrid-says.com/portfolio/tudelft. ↩ ↩2
-
Liang Huang, Former Google Scientist, https://www.quora.com/What-is-the-future-of-TensorFlow ↩
-
Kirill Dubovikov, CTO at Cinimex DataLab, https://towardsdatascience.com/pytorch-vs-tensorflow-spotting-the-difference-25c75777377b ↩ ↩2
-
TensorFlow Team, TensorFlow blog, https://blog.tensorflow.org/2019/09/tensorflow-20-is-now-available.html ↩
-
TensorFlow Issue #629: 100x slow down with eager execution in tensorflow 2.0, https://github.com/tensorflow/probability/issues/629 ↩
-
TensorFlow Issue #33487, Comment by teammember qlzh727, https://github.com/tensorflow/tensorflow/issues/33487#issuecomment-548071133 ↩
-
TensorFlow eager execution official guide page, https://www.tensorflow.org/guide/eager#benchmarks ↩